人工智能主要是机器学习,机器学习主要是深度学习,深度学习实际上算是机器学习的子领域,而要进行深度学习必然要接触人工神经网络。
神经网络是一种模拟人脑的神经网络以期能够实现类人工智能的机器学习技术。人脑中的神经网络是一个非常复杂的组织。成人的大脑中估计有1000亿个神经元之多。
1. 神经元
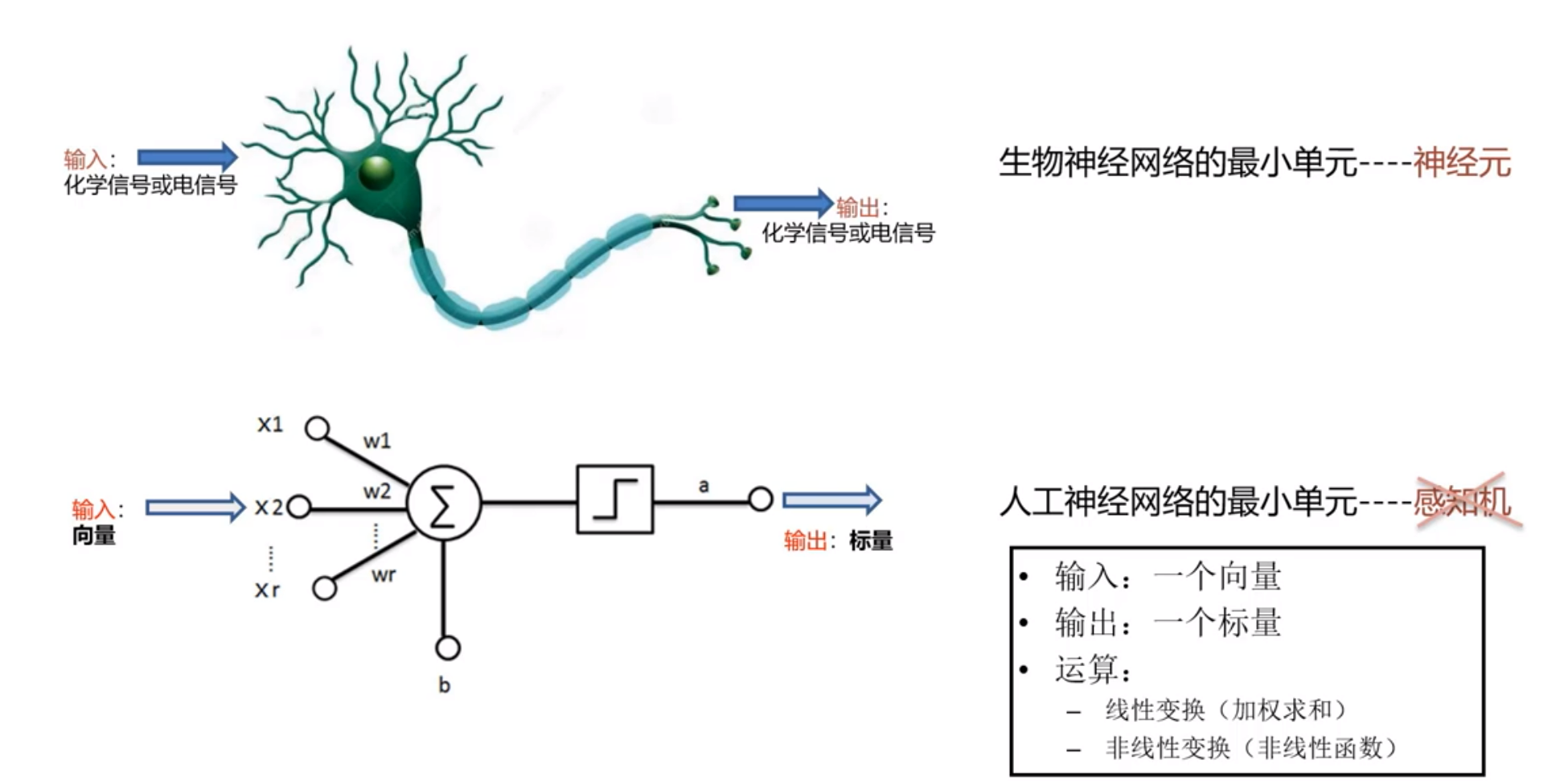
现在业界将感知机统称为人工神经元
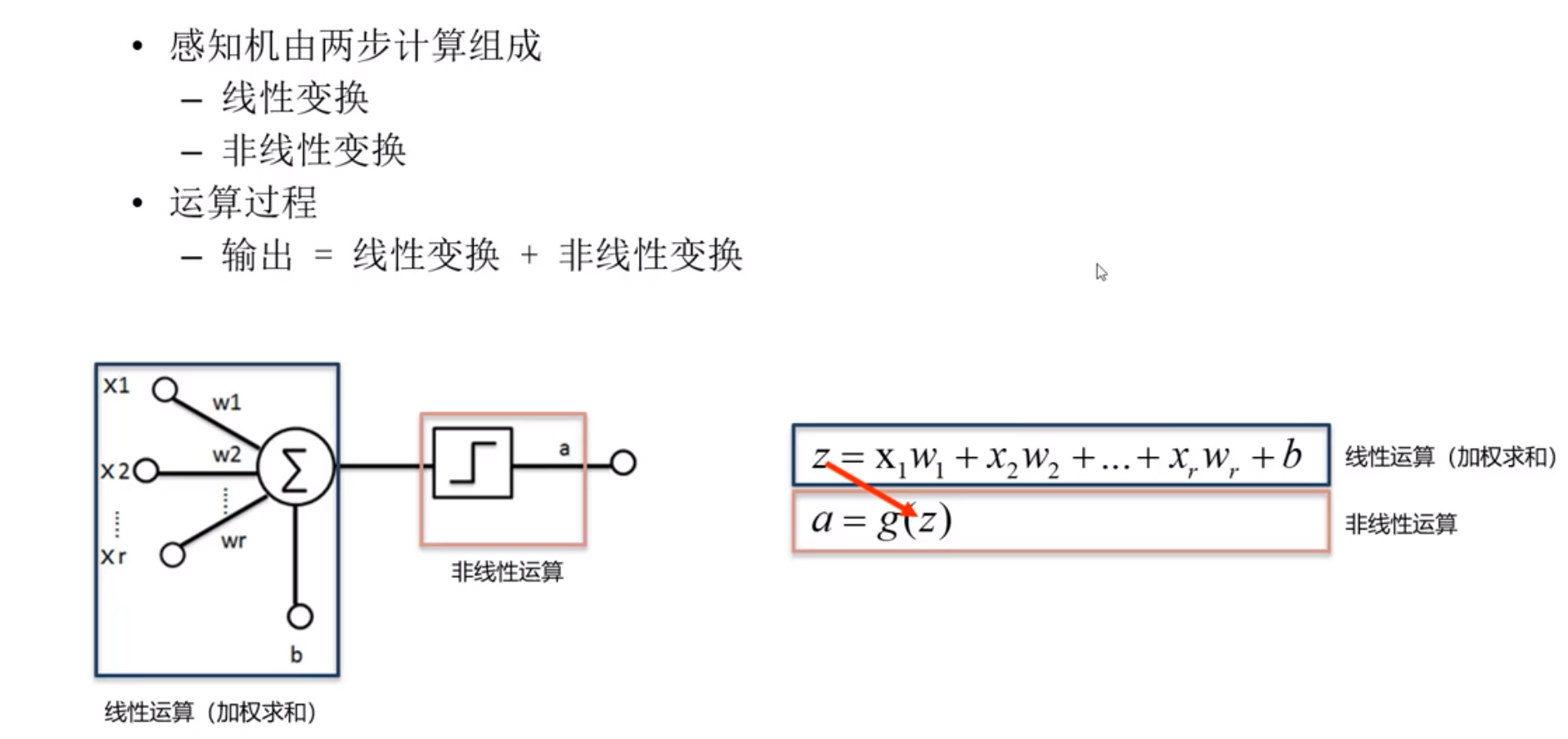
单感知机——最简单的神经网络
- 神经元是人工神经网络中的最小单元
- 单神经元是最最简单的神经网络:
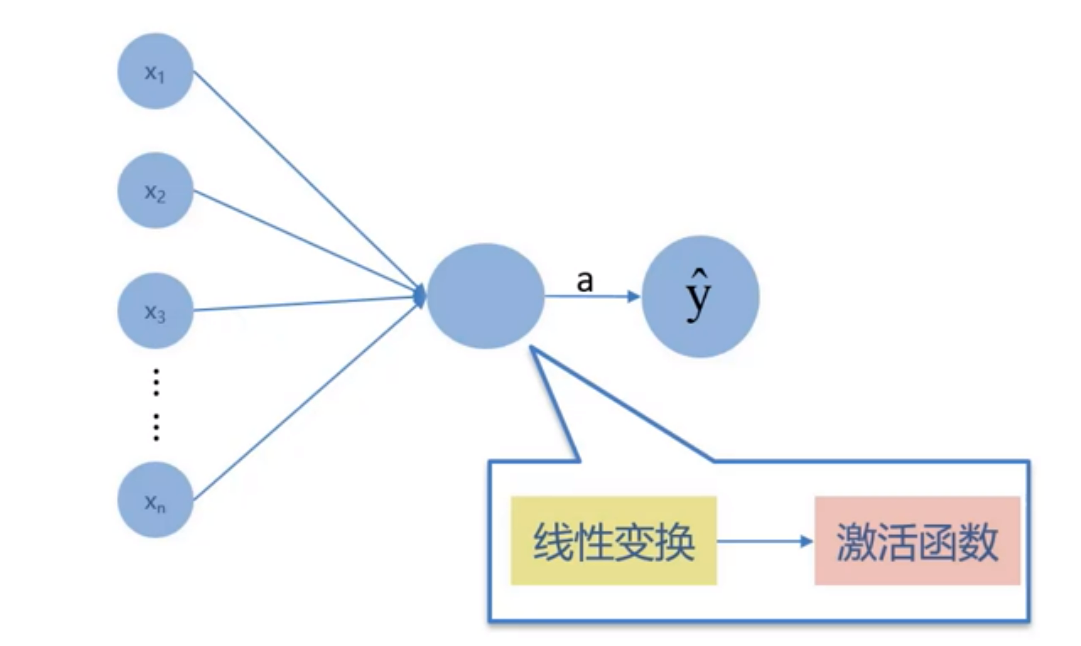
2. 深度学习系统
- 深度学习模型本质上也是一个运算过程
- 具有:输入、输出
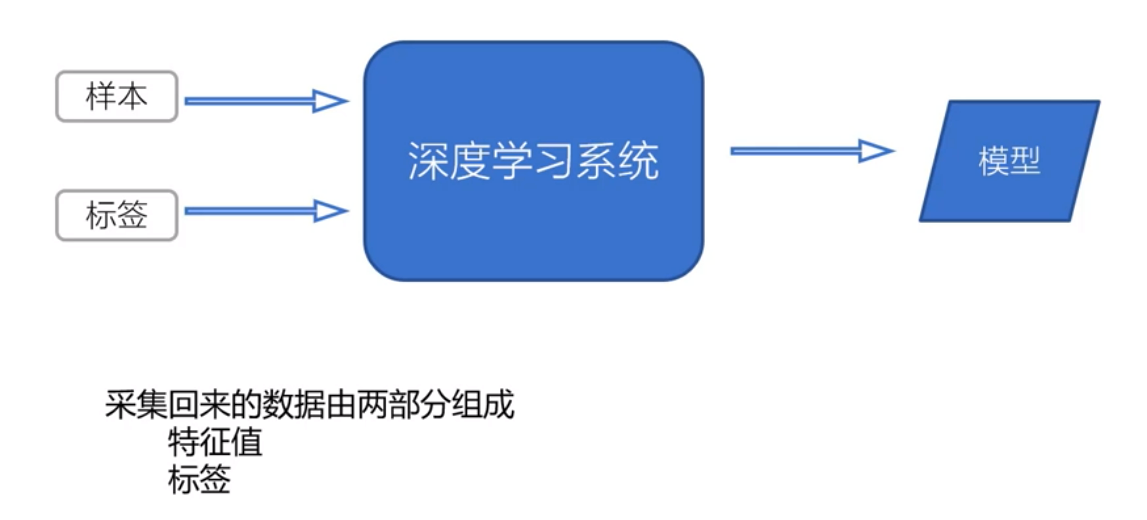
2.1 系统输入与输出——训练过程
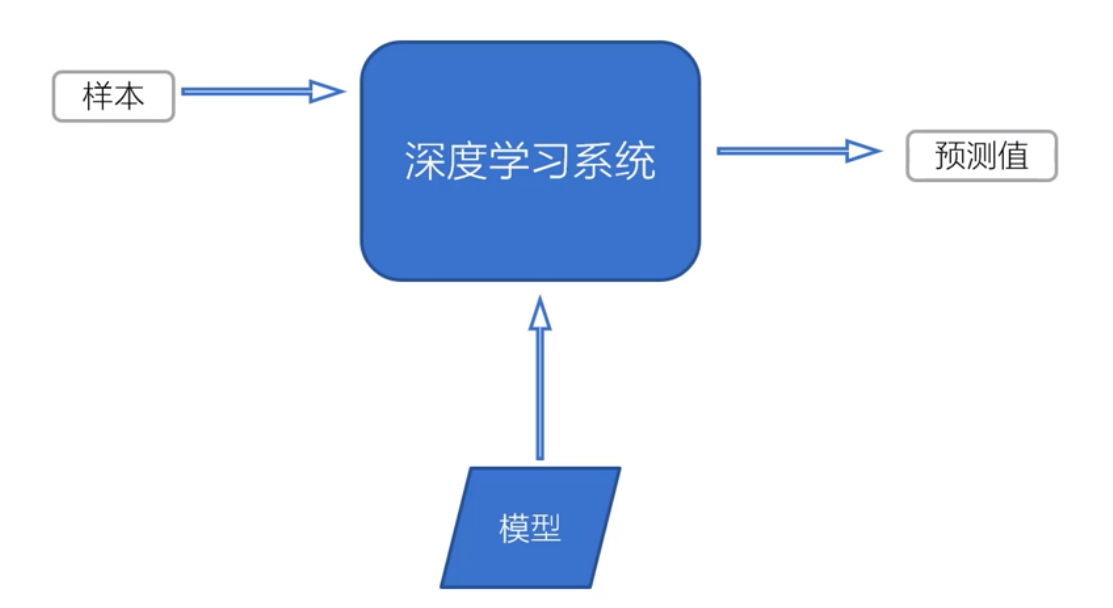
2.2 系统输入与输出——预测过程
3. 全链接网络
- 神经网络又被称为多层感知机模型
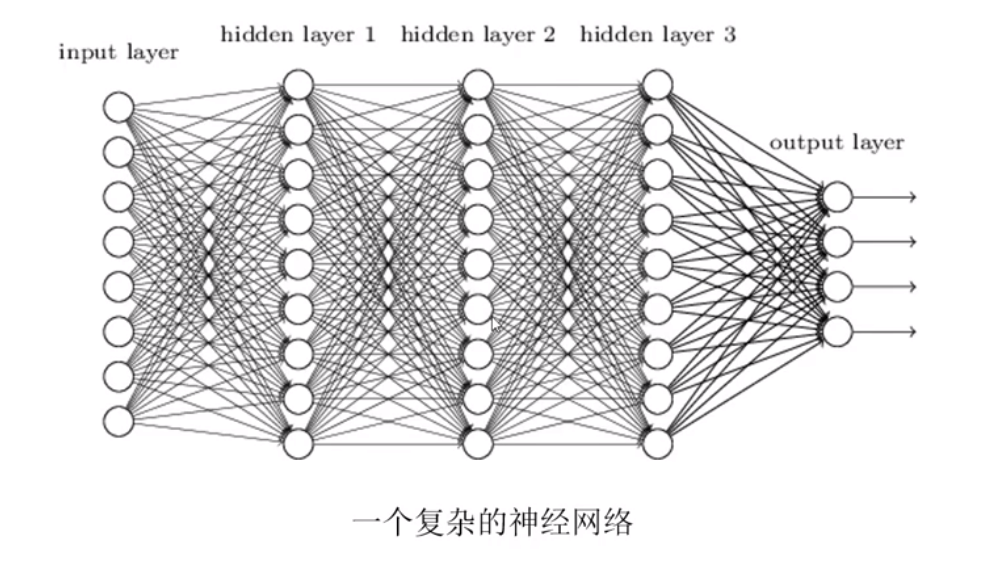
神经网络主要由:输入层,隐藏层,输出层构成。当隐藏层只有一层时,该网络为两层神经网络,由于输入层未做任何变换,可以不看做单独的一层。实际中,网络输入层的每个神经元代表了一个特征,输出层个数代表了分类标签的个数(在做二分类时,如果采用sigmoid分类器,输出层的神经元个数为1个;如果采用softmax分类器,输出层神经元个数为2个),而隐藏层层数以及隐藏层神经元是由人工设定。一个基本的三层神经网络可见下图:
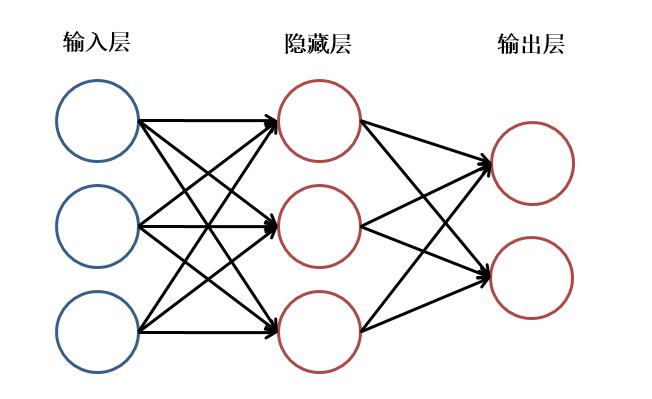
同时上述神经网络也是一个全链接神经网络
全连接:每个神经元都和下一层的所有神经元相连
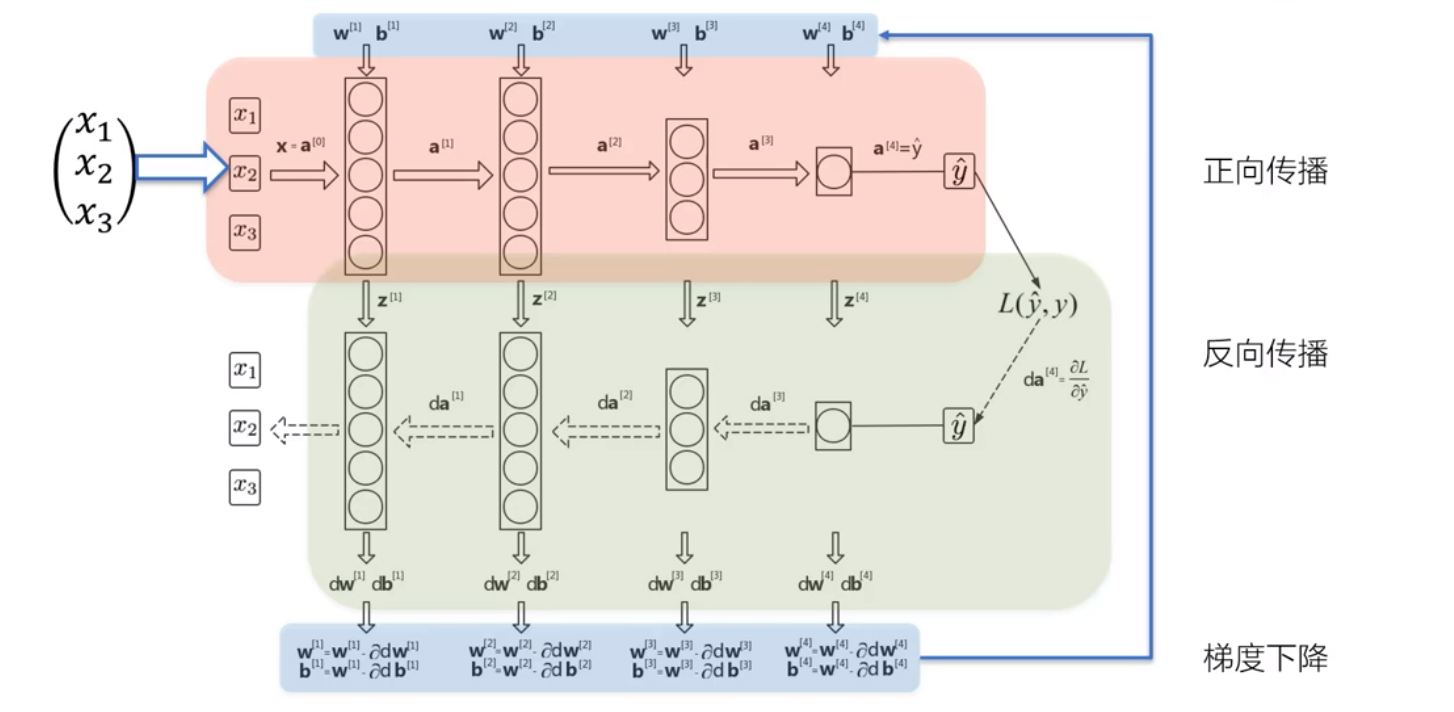
3、深度学习三部曲
3.1 正向传播
由输入计算预测值的过程就是正向传播的过程
3.1.1 参数
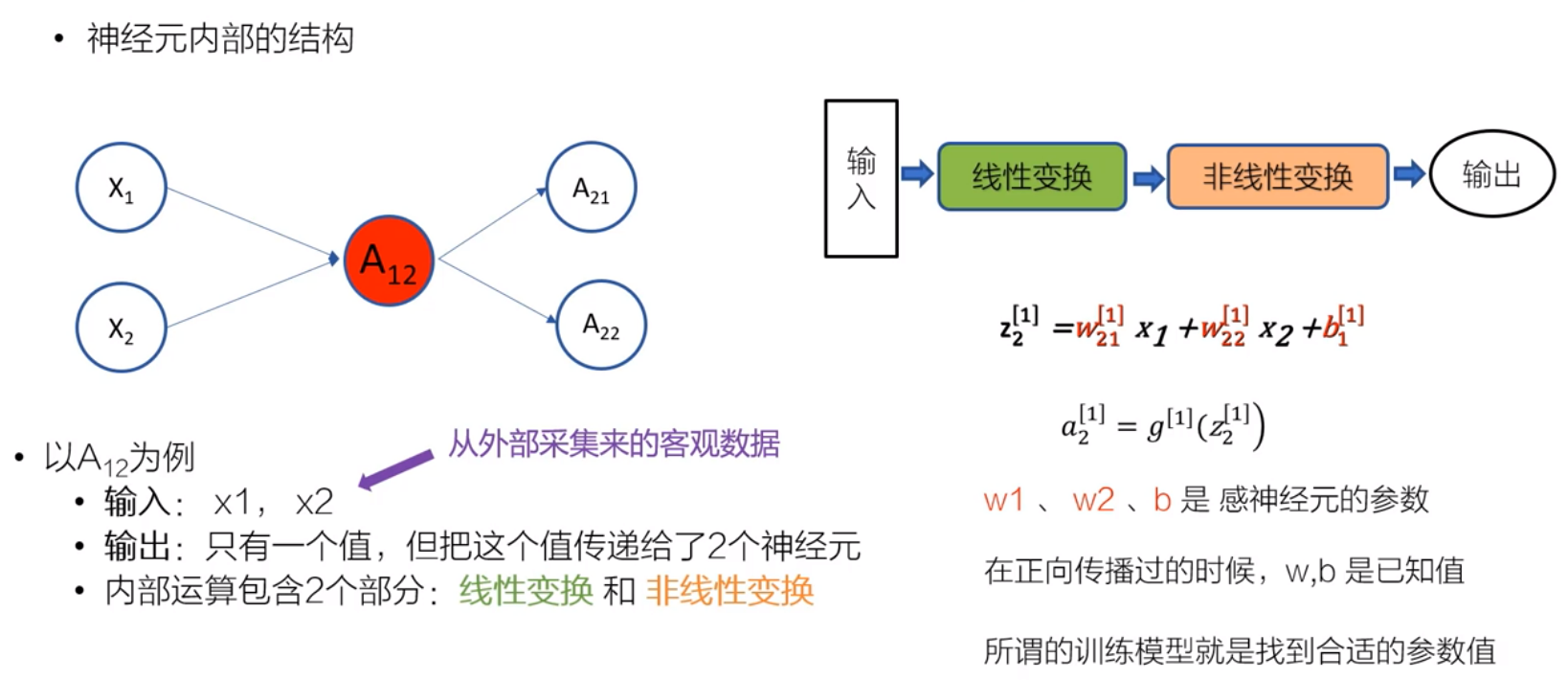
3.1.2 激活函数
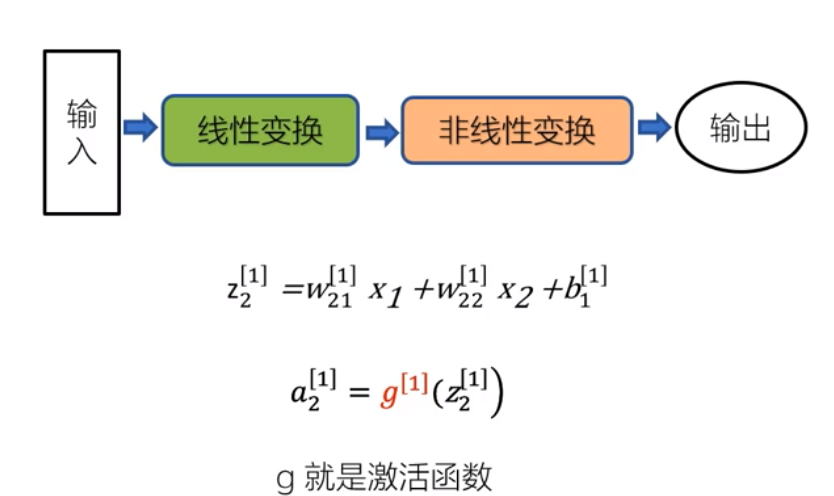
-
常见激活函数
-
sigmoid函数
-
Tanh函数
-
ReLU函数
-
-
特殊的激活函数
- softMax
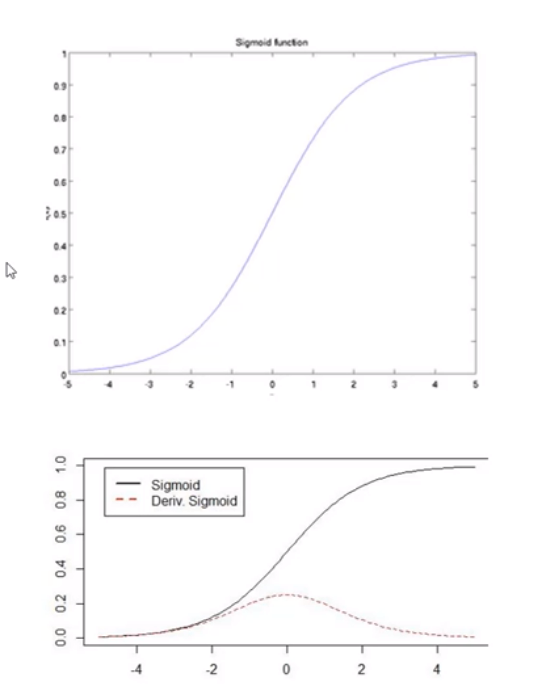
1)sigmoid函数
-
sigmoid函数也叫Logistic函数
-
特点:
-
它可以将一个实数映射到
-
在特征相差不是特别大时效果比较好
-
-
用法:
- 通常用来做二分类
-
缺点:
-
激活函数计算量大
-
容易出现梯度消失
-
当数据分布在曲线平滑位置时很容易就会出现梯度消失
-
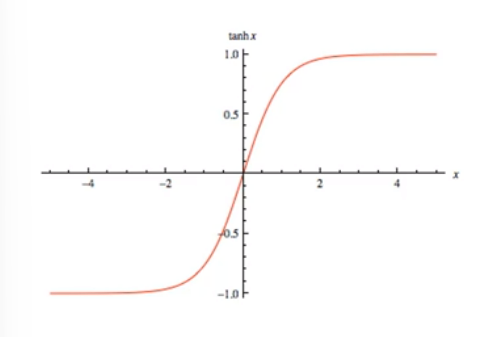
2)Tanh函数
-
Tanh函数也称为双切正切函数
-
特点:
- 取值范围为[-1,1]- 输出是以0为中心
- 可以认为是一个放大的sigmoid函数
-
用法:
- 实际中tanh会比sigmoid更常用
- 循环神经网络中常用
- 靠近输出值位置
- 二分类问题
-
缺点:
- 梯度消失
- 在曲线几乎水平的区域学习非常的慢
Sigmoid函数的改进版
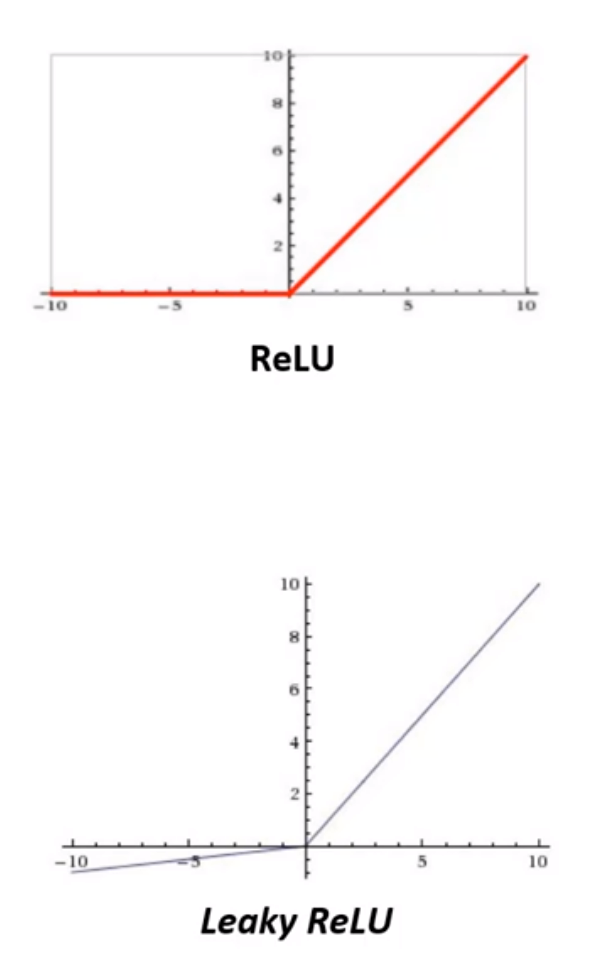
3)ReLU函数
- ReLU函数(矫正的线性单元)
Rectified Linear Unit(ReLU) - 特点:
- 大于0的部分输出为数据本身
- 小于0的部分输出为0
- ReLU对于梯度收敛有巨大加速作用
- 只需要一个阈值就可以得到激活值节省计算量
- 用法:
- 深层网络中隐藏层常用
- 缺点:
- 过于生猛,一言不合就直接使数据变为0,从此节点后相关信息全部丢失
4)softmax激活函数
- Softmax函数 $y_c=\zeta(Z)c=\frac{e^{Z_c}}{\sum\limits{d=1}^Ce^{Z_d}} for c=1…C $
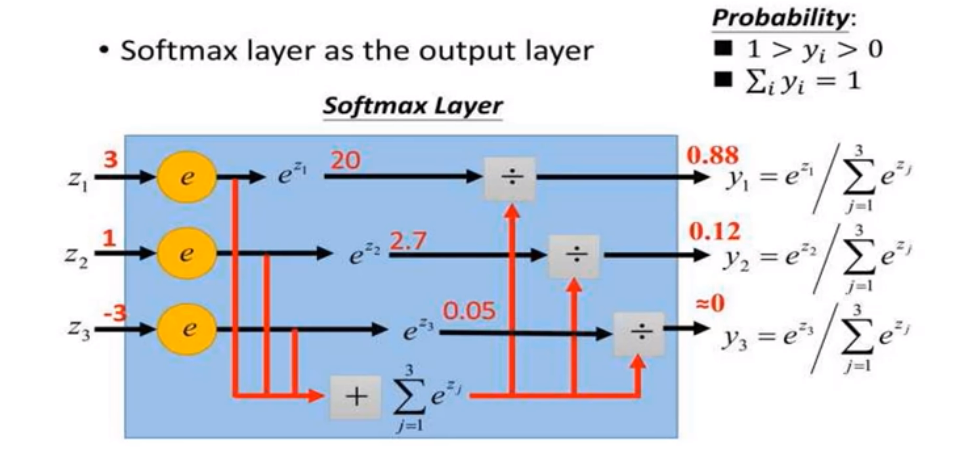
- 特点
- 当有多个输入的时候通过概率求得那个输入能够胜出
- 用法
- 用于多分类神经网络输出
- 用于多分类问题的最后一层
- 缺点
- 基本只用于多分类问题
3.1.2 激活函数
- 正向传播过程可以理解为网络最终算出一个预测值
- 预测值与真实值之间的差距到底有多大呢?
- 通过损失函数来度量预测值与真实值之间的差距
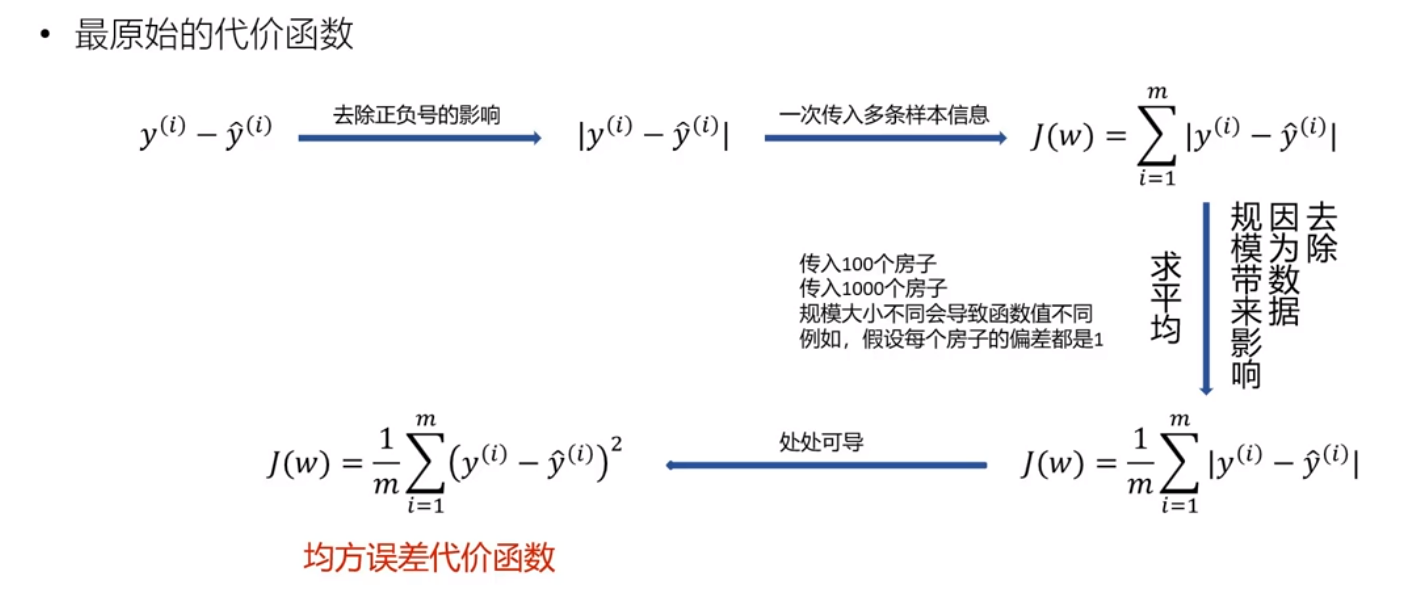
均方误差代价函数(线性回归):
交叉熵损失函数(二分类问题):
交叉熵损失函数(多分类问题):
损失函数推导过程
损失函数示意图
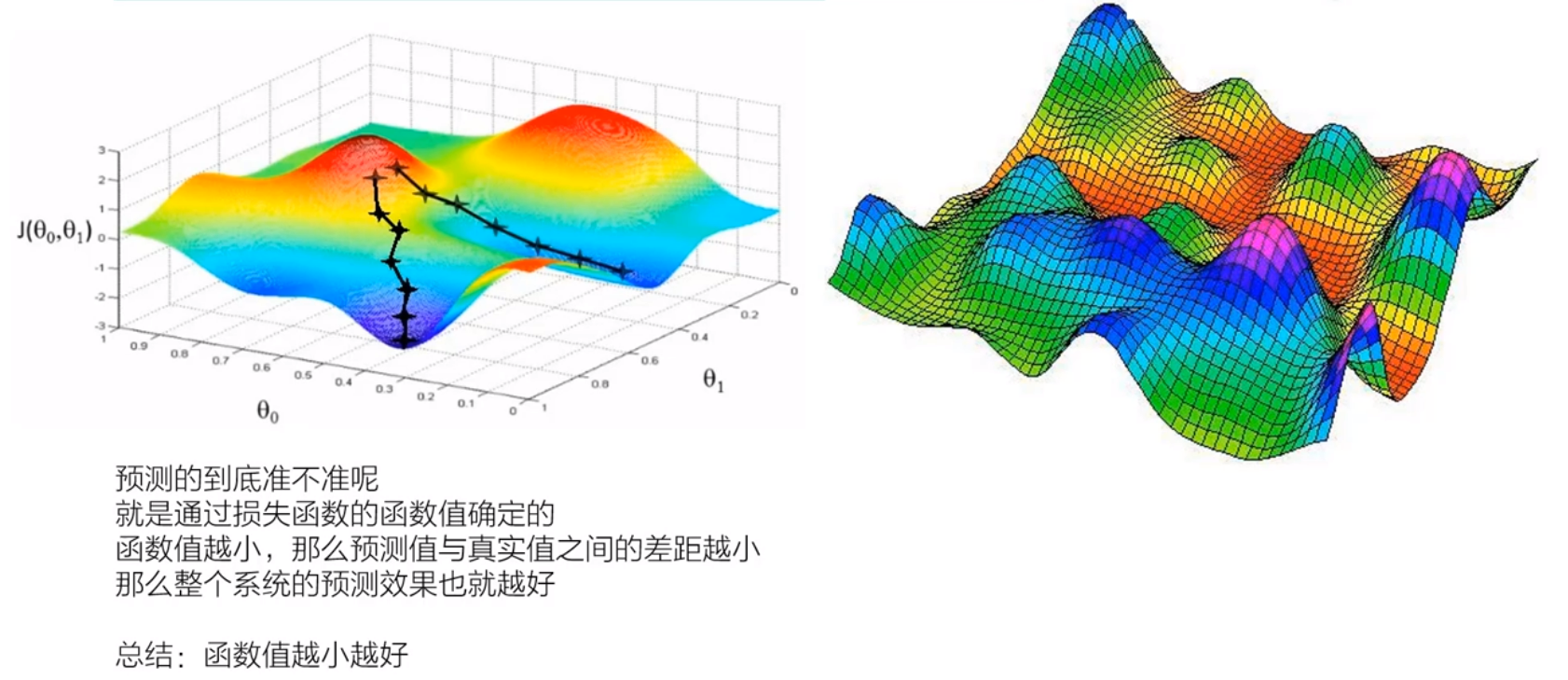
我们的目标就是尽可能的降低函数值
3.2 反向传播
在正向传播过程中,
在反向传播过程中,
- 反向传播算法其运算过程就是**不断的求复合函数的偏导数**
反向传播的过程详解
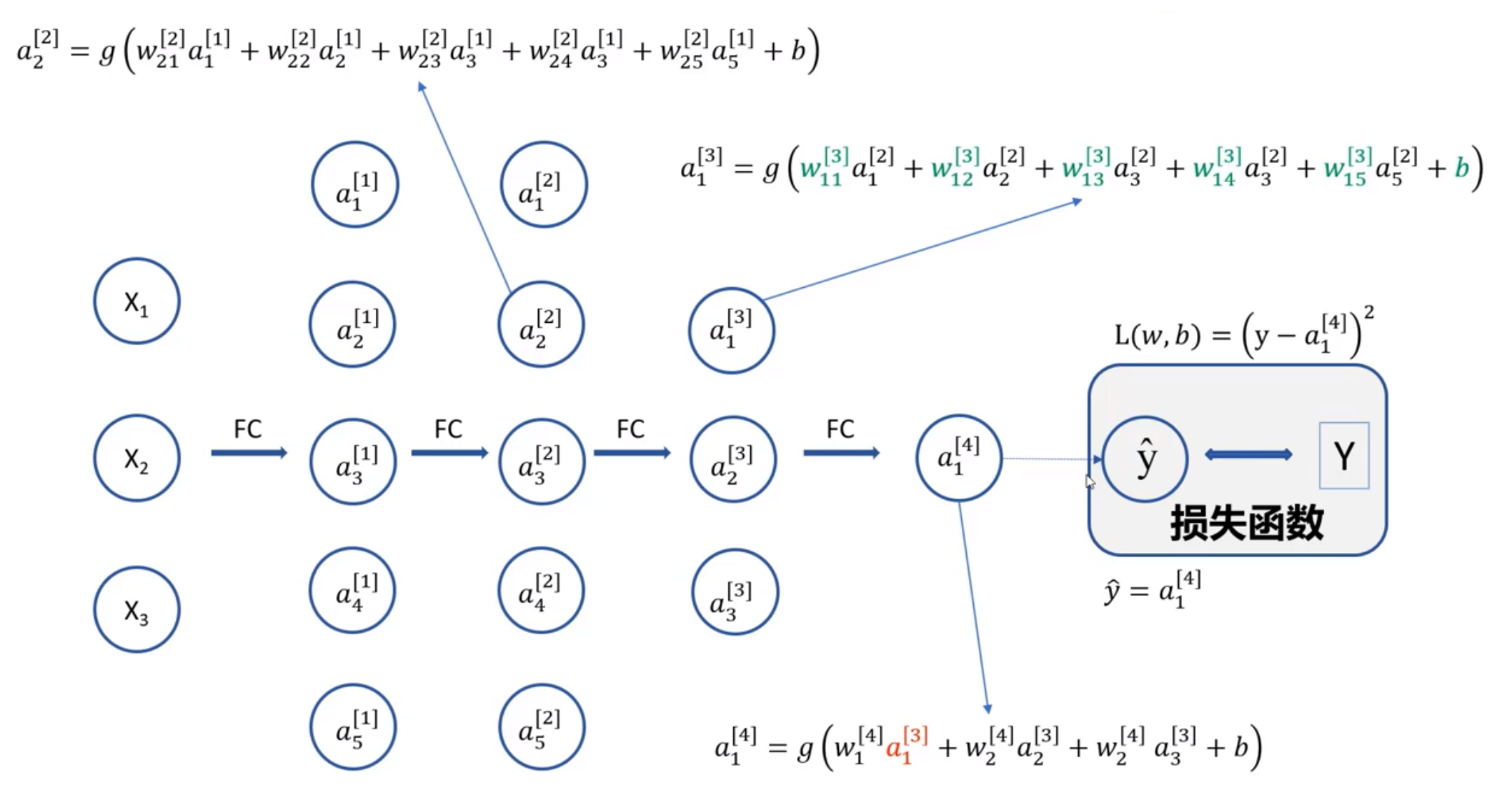
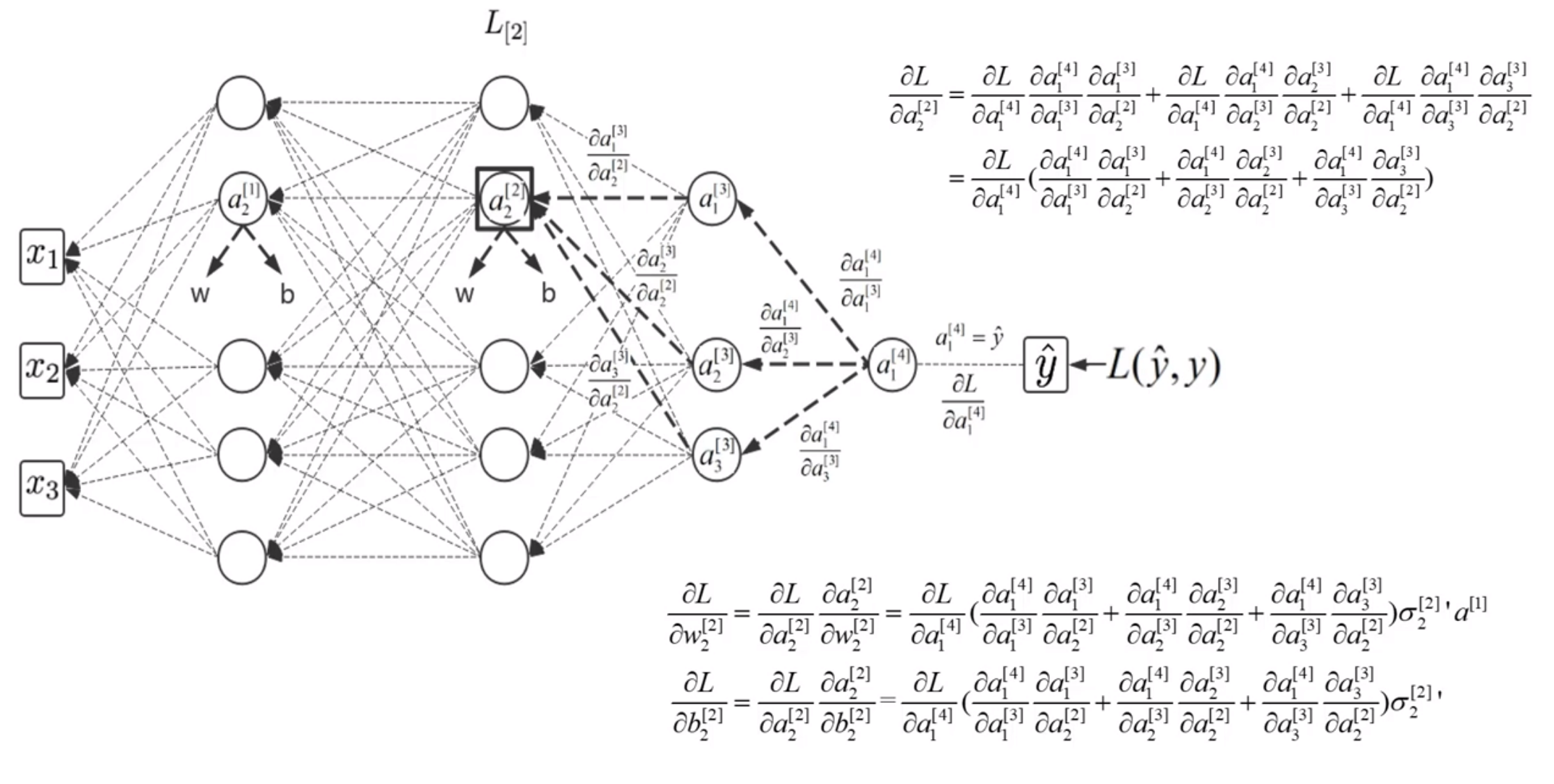
3.3 梯度下降
- 深度学习算法运行的最终目标:寻找损失函数J(w,b)的最小值
- 寻找最小值的方法:梯度下降
- 梯度下降的核心用作:更新参数
- 梯度下降的核心思想:不断的尝试,一步一步的试出这个最小值
直观理解梯度下降
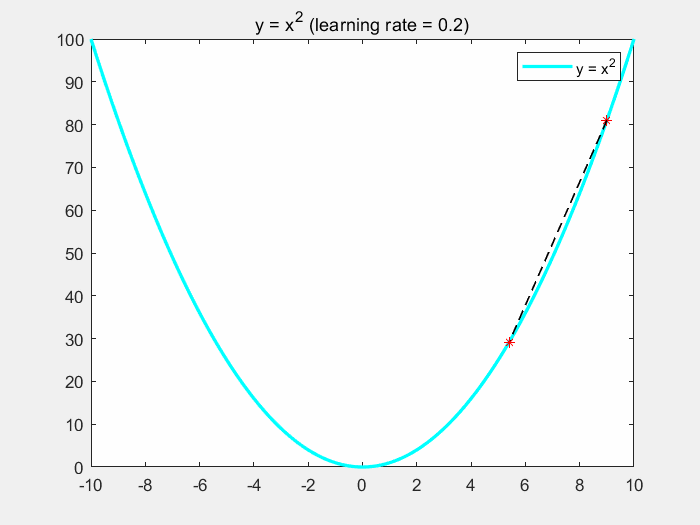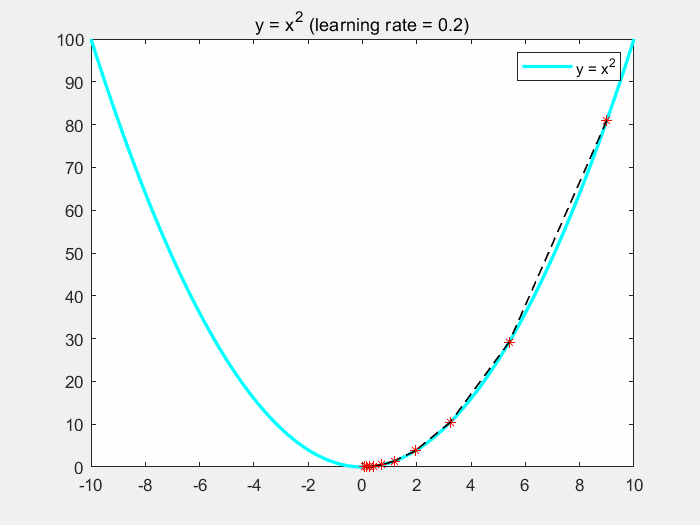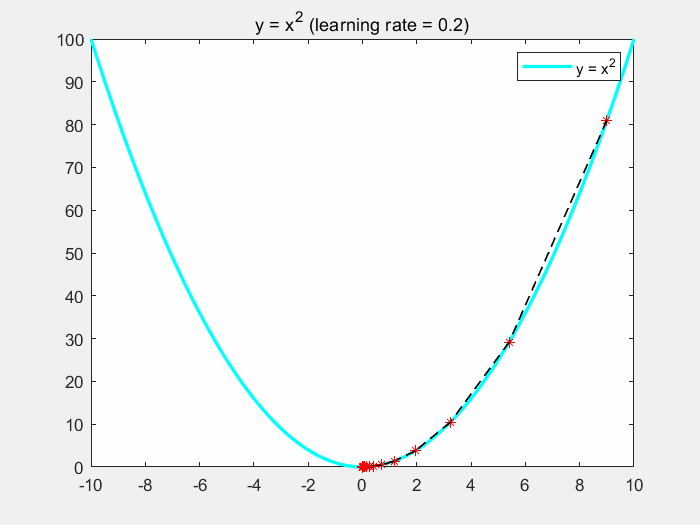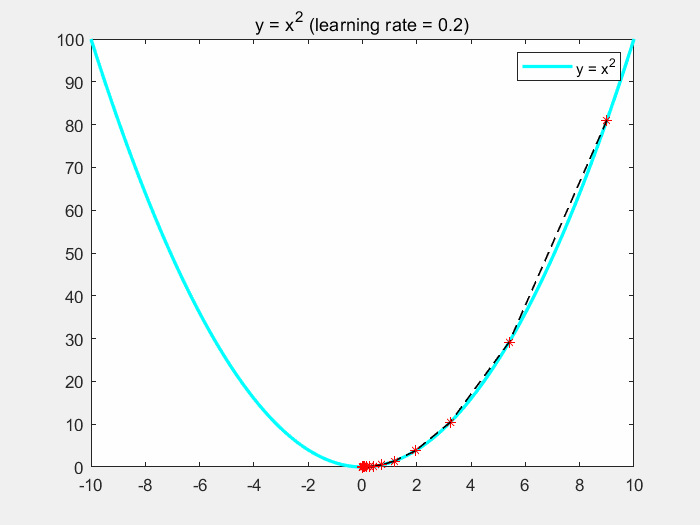
3.3.1 梯度下降的过程
(1)初始化所有的w和b
(2)得到损失函数
根据正向传播算出预测值
(3)得到所有参数的偏导数(得到梯度)
根据反向传播算出
(4)得到学习率
程序手动设置的值(标量,通常为0.01等很小的数字)
(4)更新
根据现有的
3.3.2 学习率的设置
- 学习率是比较重要的超参数
- 通常学习率不能太大也不能太小
- 太大:不收敛
- 太小:学习的太慢
3.3.3 梯度下降的三种方法
1、批量梯度下降
- 批量梯度下降法
—(Batch Gradient Descent,简称BGD)
-
概述
- 批量梯度下降是梯度下降法最原始的形式
- 它的具体思路是:在更新每一参数时都使用所有样本来进行更新
-
优点
- 全局最优解
- 易于并行实现(向量化)
-
缺点
- 当样本数目很多时训练过程会很慢
- 数据量过大把显存撑爆了
- 当样本数目很多时训练过程会很慢
2、随机梯度下降法
- 随机梯度下降法
—(Stochastic Gradient Descent,简称SGD)
- 概述
- 从大量样本中
- 随机抽取一个样本
- 进行迭代
- 优点
- 训练速度快
- 缺点
- 盲目搜索,准确度低
- 不能保证搜索结果一定是全局最优
- 迭代次数增加
3、小批量梯度下降法
- 小批量梯度下降法
—(Mini-batch Gradient Descent,简称MBGD)
- 概述
- 前两种梯度下降法的折中
- 结合其各自的优点
- 平衡各自的缺点
- 更新参数时使用b个样本(b一般为10)
- 优点
- 训练次数尽量小
- 每次训练的耗时尽量少
- 缺点
- 每批次的数量大小也会影响算法效果
梯度下降—总结
- 批量梯度下降:
- 每次选代使用全部样本
- 随机梯度下降:
- 每次迭代使用1个样本
- 小批量梯度下降:
- 每次迭代使用b个样本(b通常需要根据具体情况来定可以考虑设置为64、128…)
简单的线性变换已经能够根据权重来将信息复合起来,为什么还要使用激活函数呢?
- 如果不用激活函数,无论神经网络有多少层,整个网络都将是输入数据的线性变换
- 只有激活函数才能给神经元引入非线性因素,使得神经网络可以逼近非线性函数,当网络足够
复杂的时候就可以逼近任意函数 - 这样神经网络就可以应用到众多的模型中(无论是线性模型还是非线性模型)

人工神经网络被视作可学习的函数,用来逼近复杂的函数
从理论上讲,一个两层的神经网络可以逼近任意的函数。只要有足够的训练数据和神经元数量,人工神经网络就可以学到足够复杂的函数。
前馈神经网络三部曲的总结