网络安全的目标是实现CIA:
- 机密性(Confidentiality):意味着防止未经授权(unauthorized)的数据访问(access)/共享;
- 完整性(Integrity):意味着未经授权的人不得更改数据;
- 可用性(Availability):意味着信息对于授权方应保持一致(consistently)且易于访问(readily accessible) 。
还有一些术语需要了解一下:
- Authentication: Assurance that communicating entity is the one claimed.
- Access Control: Prevention of the unauthorized use of a resource.
- Data Confidentiality: Protection of data from unauthorized disclosure.
- Data Integrity: Assurance that data received is as sent by an authorized entity.
- Non-repudiation: Protection against denial by one of the parties in a communication.
- Availability: Resource accessible/usable.
- Security Mechanism: Feature designed to detect, prevent, or recover from a security attack.
1 网络攻击(Cyber Attacks)
1.1 恶意软件攻击(Malware Attack)
这是最常见的网络攻击类型之一,指的是以恶意软件(malicious software)进行的攻击,包括了病毒(viruses)/蠕虫(worms),间谍软件(spyware),勒索软件(ransomware),广告软件(adware),Rootkit,木马(trojans)。恶意软件可以分类为下面几种:
-
自我复制/传播型:
- 病毒(viruses):是一种恶意程序(malicious program),它会自我复制(replicates itself)并感染计算机,但它需要一个宿主来传播,无法独立运行。
- 蠕虫(worms):则不需要宿主,与病毒类似可自我复制,但无需宿主(doesn’t require a host),能独立通过网络/漏洞自主传播,扩散速度远快于病毒。
-
条件触发型:
- 逻辑炸弹(Logic Bomb):行为类似病毒,平时隐藏,当特定条件触发时(如特定日期:愚人节、圣诞节,特定操作),才执行恶意破坏行为。
-
后门型:
- 木马(trojan):它会伪装成合法软件,但其实是一种恶意软件,可能会安装广告软件、键盘记录器或打开系统后门,让黑客远程控制。
- Rootkit:是一组程序,用于获取系统控制权,同时隐藏自身和其他恶意软件的存在,极难被检测。
-
网络集群型:
- 僵尸网络(Botnet):由被植入恶意代码的 “僵尸电脑(bots)” 组成的网络,由黑客(Botmaster)远程控制,发起 DDoS 攻击,通过发送过量流量(sending out excessive traffic)使服务器或网络瘫痪(cripple a serveror network)。还能用于破解密码(Crack password)、发送垃圾邮件,且难以追踪。
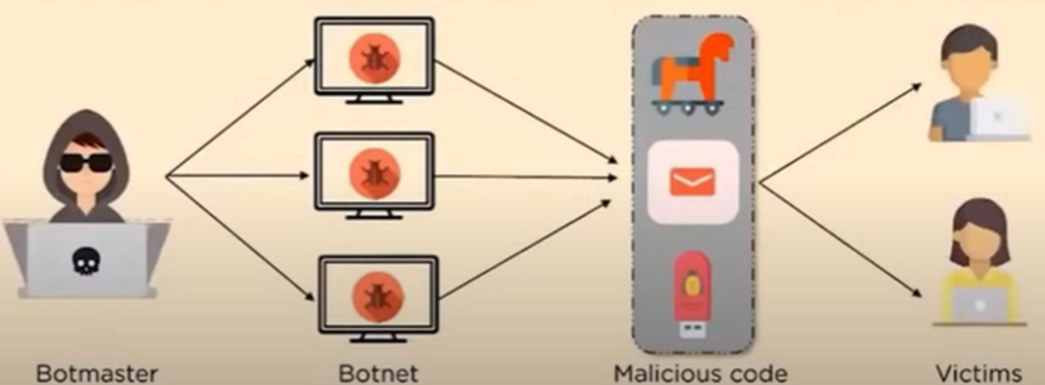
-
数据窃取型:
- 勒索软件(Ransomware):勒索软件会阻止用户访问网络的关键组件,直到用户付费(通常使用比特币),而且在某些情况下,即使付费后也可能无法获得访问权限(granted access)。
- 间谍软件(Spyware):在用户不知情的情况下窃取所有机密数据的软件。
- 广告软件(Adware):在用户屏幕上强制展示广告(如弹窗、横幅(content)),通常伴随隐私数据收集,以广告牟利。
1.2 社会工程攻击(Social Engineering Attack)
社会工程学攻击的本质其实是通过心理操纵(manipulating people),诱骗用户主动泄露机密信息(giving their confidential information),而非单纯依靠技术漏洞入侵。最典型、最广泛的类型就是钓鱼攻击(Phishing Attack)。针对目标对象的不同,可以划分为三类钓鱼形式:
- 普通网络钓鱼:攻击者会伪装成受信任的联系人,广撒网式地向受害者发送虚假邮件。受害者对此毫不知情,打开邮件后点击了恶意链接或邮件附件,由此攻击者就能获取机密信息和账户凭证,他们还可以通过钓鱼攻击安装恶意软件。
- 鱼叉式钓鱼(Spear Phishing):鱼叉式钓鱼攻击时网络钓鱼的升级,区别在于其高度针对性和个性化。攻击者并不会广撒网,而是“像鱼叉精准刺向特定目标”一样,通过研究特定个人、企业或组织的背景信息(如职位、社交关系、业务内容等),精心设计欺骗性内容,以绕过常规安全防护,诱骗目标泄露敏感信息或执行危险操作。
- 鲸钓式钓鱼(Whaling Phishing):捕鲸网络钓鱼攻击又是鱼叉式钓鱼攻击的高阶形态,专指针对企业高管、政府高官、董事会成员、CEO等高价值目标(即“鲸鱼”)的定向网络钓鱼攻击。其核心在于利用目标的高权限与身份以及社会影响力,窃取敏感商业机密、操控资金流转或植入高级恶意软件。
1.3 密码攻击(Password Attack)
实际上就是黑客使用各种程序和密码破解工具(password cracking tools)等各种方式来破解受害者的密码。
以下就是黑客破解密码的常用手段:
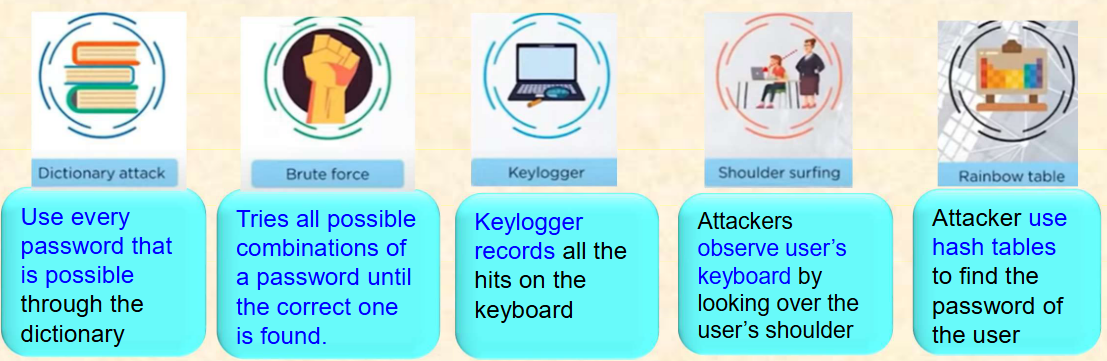
其中,需要注意的是暴力破解的手段,它会涉及到计算,期末必考。
暴力破解其实就是攻击者尝试密码的所有可能组合,直到找到正确的密码。其成功与否取决于:
-
密码长度(Password length)
-
字符集大小(Character set size)
-
尝试速度(单位:tries/sec)(Speed of attempts)
我们可以借此来推导出破解一个密码所需要的破解时间:
其实就是所有可能的密码总和除以计算集群总的破解速率。
Example:
例如一个密码序列的大小(Character set size)为6,密码长度(Password length)是18。假设现在有 1 million 台计算机来进行破解任务,每一台计算机每秒可以尝试3000种组合。由此可以算出破解需要的时间是多少?
Answer:
考试中要注意单位,有时候会要求转换成年。
1.4 中间人攻击(Man-in-the-Middle Attack)
在中间人攻击(MITM,也称为窃听攻击)中,攻击者会介入双方通信(comes in between a two-party communication),也就是说,攻击者会劫持客户端和主机之间的会话(hijack the session),并篡改通信内容。如下所示,客户端与服务器之间的通信已被切断(client-server communication has been cut off),取而代之的是,通信线路会经过黑客。
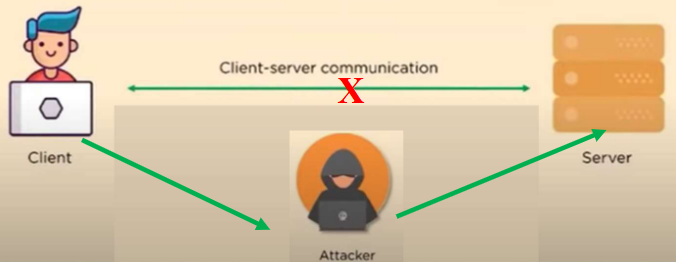
1.5 SQL注入攻击(SQL Injection Attack)
结构化查询语言(SQL)注入攻击发生在数据库驱动(database driven website)的网站上,当黑客操纵标准的 SQL 查询时(manipulates a standard SQL query)就会出现这种攻击。这种攻击是通过向存在漏洞的网站搜索框(vulnerable website search box)中注入恶意代码(injecting a malicious code)来实施的,从而使服务器泄露关键信息(server reveal crucial information)。这会导致攻击者能够查看、编辑和删除数据库中的表(being able to view, edit, and delete tables)。攻击者还可以通过这种攻击获得管理员权限(get administrative rights)。
1.6 拒绝服务攻击(Denial-of-service attact)
DoS 攻击:攻击者向目标系统/服务器/网络发送海量流量,耗尽其资源、带宽,导致系统崩溃,无法处理合法用户请求,使网站关停或响应缓慢。此时正常的访问对于服务器而言就是过载(overwhelming)的。
DDoS 攻击(Distributed Denial-of-Service):DoS 的分布式升级形式,攻击者操控多台被攻陷的 “僵尸机” 发起攻击,攻击规模更大、溯源难度更高。
其中,DDos攻击主要分为下面三类:
- 基于流量的 DDoS 攻击(Volume Based DDoS Attacks)
- 基于协议的 DDoS 攻击(Protocol Based DDoS Attacks)
- 应用层 DDoS 攻击(Application Layer DDoS Attacks)
1.6.1 流量攻击(Volume Based DDoS Attacks)
流量攻击主要有两种:一个是Ping(ICMP)洪水,另一个是UDP洪水;这里主要讲解 ICMP 洪水。
ICMP 洪水是最基础的 DoS 攻击,通过向目标网络发送大量 ICMP回显(echo)请求(ping 命令) 形成流量洪水,阻塞甚至耗尽目标带宽、CPU 资源,导致目标无法处理正常请求。但其生效条件也较为复杂:首先事需要攻击者带宽远高于受害者(从高带宽链路攻击低带宽目标);其次就是目标系统会响应所有 ping 请求。这种攻击的缺点是由于攻击使用的是真实源 IP,攻击者易被追踪追责;其次是目标需响应攻击包,因此会额外消耗资源。所以攻击通常会伪造(spoof)源 IP隐藏身份。
接下来又是一个考试重点,基本也是必考,那就是计算DoS攻击所需要的数据包数量。公式如下:
由此可得,当数据包(packet size)越大时,所需要的包的数量越少;链路速度(speed of link)越高,所需要的包的数量越多。
下面直接看一个例子:
Example:
用 5000 Byte 大小的 ping 包以及 100Mbps 的带宽做 DoS 攻击时,攻击者每秒需要发多少个包,才能把目标的网络链路完全占满,让合法流量彻底无法通行(也就是攻击成功)。
Answer:
1.6.2 协议攻击(Protocol based DDoS Attack)
协议攻击的主要目标是目标设备的网络层(Networking Layer),利用协议本身的设计缺陷,而非单纯占满网络带宽。
常见攻击类型有两种
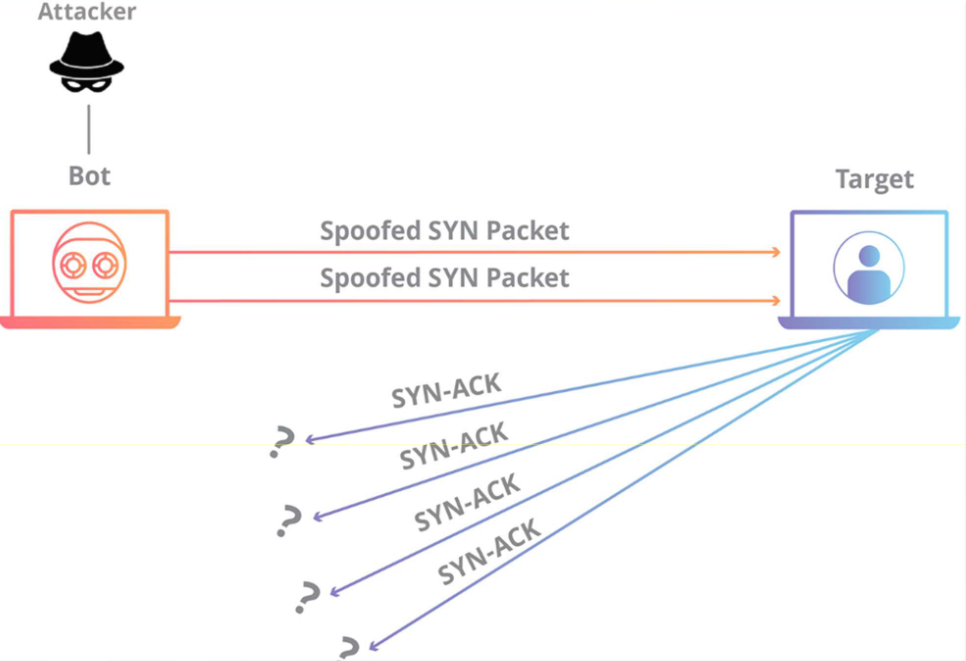
- Ping of Death(PoD):发送超大/畸形的 ICMP Ping 包(sends a high volume of SYN packets),早期设备会直接崩溃;1998 年后的设备基本都内置了防护,已很少见。
- SYN Flood DDoS:如下图,利用 TCP 三次握手的半连接机制耗尽服务器资源。
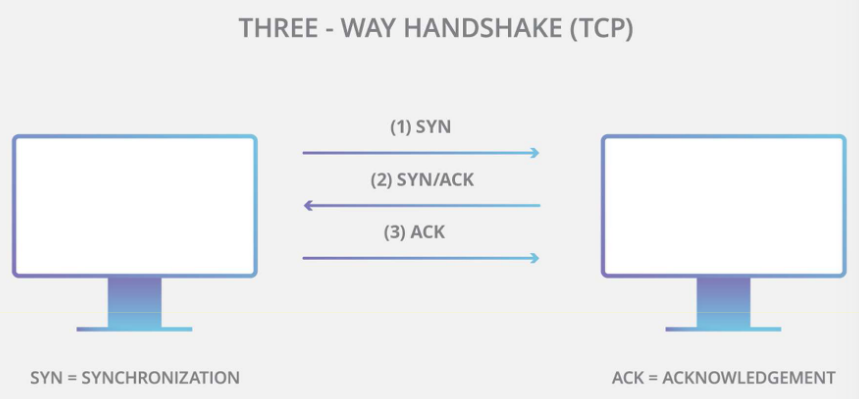
在正常情况下,TCP 连接要经过三个不同的过程才能建立连接。
-
首先,客户端向服务器发送一个 SYN 数据包以发起连接。
-
然后,服务器用一个 SYN/ACK 数据包响应这个初始数据包,以确认通信。
-
最后,客户端返回一个 ACK 数据包,以确认已收到来自服务器的数据包。
完成这一系列数据包的发送和接收后,TCP 连接即打开,能够发送和接收数据。而SYN洪水 DDoS 实现方式就是,攻击者伪造大量虚假IP发送SYN包,但不回复最后的ACK包,使得服务端存在大量半开连接(Half-Open)。服务端为每个半开连接分配资源(如内存中的TCB表),最终耗尽资源,无法响应合法请求,如下图所示。
1.6.3 应用层攻击(Application Layer DDoS Attack)
应用层 DDoS 是 DDoS 攻击中最复杂、最隐蔽的类型,其通过攻击应用层协议(如HTTP、DNS),模仿合法流量以绕过传统防御,通过耗尽Web应用服务器资源导致其崩溃。常见的应用层攻击有两种:
- HTTP洪水攻击(HTTP Flood Attack)
- DNS洪水攻击(DNS Flood Attack)
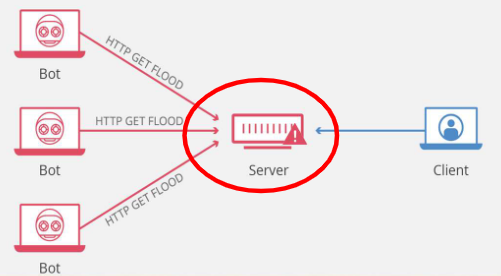
1.6.3.1 HTTP Flood Atttack
攻击者操控僵尸网络向目标 Web 服务器发送海量 HTTP 请求(GET/POST),耗尽服务器的 CPU、内存、连接数等应用层资源;当服务器被请求饱和后,无法响应正常用户的请求,造成拒绝服务。
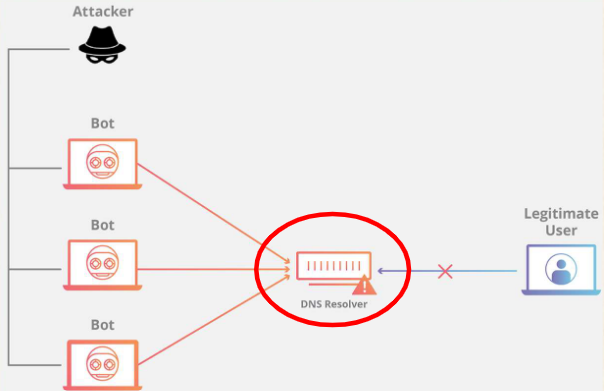
1.6.3.2 DNS Flood Attack
DNS(域名系统)是互联网的“地址簿”:负责把人类易记的域名(如 example.com)转换成机器可识别的 IP 地址(如 192.168.0.1)。一旦 DNS 服务瘫痪,用户就无法通过域名访问任何网站,相当于互联网断网。DNS 洪水攻击就是利用 IP 摄像头、数字录像机(DVR)盒子以及其他物联网设备的高带宽连接组成僵尸网络,向目标域名的 DNS 服务器/解析器发送海量 DNS 解析请求,最终瘫痪该域名的 DNS 服务。
1.7 内部威胁(Insider threat)
内部威胁的发起者不是外部黑客 / 第三方,而是组织内部的人员(involve a third party but an insider)(包括在职 / 离职员工、承包商、合作伙伴等拥有内部权限的人)。这类人员熟悉组织的系统架构、数据位置、安全流程,能轻松绕过外部防火墙等防护,因此可以造成远超外部攻击的巨大损失(比如核心数据泄露、系统破坏、财务欺诈等)。
1.8. 挖矿劫持(Crytojacking)
Cryptojacking是指攻击者未经授权非法入侵他人的计算机、手机、服务器等设备,在受害者完全不知情的情况下(Crypto mining code works in the background),利用设备的 CPU/GPU 算力挖掘加密货币(如门罗币、比特币等)的攻击行为。攻击者零成本获得挖矿收益,而受害者要承担设备损耗、电费飙升、性能下降的损失。
攻击者主要通过两种方式入侵设备:
- 网站感染(infecting a website):在正常网站中植入恶意挖矿脚本,用户只要访问该网站,脚本就会在浏览器后台自动运行,占用设备算力挖矿;
- 诱导点击(manipulating the victim to click on a malicious link):通过钓鱼邮件、恶意广告、恶意链接等方式,诱导受害者点击,从而在设备中植入挖矿木马,后台长期运行挖矿程序。
2. 黑客(Hacker)
| 类别 | 别称 / 核心属性 | 行为与意图 | 典型场景 |
|---|---|---|---|
| 白帽黑客(White Hat) | 道德黑客(Ethical Hackers) | 合法合规,主动协助企业修复网络漏洞、开展渗透测试(PenTest)、清除病毒,维护网络安全 | 企业安全运维、网络安全合规审计 |
| 黑帽黑客(Black Hat) | 恶意攻击者 | 以非法牟利为目的,窃取钱财、信用卡信息、核心数据,破坏网络系统 | 网络诈骗、数据勒索、核心资产窃取 |
| Gray 灰帽黑(Hat) | 中立 / 警示型黑客 | 利用系统 / 产品漏洞,但目的是提醒所有者修复漏洞,而非恶意破坏 / 牟利 | 发现漏洞后私下告知,而非公开攻击 |
| 脚本小子(Script Kiddies) | 入门级黑客 | 技术能力薄弱,依赖现成攻击脚本(Script)开展攻击,无自主开发工具的能力 | 跟风破坏小型网站、恶意骚扰 |
3 教育,意识和合规(Education, Awareness and Compliance)
员工行为是确保计算机系统和信息资产安全的关键因素。与员工行为相关的主要问题包括:操作失误与疏漏、欺诈行为以及心怀不满员工的蓄意破坏。
3.1 安全意识(Awareness)
安全意识建设的收益:
- 员工明确自身安全责任与行为限制,并主动按要求执行(motivated to act accordingly);
- 用户理解安全对组织整体利益的重要性。
为了强调安全意识,企业必须制定一份全员覆盖的安全意识政策文件,其核心要素包括:
- 全员参与机制:所有员工必须参加安全意识培训,包括新人的入职培训以及定期的宣传活动;
- 时间保障条款:专门安排时间让员工进行宣传活动的参与;
- 明确管理责任:清晰界定安全意识活动的管理、执行责任主体(如 IT 安全部、HR、部门负责人等)。
3.2 安全培训(Training)
安全培训计划的核心目标:教导员工如何以更安全的方式完成 IT 相关任务,明确做什么和怎么做,培训内容根据岗位角色分层设计,覆盖从基础计算机技能到高级专业技能的全范围。
| 岗位角色 | 培训核心目标 |
|---|---|
| General users(普通员工) | 聚焦良好的计算机安全实践 |
| 程序员 / 开发人员 / 系统维护人员(Programmers, developers, system maintainers) | 培养开发人员的安全思维(mindset) |
| 管理层(Management-level) | 掌握安全风险、成本、收益的权衡( tradeoffs)方法 |
| 高管层(Executive-level) | 明确风险管理目标、量化方法与领导力要求 |
3.3 合规(Compliance)
网络安全合规是指遵守旨在保护数据、系统和网络免受网络威胁的法律、法规和标准的做法。没有任何组织能完全免受网络攻击的影响,因此这意味着合规是任何组织网络安全计划的重要组成部分,它可能是决定一个组织能否取得成功、顺利运营并维持安全做法的关键因素。
3.3.1 合规管理的核心价值
实施适当的网络安全合规措施对组织有益,原因如下:
- 保护其声誉(reputation)
- 维持客户或委托人的信任
- 建立客户信心和忠诚度(loyalty)
- 有助于识别、解读(interpret)潜在的数据泄露(data breaches)并为此做好准备
- 提升组织的安全状况(security position)
- 保持网络安全合规还能保护知识产权(IP—intellectual property),如商业秘密、产品规格和软件代码等核心竞争资产。
3.3.2 网络安全合规体系建设步骤
建立一个网络安全合规,主要是以下5个步骤:
-
组建合规团队(Creating a Compliance Team):企业 IT 部门是合规的核心力量,必须专门成立合规团队,负责统筹全公司的合规工作,不能让合规变成 “没人管的事”。
-
建立风险分析流程(Setting Up a Risk Analysis Process):
- 识别(Identify):任何访问数据的信息系统、资产或网络都必须被识别。
- 评估(Assess):给每一类数据、每一个系统评估风险等级,比如客户身份证信息就是高风险,普通办公文件就是低风险。
- 分析(Analyze):用公式算风险大小:
- 设定风险容忍度(Set Tolerance):针对不同风险,决定处理方式。缓解(比如给系统加防护)、转移(比如买网络安全保险)、规避(比如停用高风险系统)、接受(比如低风险、成本高的,选择接受)。
-
设置安全控制措施(Setting Controls):控制措施可以是技术控制,例如密码和访问控制列表,也可以是物理控制,例如监控摄像头和围栏。PPT 里列了最常用的 8 种:
- 加密(Encryption)
- 网络防火墙(Network firewalls)
- 密码策略(Password policies)
- 网络安全保险(Cyber insurance)
- 员工培训(Employee training)
- 事件响应计划(Incident response plan)
- 访问控制(Access control)
- 补丁管理计划(Patch management schedule)
-
制定合规制度(Creating Policies):把上面的控制措施写成正式的公司制度,明确 IT 部门、员工、各岗位的合规要求,比如《密码管理制度》《数据安全制度》等。同时这些制度也是未来内部审计、外部监管检查的依据。
-
持续监控以及快速响应(Monitoring and Quick Response):合规不是一劳永逸的,要持续监控合规体系的运行,因为法规会更新、威胁会变化,制度也要跟着改。同时要建立快速补救流程,万一被攻击,能第一时间止损,把损失降到最低。
3.3.3 合规管理的 9 大核心领域
企业合规必须覆盖这 9 个方面:
- 访问控制(Access Control):按岗位给权限(Role-based)(比如财务只能看财务数据)、最小权限(least privilege)(不给多余权限)、多因素认证(multi-factor authentication)(除了密码还要验证码 / 指纹),防止越权访问。
- 数据保护(Data Protection):加密(Encryption)、数据脱敏(data masking)(比如把手机号中间几位打码)、定期备份和恢复(backup and recovery)。
- 事件响应计划(Incident Response Plan):必须写清楚 “发现攻击(detection)、处置攻击(response)、恢复业务(recovery)” 的全流程步骤,出事按流程走。
- 风险管理(Risk Management):持续评估(Assess)、缓解(mitigate)、监控(monitor)安全风险,不是做一次就完事。
- 审计与日志(Audit and Logging):记录所有系统操作日志,跟踪活动(Track activities)以检测和调查威胁。Clear policies for password use, BYOD, etc.
- 制度文档(Policy Documentation):写清楚密码使用、员工自带设备办公(BYOD)等所有场景的合规要求。
- 培训与意识(Training and Awareness):让所有员工都知道合规要求,避免员工无意违规。
- 第三方风险(Third-party Risk):供应商、合作方也要符合合规要求,不能因为第三方的漏洞连累自己。
- 渗透测试与漏洞管理(Penetration Testing and Vulnerability Management):定期找黑客模拟攻击(渗透测试),找系统漏洞,持续评估(Ongoing assessment)。
3.3.4 合规风险量化评估方法
在网络安全合规中,我们还需要对合规风险评估进行量化,把抽象的风险转化为可计算的数字,以此精准判断企业风险等级。核心风险计算公式如下:
Example:
某医院评估自己的患者信息系统,给出三个维度的评分:
- 威胁可能性(Threat Likelihood) = 4(黑客攻击该系统的概率很高)
- 漏洞等级(Vulnerability Level)= 3(系统有一定防护,但存在中等程度的安全漏洞)
- 资产价值(Asset Value)= 5(患者信息是医院核心资产,价值最高,泄露损失极大)
Answer:
核心风险计算:
相对风险换算:
因此,风险等级判定:中等风险(medium level risk)
4 规划与政策(Planning and Policy)
4.1 网络安全规划(Cyber Security Planning)
网络安全规划是任何旨在防御攻击并降低 IT 环境中风险的努力的核心。
它其实是一份书面文件(written document),包含了有关组织的安全政策、策略、程序以及组织在寻求实施成功的网络安全计划时将依赖的技术的信息,确保了运营的完整性和组织关键资产(critical assets)的安全性。
主要目标有以下几条:
- 保护机密性、完整性和可用性(CIA 三元组);
- 管理网络风险;
- 确保业务连续性;
- 满足法律和法规要求;
4.1.1 核心价值
做网络安全规划有以下好处:
-
更好地理解风险(Better Understanding of Risks):各组织已广泛使用云计算技术、移动设备、物联网(IoT)、智能可穿戴设备等,这导致它们面临大量网络攻击和威胁。而网络安全计划可以帮助组织了解当前的 IT 环境,使它们能够做出必要的修正(amendments)以确保其安全。
-
实现主动防护(Enabling Proactive Protection):面对网络犯罪需要主动进行防御,否则就可能陷入危险中。可以制定一个从根本上强大的网络安全计划,其中包括漏洞分析(vulnerability analysis)和渗透测试(penetration testing)、安全漏洞扫描(security vulnerability scans)、业务连续性(business continuity)和灾难恢复(disaster recovery),这将使组织能够以主动(proactive)的方法管理安全服务。
-
及时响应(Respond Promptly):没有任何组织能做到 100% 安全,即便配备了最强大的安全解决方案,仍会有一些攻击得逞。这就是制定网络安全响应计划会有所帮助的原因。而制定这个计划意味着明确在遭遇网络攻击时应采取的确切步骤以此来减少损失。
-
必要的合规要求(Necessary Compliance Requirements):在这个监管严格的行业,必须遵守相关的合规标准和法规。例如:通用数据保护条例(GDPR)、支付卡行业数据安全标准(PCI DSS)、健康保险流通与责任法案(HIPAA)等。网络安全计划可确保最大限度的合规性(guarantees utmost compliance),并使企业能够监控所有最佳实践,同时持续满足行业原则和协议(protocols)。
-
防范内部威胁(Prevent Insider Threats):网络安全计划会让网络安全成为组织文化的一部分,员工将参与网络安全意识和培训课程;因此,内部威胁将会呈下降趋势。
4.1.2 核心维度
网络安全规划包含两大核心维度:技术层面与管理层面。
-
技术安全维度:培养计算机安全方面的技术专长和开发相关技术
- 加密技术体系(Encryption techniques)
- 智能防火墙系统(Firewalls)
- 生物识别安全技术(Biometric-based security technologies)
-
管理安全维度:制定安全政策和程序
- 安全策略与执行机制(Policies and mechanisms)
- 运营管理规范(Operational Issues)
- 人员安全管理(Human Issues)
4.2 网络安全政策(Cyber Security Policy)
网络安全政策是一套正式的规则和实践,用于规范信息和系统的管理、保护及分发方式。
其核心职能有:
- 建立行为预期(Establish expectations for behavior)
- 对齐安全与业务目标(Align security with business goals)
- 定义访问控制与权限(Define access controls and privileges)
- 指导法律法规合规(Guide compliance with laws and standards)
4.2.1 常见政策类型
常见的网络安全政策类型如下:
| 政策类型(Policy Type) | 描述(Description) |
|---|---|
| 可接受使用政策(Acceptable Use Policy, AUP) | 定义系统和数据的允许使用范围 |
| 访问控制政策(Access Control Policy) | 详细说明访问权限的授予与管理方式 |
| 事件响应政策(Incident Response Policy) | 指导网络安全事件的处理流程 |
| 数据分类政策(Data Classification Policy) | 明确数据的标注与保护规则 |
| 加密政策(Encryption Policy) | 规定数据加密的时机与方式 |
| 密码政策(Password Policy) | 设定密码强度要求 |
| 远程访问政策(Remote Access Policy) | 管控外部网络的安全接入 |
4.2.2 网络安全治理框架
网络安全治理(governance)是网络安全的领导力、问责制与监督框架,核心要素有:
- 网络安全委员会(Cybersecurity Committee):组织内部的监督机构;
- 首席信息安全官(Chief Information Security Officer, CISO):负责安全战略制定。
4.2.3 政策实施流程
最后,来看看网络安全政策的实施与执行,其可以通过以下方式实施:
- 识别风险(Identifying risks)
- 借鉴行业经验(Learning from others)
- 符合法律要求(Conforming to legal requirements)
- 员工参与政策制定(Including staff in policy development)
- 员工培训(Training employees)
- 明确违规处罚(Setting clear penalties)
- 政策落地执行(Enforcing policies)
- 部署必要工具(Installing required tools)
4.2.4 政策强制执行机制
那么如何强制执行政策呢?可以通过四种方式:
- 沟通(Communication):向全员清晰传达政策,提供相关培训与资源,明确责任;
- 访问控制(Access Controls):通过身份认证(user authentication) 、多因素认证(multi-factor authentication)等限制未授权访问用户对系统和数据进行访问;
- 监控与审计(Monitoring and Auditing):定期监控审计(auditing)系统,发现违规行为并优化控制(additional controls );
- 违规后果(Consequences):建立纪律处分(disciplinary action)机制,约束员工行为。
5 网络安全实施路径(Cyber Security Approaches)
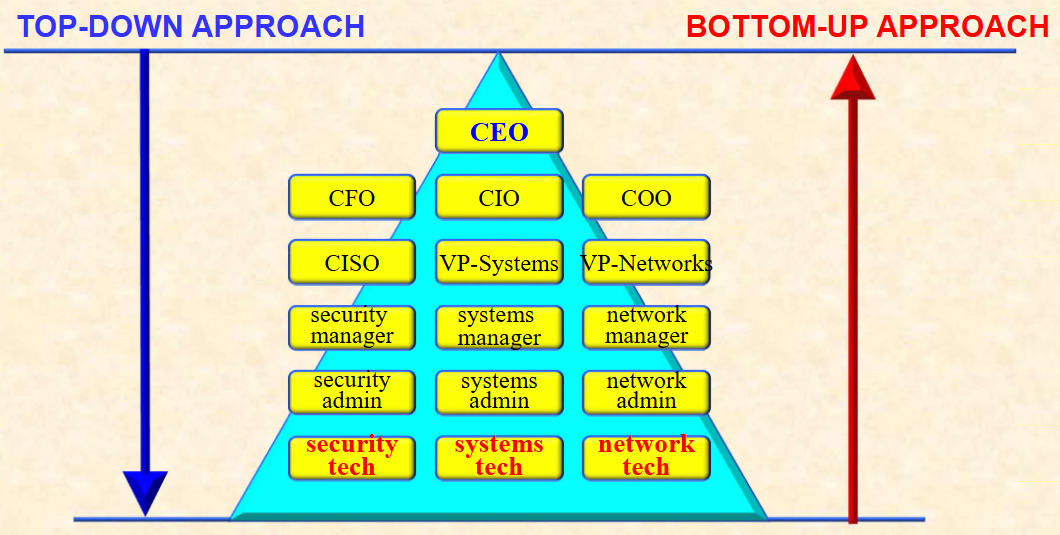
5.1 自下而上方法(Bottom-Up Approach)
- 核心逻辑:由系统管理员(systems administrators)自主发起,开展系统安全能力提升工作。
- 优势:发挥管理员技术专长(technical expertise)。
- 劣势:由于缺乏参与者支持、组织持续力,因此很少起作用。
5.2 自上而下方法(Top-Down Approach)
-
核心逻辑:由企业高层管理(upper management)发起,统一制定安全政策、流程与标准,规定项目的目标和预期结果;并对每项必要的行动负责的对象。
-
优势:
- 强有力的高层管理支持;
- 专项经费;
- 清晰的规划以及可塑造组织安全文化。
6 网络安全战略(Cyber Security Strategies)
网络安全战略是一项计划,它选择并实施(implementing)最佳实践,防范内外部网络威胁(internal and external cyber threats),核心目标有:识别(identify)、保护(protect)、检测(detect)、响应(respond)、恢复(recovery)。
6.1 数字责任管理(Digital Liability Management, DLM)
DLM 也被称为政策与技术的交叉点,侧重于政策与技术如何共同应对网络的关键威胁。其核心目标就是前置防范网络入侵与安全事件,如果事件不可避免的发生时,能提供有效的应急防御能力。
DLM有四大防御层级(Four Tiers of Defense),能够很好地帮助企业应对具有挑战性的威胁和漏洞:
- 高层管理承诺与支持(Senior management commitment and support);
- 可接受使用政策等实践规范(Acceptable-use policies and other statements of practice);
- 安全使用流程(Secure-use procedures);
- 硬件、软件与网络安全工具(Hardware, software and network security tools)。
6.2 零信任安全(Zero Trust Security)
Zero Trust Security的方式就是永不信任(never trust)任何用户或数据,始终都需要进行验证(always verify)。
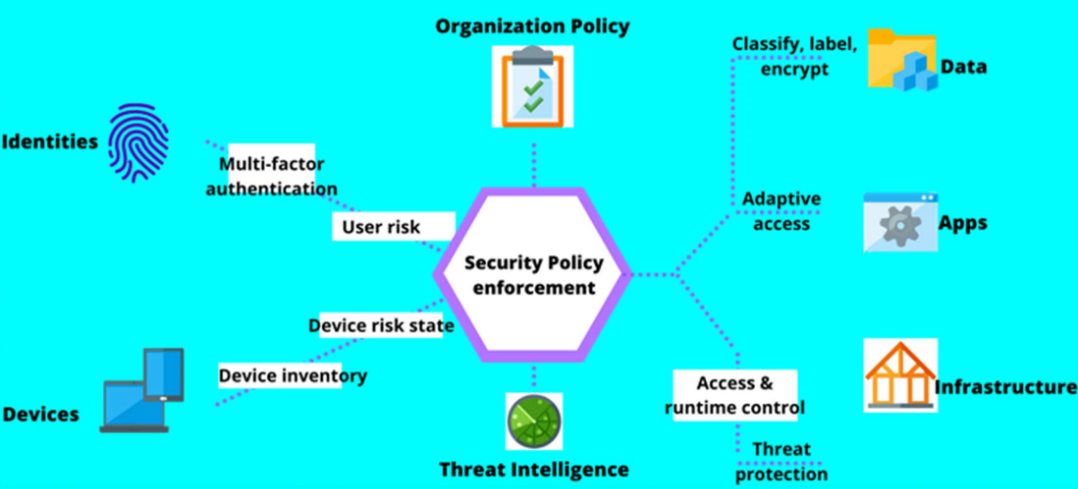
可以看到这一方式的核心逻辑就是:以安全政策执行(Security Policy enforcement)为中心,覆盖身份(Identities)、设备(Devices)、数据(Data)、应用(Apps)、基础设施(Infrastructure)等全维度,结合多因素认证(multi-factor authentication)、自适应访问(adaptive access)、威胁情报(Threat Intelligence)等机制,构建全场景动态安全体系。
6.3 深度防御战略(Defense In-depth Strategy)
Defense In-depth Strategyj就是通过构建多层级、立体化的安全防御体系(layering of security defenses),以此来避免单点防护失效而导致的整体安全失守。
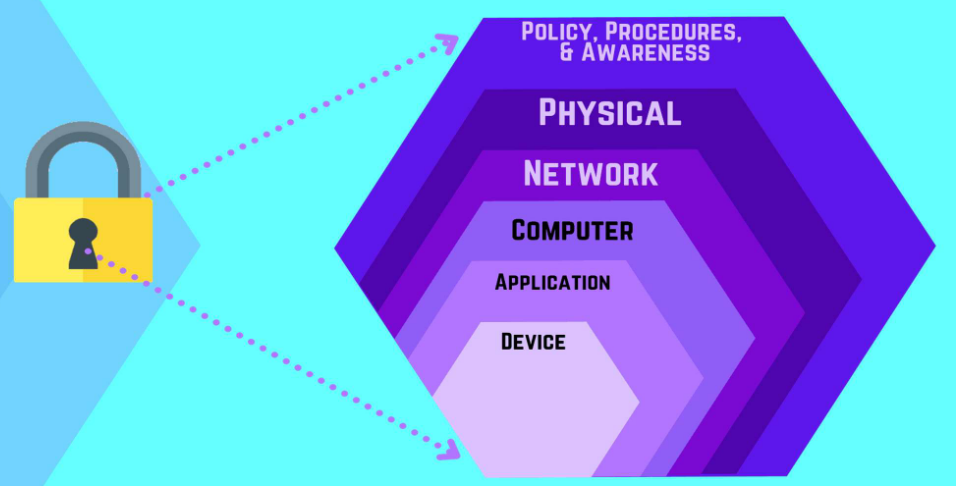
防御层级(从外到内,由宏观到微观):
- 政策、流程与安全意识(Policy, Procedures, & Awareness)
- 物理安全(Physical Security)
- 网络边界安全(Network Security)
- 计算机终端安全(Computer Security)
- 应用系统安全(Application Security)
- 设备与数据安全(Device Security)
6.4 铁三角模型
完整有效的网络安全防护,必须依靠人、流程、技术三大要素的协同支撑,单一维度的建设无法实现真正的安全闭环。
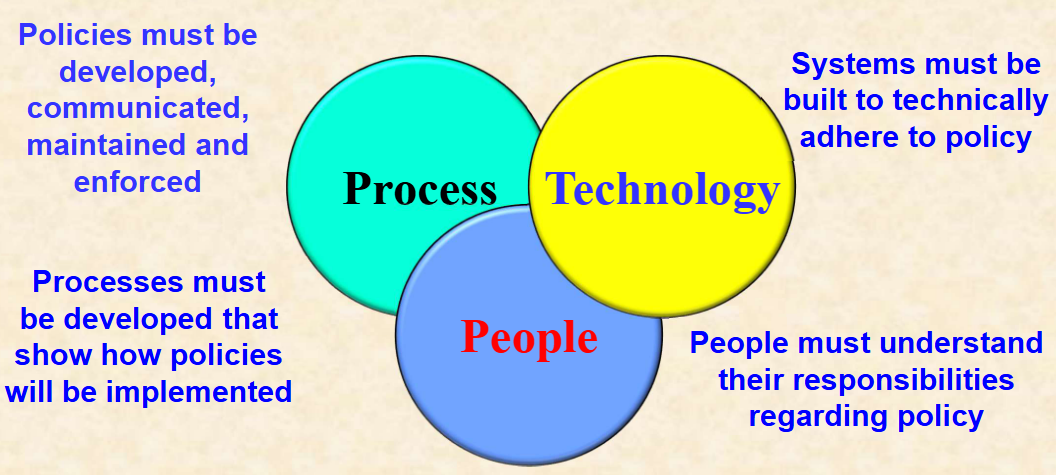
流程为技术部署和人员行为划定规则,技术为流程落地和责任履行提供工具支撑,人则通过执行持续优化流程与技术体系,形成安全闭环。
7 基于生物特征识别的安全方法(Biometric-Based Security Approaches)
很多人对网络安全的认知,还停留在防火墙、杀毒软件、漏洞防护这些 “外围屏障” 上,但实际上,**身份认证是网络安全的第一道、也是最核心的一道防线。**如果系统连 “访问者是不是合法用户” 都无法确认,再厚的防护墙也形同虚设。
在了解生物特征识别之前,我们需要先知道身份认证有几种形式。
实际上身份认证的本质,就是向系统证明 “你是你”,目前通用的认证逻辑分为三大类,也是我们日常接触最多的认证方式:
- 你拥有的东西(Something you have):基于实体凭证的认证,比如动态令牌、智能卡、U 盾,核心逻辑是 “只要持有合法凭证,就认定为合法用户”。
- 你知道的信息(Something you know):基于秘密信息的认证,最典型的就是密码、PIN 码,也是过去几十年里全球最主流的信息保护方式。
- 你本身的特征(Something you are):基于生物特征的认证,也就是我们常说的生物识别(Biometric),比如指纹、人脸、虹膜识别。
纯密码认证已经越来越难满足安全需求。随着处理器算力的指数级提升、密码分析技术的不断进步,纯密码的防护能力已经大幅弱化:弱密码容易被暴力破解,强密码又难记忆、易泄露,这也是生物识别认证快速普及的核心原因。
7.1 生物识别基础
很多人会把这两个概念搞混,但它们是生物识别体系的两个完全不同的核心环节,也是考试和面试的高频考点。
7.1.1 识别(Identification)
识别就是确认“你是谁”(Who are you?)。实际上就是一对多的匹配,系统把采集到的生物特征,和数据库里所有用户的模板做比对,最终确定你的身份。
7.1.2 验证(Verification)
而验证则是确认“你是不是你声称的那个人”(Are you who you claim to be?)。验证时一对一的比对,需要你先向系统声明自己的身份(比如输入账号),系统只把采集到的特征,和你账号对应的唯一模板做比对,最后确认身份是否匹配。
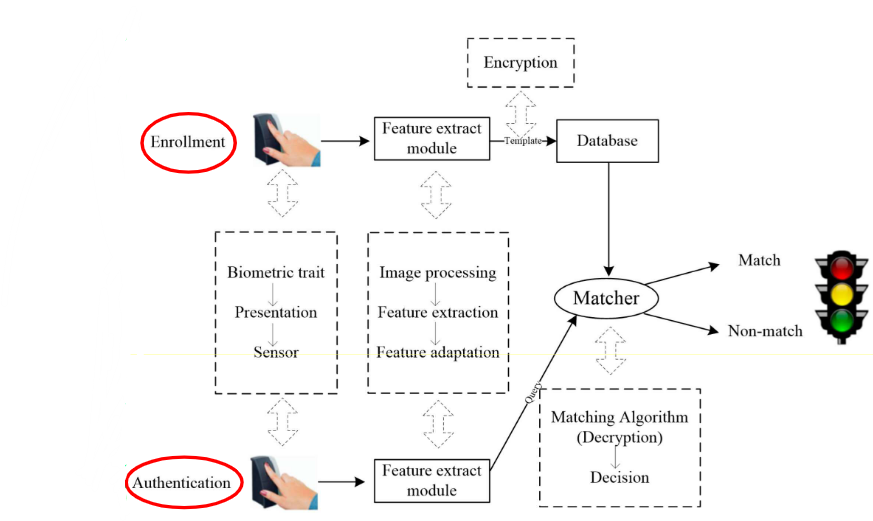
7.2 生物识别的流程
- 注册:采集用户的生物特征数据并将其存储为模板。
- 捕获:在需要进行认证时,扫描生物特征。
- 比对:将捕获的数据与存储的模板进行比对。
- 决策:如果匹配,则授予访问权限;否则,拒绝访问。
其实总结起来就是分为两大基础过程:注册(Enrollment)和认证(Authentication)。
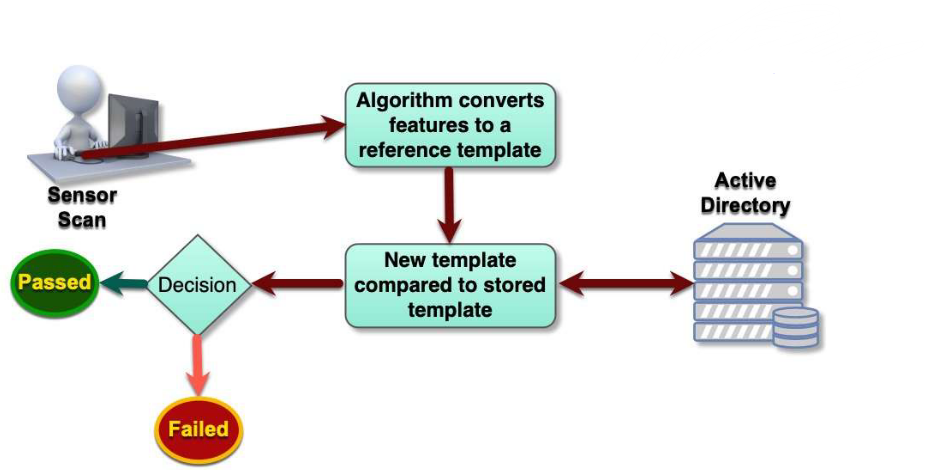
7.2.1 注册(Enrollment)
这是用户使用生物识别前的必经步骤,相当于给系统建立你的专属身份档案:
-
特征扫描:采集用户的生物特征(比如录入指纹、拍摄人脸);
-
模板生成:通过算法把采集到的特征,转化为标准化的参考模板(不是存原始图片 / 特征,而是加密后的特征数据);
-
模板存储:把生成的参考模板,存入系统的活动目录(Active Directory)或专属数据库,完成注册。
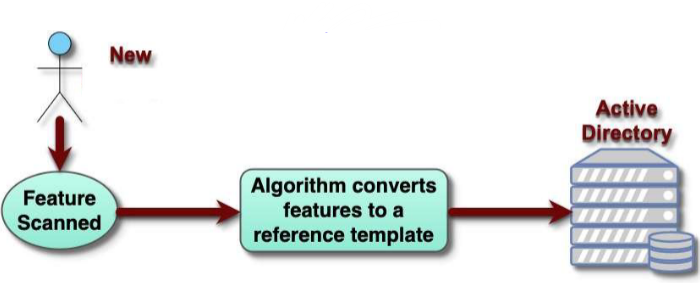
7.2.2 认证(Authentication)
就是我们日常解锁、登录的完整流程,全程毫秒级完成:
-
实时扫描:通过传感器采集用户当前的生物特征;
-
模板转化:用同样的算法,把实时采集的特征转化为比对模板;
-
特征比对:从数据库调取用户注册时存储的参考模板,和新生成的比对模板做匹配;
-
决策输出:如果特征匹配度达标,就认证通过、授予访问权限;匹配失败,就拒绝访问。
7.3 生物识别的类型
生物识别技术分为两类:
-
生理学(Physiological)特征:这些主要包括指纹、手的形状、静脉图案、眼睛(虹膜和视网膜)和脸型。
-
行为(Behavioral)特征:最常见的是语音识别、签名动态(笔的运动速度、加速度、施加的压力等)、击键、语音、手势等。
生理学通常被认为具有保持更稳定的好处。
7.3.1 生理生物识别(Physiological Biometrics)
基于人体天生的、固定的生理特征,也是目前应用最广的类型,核心优势是稳定性强,不会轻易随时间变化,常见类型如下:
| 生物识别类型 | 核心特征说明 |
|---|---|
| 指纹识别(Fingerprint) | 指尖独一无二的脊线和谷线(ridges and valleys)纹路,是普及率最高的生物识别技术 |
| 虹膜识别(Iris) | 瞳孔(pupil)周围彩色环形(colored ring)区域的复杂纹路(patterns),误识率极低,安全性极高 |
| 视网膜识别(Retina) | 眼球底部的血管(Blood vessel)分布特征,唯一性极强,无法伪造 |
| 人脸识别(Face Recognition) | 面部五官的形状、间距、相对位置等特征 |
| 手型几何识别(Hand Geometry) | 手指、手掌(palm)的形状、大小、长度等特征 |
| DNA 识别 | 个人专属的基因序列(genetic code),用于高安全级别的身份核验 |
7.3.2 行为生物识别(Behavioral Biometrics)
基于个人后天形成的、稳定的行为习惯,属于 “隐性” 的生物识别,不容易被复制和盗用,常见类型如下:
| 生物识别类型 | 核心特征说明 |
|---|---|
| 声纹识别(Voice Recognition) | 个人的声音模式、音调(pitch)特征 |
| 击键动态识别(Keystroke Dynamics) | 打字的节奏(rhythm)、速度、按键压力等习惯 |
| 步态识别(Gait Recognition) | 走路的姿态、肢体摆动的特征 |
| 签名分析(Signature Analysis) | 签名的笔画顺序(Stroke order)、书写压力、书写(signing)时长等特征 |
7.4 生物识别在网络安全中的应用
生物识别已经完全融入了我们的生活,从个人设备到公共安全,覆盖了全场景的网络安全需求,最典型的应用包括:
- 访问控制:设备、楼宇、系统的安全登录,比如公司门禁、服务器后台登录;
- 多因素认证:和密码、短信验证码搭配,构成多因素认证(MFA),大幅提升账号安全性;
- 边境与出行安全(Border Security):机场的电子闸机、生物特征护照,用于出入境身份核验;
- 移动设备安全(Mobile Security):手机的 Face ID、Touch ID,银行、支付类 APP 的指纹 / 人脸登录;
- 数字身份核验(Digital Identity Verification):银行、金融科技行业的电子 KYC,远程完成身份实名认证;
- 考勤管理(Time and Attendance Systems):企业的指纹/人脸打卡系统,实现员工考勤与权限管理。
7.5 生物识别的优势与局限性
作为现在主流的认证技术,生物识别有着不可替代的优势:
| 优势 | 详细说明 |
|---|---|
| 便捷性高(Convenient) | 不需要记忆复杂的密码,不需要携带额外的实体凭证 |
| 难以伪造(Hard to Forge) | 独一无二的生物特征,比密码、令牌更难复制和盗用 |
| 永久可用(Always Available) | 不会像密码一样被忘记,也不会像 U 盾一样被弄丢 |
| 访问速度快(Faster Access) | 指纹、人脸解锁都是毫秒级完成,比输入密码更高效 |
| 不可转借(Non-transferable) | 身份和个人直接绑定,无法像密码一样随意分享给他人 |
但同样也有着必须正视的风险和局限:
| 局限 | 详细说明 |
|---|---|
| 隐私风险(Privacy Concerns) | 生物特征属于极度敏感的个人数据,一旦泄露,会造成不可逆的隐私安全问题 |
| 欺骗风险(Spoofing) | 部分技术存在被欺骗(faked)的可能,比如用高清照片、3D 面具绕过人脸检测 |
| 不可撤销性(Non-revocability) | 密码泄露可以随时修改,但指纹、人脸这些生物特征是终身不变的,一旦泄露无法更换 |
| 环境兼容性差(Injuries/Illness) | 身体受伤、生病会影响识别,比如手指划伤会影响指纹识别,感冒失声会影响声纹识别 |
| 部署成本高(Cost) | 高精度的生物识别传感器(sensors)、系统部署,需要较高的前期投入 |
7.6 生物识别的几种方式
7.6.1 指纹识别(Fingerprint)
指纹识别是一种基于个人独特指纹图案来识别和验证身份的生物识别技术。
指纹识别能成为生物识别技术中的主流,主要有两个核心原因:
- 绝对的唯一性:每个人的指纹纹路都是独一无二的,哪怕是同卵双胞胎,指纹也不会完全相同;
- 终身不变性:指纹的核心特征从人出生起就固定,不会随着年龄增长发生本质变化。
而它能普及的核心优势,就是极致的性价比和易用性:部署成本极低(inexpensive to deploy)、使用简单便捷,现在已经被集成到了智能手机、笔记本电脑等许多智能设备中。同时它的适配性极强,既可以做一对一的身份验证(比如手机解锁、APP 登录),也可以做一对多的身份识别(比如刑侦指纹匹配、公司考勤打卡)。
7.6.1.1 指纹结构
这是指纹的基础形态:
-
脊线(Ridges):指纹上凸起的纹路线条(raised lines);
-
谷线(Valleys):两条脊线之间的凹陷空隙(spaces between the ridges)。
而指纹识别的核心就是对于细节点(Minutiae Points)的辨别,其指的是指纹脊线的独特特征,最典型的就是脊线终点(一条脊线突然结束的位置)和脊线分叉点(一条脊线分成两条的位置)。一枚完整的指纹,大约有 30 个可识别的细节点,而两枚指纹需要有足够多的细节点完全匹配,才能被判定为同一枚指纹。所以简单来说,指纹识别并不是看你的指纹 “长得像不像”,而是看这些微观的细节点能不能精准对应上。
7.6.1.2 指纹识别的工作流程
-
图像采集(Image Acquisition)
通过指纹扫描仪采集用户当前的指纹图像,主流的扫描技术有 3 种:
- 光学扫描(optical):最传统的方式,通过光反射成像,常见于考勤机;
- 电容扫描(capacitive):目前手机最主流的方案,通过指纹脊线和谷线的电容差异成像,体积小、功耗低;
- 超声波扫描(ultrasound):高端屏下指纹的方案,通过超声波穿透屏幕,获取指纹的 3D 纹路,抗干扰能力强,能防假指纹膜。
-
预处理(Preprocessing)
- 图像增强(Image enhancement):例如降噪(noise reduction)、归一化(normalization),这样可以使纹路更清晰。
- 二值化(Binarization):将灰度图像(grayscale images)转换为只有黑白两色的二进制图像,让脊线和谷线的边界更清晰。
- 细化(Thinning):将纹线厚度缩减至单个像素(pixel)宽度,方便后续提取细节点。
-
特征提取(Feature Extraction)
这一步是指纹识别的核心,算法会从预处理后的图像中,提取出用于比对的核心特征,包括:
- 指纹的细节点(终点、分叉点)和脊线走向;
- 指纹的奇异点(比如指纹的核心中心点(core points)、三角区点(delta points)。
-
特征匹配(Matching)
使用纹线相关性(ridge correction)、基于 minutiae 的匹配(minutiae-based matching)或基于模式的匹配(pattern-based matching)算法把实时提取到的指纹特征,和注册时存储在数据库里的加密模板做比对,计算两者的匹配度。
-
决策输出(Decision)
系统根据匹配得分和预设的阈值(threshold),做出最终判断:如果匹配度达标,就认证通过,授予访问权限;如果匹配度不达标,就拒绝访问。
7.6.1.3 指纹识别的匹配算法
算法是指纹识别的核心,决定了识别的速度、准确率和抗干扰能力,主流的算法分为 3 类:
-
基于细节点的匹配(Minutiae-Based Matching)
行业最通用的算法,逻辑是比对两枚指纹的细节点的位置、方向、类型是否匹配。
优点:逻辑简单、适配性强。
缺点:对指纹图像质量(quality)非常敏感(sensitive),手指有划伤、污渍就会影响准确率。
-
基于相关性的匹配(Correlation-Based Matching)
核心是把两枚指纹的脊线做对齐(aligning),计算纹路的相似度。
优点:对完整指纹的匹配准确率高,
缺点:计算量极大(Computationally intensive),对设备算力要求高,而且对指纹的旋转、按压偏移很敏感。
-
深度学习模型(Deep Learning Models)
目前高端设备的主流方案,用卷积神经网络(CNNs)做特征提取和匹配。
优点:抗噪、抗畸变能力极强(Robust to noise and distortion),哪怕是低质量的指纹图像也能精准识别,同时还能实现活体检测,防范假指纹欺骗,是未来的主流发展方向。
7.6.1.3 指纹识别的优缺点与未来趋势
作为普及率最高的生物识别技术,其也面临着诸多挑战和技术难点。指纹识别并不是 “万能的安全方案”,它有不可替代的优势,但也有必须正视的安全短板。
优势:
- 成本低、识别速度快,部署门槛极低**(Low cost and fast)**;
- 易集成、使用简单,用户学习成本为零**(Ease of integration and easy to use)**;
- 非侵入式识别,不会给用户带来身体不适**(Non-invasive)**。
缺点:
- 指纹极易泄露(easier to steal):我们的手指碰过的所有东西,都会留下完整的指纹(left on),很容易被他人获取;
- 可被伪造欺骗:通过明胶、硅胶等材料,可以制作出高精度的假指纹膜(copies of fingerprints),能骗过部分低端的指纹识别系统;
- 环境与状态影响大(Environment and usage):手指划伤、掉皮、有污渍、潮湿,或者按压的力度、角度不对,都会影响识别成功率;
- 泄露后无法重置(Cannot be reset):密码泄露了可以随时修改,但你的指纹是终身不变的,一旦特征泄露,就永远存在安全风险;
- 对图像质量要求高(Requires good-quality images):想要达到最优的识别效果,必须依赖高质量的指纹图像,对采集设备和使用环境有要求。
因此针对指纹识别的短板,行业也在不断迭代技术,未来的核心发展方向主要有两个:
-
多模态生物识别融合(Multimodal Biometrics)
把指纹识别,和人脸识别、虹膜识别等其他生物识别技术结合,形成多因子认证。比如重要账号的登录,需要 “指纹 + 人脸” 双重验证,既保留了指纹的便捷性,又解决了单一指纹容易被伪造的问题,大幅提升安全性。
-
AI与机器学习深度赋能(AI and Machine Learning)
用 AI 算法优化特征提取能力,哪怕是低质量、有破损的指纹,也能实现精准识别;同时用 AI 做活体检测和防欺骗,能精准区分真实手指和假指纹膜,甚至能识别指纹的血流、心率等活体特征,从根源上防范伪造攻击。
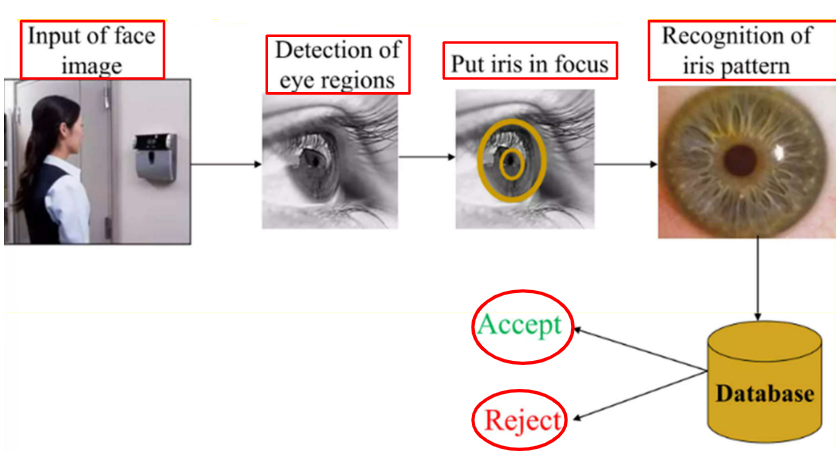
7.6.2 虹膜识别(Iris)
虹膜,就是我们眼睛里瞳孔周围的有色环形区域,每个人的虹膜纹理都具备独一无二的特征,哪怕是同卵双胞胎、同一个人的左右眼,虹膜特征都存在显著差异。
虹膜识别技术,就是一项通过采集、分析、比对虹膜纹理特征完成身份认证的生物识别技术,它是目前公认精度最高的生物识别技术,原因在于虹膜中可被测量的有效特征信息量,远超指纹、人脸等其他生物特征,误识别概率极低。识别距离可控制在 1-3 英尺(约 30-90 厘米),采集所用的光源强度和日常电视遥控器的红外光相当,对人眼友好无伤害。
目前已在医疗行业广泛落地,核心用于保护患者电子病历的访问权限。
7.6.2.1 虹膜识别的工作流程
-
图像采集(Image Acquisition)
通过专用相机(specialized cameras)采集眼部的高清图像。为了提升虹膜纹理的可见度(enhance pattern visibility)、减少虹膜本身颜色对识别的干扰(reduce interference from eye color),绝大多数商用设备都会采用近红外(NIR)光进行拍摄,能清晰捕捉到人眼不可见的虹膜深层纹理细节。
-
预处理(Preprocessing)
采集到的原始图像无法直接用于比对,需要先完成标准化的预处理,分为三个核心动作:
- 分割(Segmentation):将虹膜区域从整张眼部图像中精准分离,与眼白(sclera)(也就是巩膜)、瞳孔、眼睑(eyelids)、睫毛等无关区域区隔,锁定核心识别范围;
- 归一化(Normalization):将环形的虹膜转换成统一规格的矩形区块(rectangular block),消除拍摄距离、角度、瞳孔缩放带来的形变影响,保证后续分析的一致性;
- 图像增强(Image Enhancement):优化图像对比度(contrast)、降低画面噪点,让虹膜的纹理细节更清晰(better pattern visibility),最大程度减少后续识别的误差。
-
特征提取(Feature Extraction)
这是虹膜识别技术的核心环节。算法会从处理完成的虹膜图像中,识别并编码(Identify and encode)出独属于该虹膜的纹理特征,重点分析纹理的结构(texture)、频率(frequency)、空间分布(spatial details)等核心细节,最终生成一个加密的数字特征模板。
-
匹配(Matching)
将新生成的用户虹膜特征模板,与数据库中提前存储的授权用户模板(stored templates)进行比对。算法会通过汉明距离(Hamming distance)、相关性(correlation)计算等方式,精准算出两个模板的相似度得分,量化两者的匹配程度。
-
决策输出(Decision)
系统会根据预设的相似度阈值,完成最终的身份判定:如果匹配度达到阈值要求,就判定为授权本人,完成认证放行(Accept access);如果匹配度未达阈值,就直接拒绝访问(Reject access),完成整个身份校验流程。
7.6.2.2 虹膜识别技术的核心算法
技术的落地离不开核心算法的支撑,目前虹膜识别领域的主流算法分为三类:
- Daugman 算法:通过 Gabor 小波对虹膜纹理进行编码和匹配,是目前绝大多数商用虹膜识别系统的核心基础。
- 基于小波的技术(Wavelet-Based Techniques):这类算法重点分析虹膜纹理的频率和方向(orientation)特征,能精准捕捉纹理的细微差异,大幅提升识别的抗干扰能力。
- 深度学习模型:随着 AI 技术的发展,以 CNN(卷积神经网络)为代表的深度学习模型被广泛应用,能在光照不佳、存在遮挡等复杂场景下,完成更稳定的特征提取和匹配。
7.6.2.3 虹膜识别的优缺点
作为高安全级别的身份认证技术,虹膜识别在网络安全场景中有不可替代的优势,但也存在尚未完全解决的落地短板。
优势:
- 超高识别精度(High Accuracy):拥有极低的错误接受率(false acceptance rate, FAR)和错误拒绝率(false rejection rate, FRR),误识别概率远低于指纹、人脸等其他生物识别技术,是当前安全等级最高的生物认证方式之一。
- 非侵入式认证(Non-Intrusive):无需和设备进行物理接触(physical contact),在有效距离内即可完成采集,使用体验更卫生友好,同时也避免了接触式设备被篡改、污染的安全风险。
- 唯一性与终身稳定性(Unique and Stable):每个人的虹膜纹理在出生后就已固定,终身不会发生变化,且个体差异极大,很难被批量仿冒,具备极强的防伪属性。
缺点:
- 使用技术门槛高(Not easy to use)
- 系统集成(System integration)复杂:将虹膜识别系统与现有的门禁、数据访问、业务系统做深度集成,需要复杂的适配开发,对技术团队的专业能力要求较高。
- 成本门槛高(Cost issue):高质量的虹膜识别系统,需要专用的高精度采集相机、适配性极强的算法,硬件与研发成本远高于普通的人脸、指纹识别设备,难以大规模民用普及。
- 采集环境要求严苛:光照不佳(Poor lighting)、拍摄时的运动模糊(motion blur)、睫毛(eyelashes)/眼睑的遮挡(occlusions)、眼镜反光等情况,都会直接影响图像采集质量,进而导致识别失败。
- 存在仿冒攻击风险(Spoofing Risks):高分辨率的虹膜打印图片、特制的隐形眼镜(contact lenses),有可能骗过部分安全等级不足的识别系统,存在伪造攻击的安全隐患。
- 可扩展性(Scalability):在大规模用户数据库中完成快速匹配,需要极高效率的算法支撑。
- 环境依赖问题(Environment Dependence):同时在户外、光线变化剧烈的场景下,识别稳定性会大幅下降。
7.6.3 视网膜扫描识别(Retinal Scanning)
视网膜扫描技术是基于眼球生理特征的高安全级生物识别技术,以人眼后部视网膜上独一无二的血管分布模式为识别依据。其安全性和精准度都是最顶尖的,但由于使用条件限制,它并未成为主流的民用生物识别方案。
7.6.3.1 完整工作流程
整个识别过程分为 4 个步骤:
- 图像采集(Image Capture):视网膜扫描仪向人眼发射低强度红外光(infrared light),光线照亮(illuminate)视网膜的血管;由于血管比周围组织(surrounding tissues)吸收更多光线,血管的轮廓与分布会被清晰凸显(stand out)。
- 模式提取(Pattern Extraction):扫描仪捕捉视网膜血管分布的数字图像,完成原始数据的采集。
- 特征分析(Feature Analysis):对采集到的、独一无二的血管分布模式(vascular patterns)进行分析,最终编码成标准化的生物识别模板。
- 匹配比对(Matching):将新采集的视网膜数据,与数据库中预存的生物模板进行比对,最终完成身份验证或身份识别。
7.6.3.2 视网膜扫描识别的优缺点
优点:
- 超高准确率:拥有极低的误接受率与误拒绝率,识别精度处于行业顶尖水平。
- 强抗伪造能力(Security):视网膜血管模式复杂度极高,很难被伪造、欺骗。
- 不可复制性(Non-Replicable):识别特征位于眼球内部,几乎不可能被复制盗用。
劣势:
- 对用户配合度要求高(User Cooperation):识别时需要用户保持静止(remain still),聚焦特定点(focus on a specific point)数秒才能完成扫描。
- 设备成本高昂(Equipment Costs):需要专用的专业硬件,部署和使用成本远高于普通生物识别设备。
- 使用体验受限(Health Concerns):设备需要贴近眼部(proximity of the scanner),部分用户会产生不适感,接受度较低。
- 环境与场景敏感(Environmental Sensitivity):光照条件、用户的轻微移动,都会直接影响扫描质量;用户佩戴眼镜、患有白内障时,识别效果会大幅下降,甚至无法完成识别。
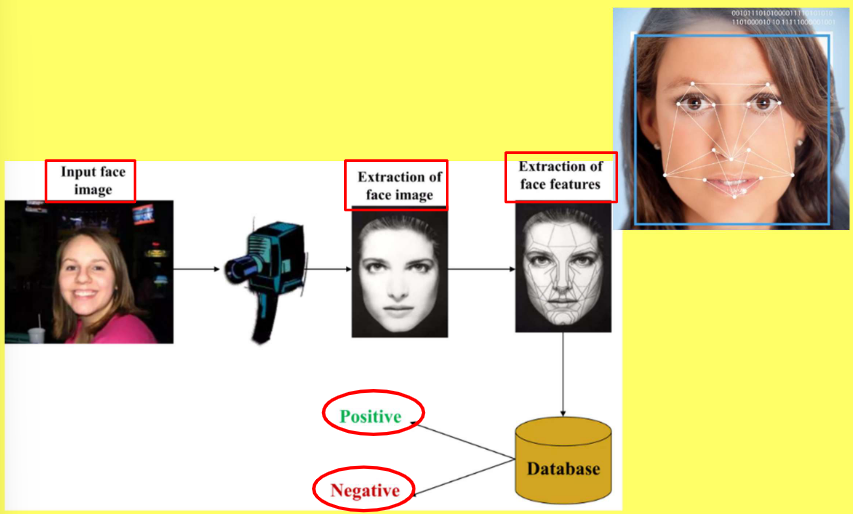
7.6.4 人脸识别(Face Recognition)
人脸具有距离和角度方面的特征及测量数据,这些数据可以在二维或三维空间中计算,以确定一个人的身份。它的精度虽不及指纹、视网膜识别,但拥有不可替代的民用优势:
- 采用大众熟悉的数字照片采集流程,用户接受度(accustomed to)和使用舒适度极高。
- 支持非接触式识别,可远距离完成(can be performed from a distance),无需用户触碰设备,适配场景极广。
- 核心识别特征包括眼间距、鼻宽、眼窝深度(Depth of the eye sockets)、颧骨(cheekbones)形状、下颌线(jawline)长度等面部关键参数。
- 主流技术路线分为两类:整体人脸识别(分析整张人脸,匹配目标特征)、基于特征的人脸识别(提取人脸关键识别数据,生成模板后完成比对)。
7.6.4.1 人脸识别的工作流程
-
图像采集(Image Acquisition):通过 2D 或 3D 相机,捕捉目标的人脸图像,完成原始数据采集。
-
预处理(Preprocessing):使用 Haar 级联(Haar cascades)、方向梯度直方图(Histogram of Oriented Gradients, HOG)、MTCNN 等深度学习检测器,识别并隔离图像中的人脸区域,排除无关背景的干扰。
-
特征提取(Feature Extraction):提取人脸的独有特征,主流技术方案包括了
- 特征脸(PCA):Statistical analysis of facial features.
- 局部二值模式(Local Binary Patterns, LBP):Texture-based features.
- 深度学习模型:CNNs to extract high-dimensional, robust features (e.g., FaceNet, VGGFace).
-
匹配比对(Matching):通过余弦相似度(cosine similarity)、欧氏距离(Euclidean distance)等相似性度量方法,将新提取的人脸特征(extracted features),与数据库中存储的模板进行比对。
-
决策判定(Decision):基于特征比对的相似度结果,最终完成身份确认或真实性核验。
7.6.4.2 人脸识别的核心算法
多年来,人脸识别技术取得了显著的发展,人们采用了多种算法来提高其准确性和鲁棒性。以下是人脸识别领域的主要算法。
- 主成分分析(Principal Component Analysis, PCA)
- 原理:一种降维(dimensionality reduction)技术,通过将人脸图像投影(project)到低维空间(lower-dimensional space),识别人脸数据中的核心模式。
- 核心特点:
- 可捕捉人脸的全局变化(global variations);
- 在小数据集(small datasets)场景下,计算效率极高(computationally efficient)。
- 局限性:
- 对光照、姿态(pose)、表情的变化非常敏感;
- 在大规模(large-scale)、实时(real-time)系统中,识别效果不佳。
- 线性判别分析(Linear Discriminant Analysis, LDA)
-
原理:通过寻找特征的线性组合(linear combinations),最大化不同身份之间的可分性(separability),区分不同人脸。
-
核心特点:
- 可降低类内方差(within-class variance),提升类间方差(between-class variance);
- 在多分类(multi-class)人脸识别场景下,效果优于 PCA。
-
局限性:
- 高维(high-dimensional)数据下计算成本极高;
- 需要大规模标注数据集(labeled datasets),才能完成有效训练。
- 局部二值模式(Local Binary Patterns, LBP)
- 核心原理:基于纹理(texture-based)的算法,将人脸划分为多个区域,提取每个区域的局部纹理(local texture)特征,用于后续比对。
- 核心特点:
- 对光照变化的鲁棒性强(Robust);
- 计算成本低,适配实时识别系统。
- 局限性:
- 对姿态、表情(expression)变化敏感;
- 仅能捕捉局部特征,会忽略人脸的全局结构。
- 方向梯度直方图(Histogram of Oriented Gradients, HOG)
- 核心原理:一种图像描述子(image descriptor),可捕捉人脸的边缘(edge)和梯度(gradient)结构信息,多用于人脸检测和特征提取环节。
- 核心特点:
- 在复杂背景(cluttered backgrounds)下的人脸检测效果优异;
- 可与支持向量机(Support Vector Machines, SVMs)等分类器配合使用。
- 局限性:
- 本身无法很好地处理姿态和尺度变化;
- 识别精度不及深度学习方法。
- 卷积神经网络(Convolutional Neural Networks, CNNs)
- 核心原理:从人脸图像中,提取分层(hierarchical )的层级特征(例如基础的边缘、纹理,到复杂的人脸形状、结构)。
- 代表模型:AlexNet、VGGFace、ResNet。
- 核心优势:
- 对姿态、光照、表情变化的鲁棒性极强;
- 在大规模数据集下,识别精度处于行业顶尖水平。
- 深度度量学习(Deep Metric Learning)
- 核心原理:学习人脸图像到特征空间的映射(mappin),让同一个人的人脸特征在特征空间中距离更近,不同人的特征距离更远(far apart),大幅提升区分度。
- 代表模型:FaceNet、ArcFace
- 技术细节:FaceNet 使用三元组损失函数(triplet loss function)优化嵌入向量(embeddings),ArcFace 采用角边距损失(angular margin loss),进一步提升特征的区分(discrimination)能力。
- Fisher faces Description
- 结合 PCA 和 LDA 的鲁棒算法,可应对光照、表情变化,在大数据集下效果有限。
- 弹性束图匹配(Elastic Bunch Graph Matching, EBGM):通过 Gabor 小波特征构建人脸图模型,基于图节点(nodes)的相似度完成匹配;对中等姿态变化(moderate pose variations)鲁棒,也就是较为稳健,但计算量极大(computationally intensive)。
7.6.4.3 3D人脸识别技术
- 通过传感器(sensors)捕捉人脸的立体形状,识别精度更高;
- 精度不受光照影响,甚至可以在完全黑暗的环境中(in the dark)完成扫描识别;
- 支持多角度识别(multiple angles),可从多个姿态完成目标识别,适配性更强。
3D人脸的工作流程主要有以下几个步骤:
- 检测(Detection):通过专用人脸识别相机直接采集 3D 人脸图像,也可通过扫描 2D 照片完成采集。
- 对齐(Alignment):算法确定人脸的位置、角度和尺寸,只要人脸朝向与相机的角度在 90 度以内,即可完成识别。
- 测量(Measurement):对人脸形状进行亚毫米级(sub-millimete)的精准测量,生成对应的标准化识别模板。
- 匹配(Matching):在数据库中搜索匹配新生成的模板;若数据库全为 3D 图像,可直接完成匹配;若数据库包含 2D 图像,算法会将 3D 人脸图像转换为 2D 后,再完成匹配比对。
- 核验/识别(Verification or identification):根据场景需求,完成身份核验或人脸识别。
7.7 生物识别的安全问题
7.7.1 生物识别错误率(BIOMETRICS ERROR RATES)
判断一套生物识别方案是否靠谱,核心看三个关联的错误率指标:
- 错误拒绝率(False rejection rates, FRR):称为
- 错误接受率(false acceptance rate, FAR):称为
- 交叉错误率(crossover error rate, CER):指 FAR 和 FRR 数值相等的那个临界点,这个指标是衡量生物识别系统综合性能的核心标准 ——CER 数值越低,代表这套系统的整体识别精度越高。
这里有一个关键的权衡逻辑:当我们调高生物识别传感器的灵敏度,想要更严格地拦住非法用户时,FRR 会随之上升,FAR 会随之下降,如下图:
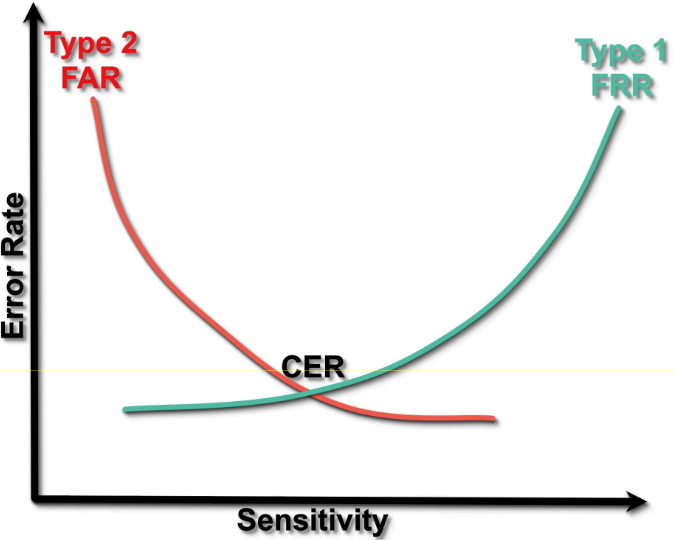
换句话说,你越想严防外人闯入,就越容易把合法的用户拦在门外,二者永远是此消彼长的关系,不存在 “既零误放、又零误拒” 的完美方案。
7.7.2 生物识别错误和欺骗(Biometric Errors and Deception)
很多人会把生物识别的 “识别失败” 一概而论,但在安全领域,我们首先要区分两个完全不同的场景:
- 错误(Errors):用户没有任何欺骗系统的意图,完全是系统自身出现了识别偏差;
- 欺骗(Deception):用户主动伪造、篡改信息,刻意想要骗过系统完成攻击。
有很多容易被忽略的因素,会直接影响到生物识别系统的实际表现,甚至带来安全隐患:
- 厂商参数的 “水分”(Vendor Claims for FARs and FRRs):厂商宣传的 FARs 、FRRs 指标,大多是在理想实验室环境下测试得出的,实际使用中,受环境、用户状态影响,指标往往会大打折扣,存在明显的夸大。
- 注册失败率(Failure to Enroll, FTE):指用户根本无法在系统中完成生物特征注册的情况。比如长期从事体力劳动的工人指纹磨损、老年人指纹退化,都可能导致无法录入指纹(poor fingerprints)。
- 不可控的外部影响因素(Other Factors Affecting Performance):包括用户的年龄、种族、性别、职业等人口统计(Demographics)特征;生物特征模板的使用时长(Template Age);用户的生理变化(Physiology)(受伤、生病、外貌变化)、外观改变(Appearance)(发型、眼镜、妆容、配饰);甚至验证时的行为状态(Behavior)(紧张、姿势不对、环境干扰),都会影响识别的准确率和稳定性。
7.7.3 生物识别系统的常见攻击方式
很多人觉得生物识别 “没法破解”,但在攻击者眼中,生物识别系统有多个可被利用的攻击面,常见的攻击方式包括:
- 伪造攻击(Presentation Attacks):最常见的攻击方式,攻击者通过制作指纹膜、3D 人脸面具、高清照片等人工制品(artifact),模仿(mimic)合法用户的生物特征,骗过传感器完成认证。
- 传感器输出拦截(Sensor Output Interception):在数据传输环节,攻击者截获传感器采集的生物特征数据、系统存储的参考模板(reference templates),在后续攻击中直接复用这些数据,绕过采集环节完成攻击。
- 参考模板与数据库攻击(Reference and Database):利用系统漏洞(Vulnerabilities),非法访问存储生物特征模板的数据库,窃取、篡改、批量导出用户的生物数据,不仅能用于仿冒攻击(misuse for attacks),还可能造成大规模的数据泄露。
- 注册环节完整性破坏(The integrity of the Enrollment):在用户注册环节做手脚,攻击者用自己的生物特征,替合法用户完成注册,直接获得系统的授权访问权限,从根源上绕过认证。
- 内部威胁(Insider Threats):系统内部的工作人员,单独或与外部攻击者勾结,窃取、滥用用户的生物特征模板,发起网络攻击,这类攻击往往隐蔽性更强、危害更大。
所以说,生物识别并不是绝对安全的认证方式,它的安全性,最终取决于传感器的质量、识别算法的可靠性,以及整套系统的安全架构。
7.7.4 生物识别的优缺点
前面其实已经写过生物识别的一部分优缺点,这里来讲讲整套生物识别系统还有哪些优势,以及哪些无法规避的安全缺陷。
首先是生物识别精准击中了传统密码的痛点,带来了三个不可替代的优势:
-
破解难度远高于传统密码**(Difficult to Hack)**
不同于可以被暴力猜测、字典攻击破解的密码,指纹、人脸等生物特征无法被凭空猜解(guessed),想要直接从算法层面破解(cracked)生物识别系统,难度远高于攻破一套密码体系,这是它最核心的安全优势。
-
极致的使用便捷性**(Convenient)**
生物识别的扫描验证速度,远快于(a lot faster)手动输入复杂密码;同时它彻底解决了记忆多组强密码(multiple strong passwords)、频繁忘记密码的烦恼,不用再为了符合安全规则绞尽脑汁设计密码,也不用再面对 “密码错误” 的挫败感(frustration of constantly forgetting them)。
-
永久随身,随时可用**(Always Available)**
我们可能会把手机、门禁卡、钥匙落在家里,但永远不会 “忘带” 自己的手指、人脸。只要有生物识别扫描仪,无需任何额外的认证设备,随时随地都能完成身份验证,彻底摆脱了对物理介质的依赖。
但同时便捷的背后,是生物识别与生俱来、无法规避的安全缺陷,这些风险也决定了它无法完全替代传统密码:
-
极易滋生安全麻痹,让使用者放松警惕**(Complacency)**
智能手机上的生物识别太过便捷,很容易让我们养成 “一键验证” 的肌肉记忆,在登录、支付等关键场景变得鲁莽大意(recklessness),忽略了验证环境的风险。要知道,一套生物识别系统的安全上限,最终取决于使用者本身的安全意识,再精密的系统,也挡不住使用者毫无防备的随意验证。
-
泄露即永久失效,不可逆的高风险**(High risk)**
这是生物识别最致命的缺陷:你的密码一旦泄露,随时可以修改、重置,彻底解决风险;但指纹、人脸、虹膜这些生物特征,是与生俱来、终身无法更改的。如果你的生物特征数据被窃取、泄露,就会造成永久性的安全受损(permanently compromised),终身都面临被仿冒冒用的风险。
-
极易被复制克隆,仿冒门槛远低于想象**(Duplication/Cloning)**
很多人觉得生物特征 “只有自己有”,但事实恰恰相反:相比门禁卡、物理钥匙,生物凭证反而更容易被获取和复制。我们日常接触的键盘、门把手、水杯,都会留下完整的指纹,攻击者可以轻松提取复刻,甚至通过高清照片就能重建指纹模型;而我们发布在社交平台的自拍,也能被用来制作 3D 人脸模型,轻松骗过大量人脸识别系统。
而我们常听到 “生物识别比密码更安全” 的说法,但二者从来没有绝对的优劣,只有适用场景的区别。下面表格从 6 个维度进行比较:
| 对比维度 | 生物识别 | 传统密码 |
|---|---|---|
| 基础安全性(Security) | 高(难以凭空窃取、暴力猜解) | 中等(可被暴力破解、撞库猜解) |
| 使用便利性(Convenience) | 高(无需记忆,验证速度快) | 低(需要记忆,输入繁琐) |
| 可撤销可更换性(Revocability) | 不支持(无法修改自身生物特征) | 完全支持(可随时修改、重置) |
| 仿冒难度(Spoofing) | 有一定门槛,需要制作对应仿制品 | 极低,一旦泄露即可直接冒用 |
| 部署使用成本(Cost) | 高(需要专用传感器、配套硬件算法) | 低(仅需软件逻辑即可实现) |
7.7.5 生物识别的未来发展趋势
- 非接触式生物识别(Contactless Biometrics):后疫情时代,人脸、虹膜、语音等非接触式的生物识别方案,成为落地的主流方向,既提升了使用便捷性,也降低了接触带来的卫生与仿冒风险。
- AI/ML深度赋能(AI/ML in Biometrics):通过人工智能与机器学习算法,持续优化识别模型,大幅提升识别准确率,降低 FRR、FAR 等错误率(reduce error rates),同时提升对伪造攻击的防御能力。
- 行为生物识别(Behavioral Biometrics):基于用户的打字习惯、触屏手势、行走步态、语音语调等行为特征,实现持续的身份认证,而非单次验证,大幅提升攻击的难度。
- 生物特征区块链(Biometric Blockchain):通过区块链的**去中心化(decentralized)**特性,实现生物特征数据的安全存储,避免中心化数据库被拖库导致的大规模数据泄露,从存储环节降低安全风险。
8 密码学、数字签名和数字证书(Cryptography, Digital Signature and Digital Certificates)
8.1 密码学
8.1.1 密码学基础
密码学是信息安全防护体系的核心手段之一,在安全生命周期中属于防护(Protect)环节,通过访问控制、防火墙、加密技术等持续保护数据安全。在开放通信场景(如互联网)中,数据传输会面临窃听者(Snooper)的拦截风险,而密码学正是解决这一问题的关键技术,其。利用数学技术保障通信与信息安全的科学与艺术,将可读信息转换为不可读格式(converting the message from a readable format to non-readable),使拦截者无法解读内容。
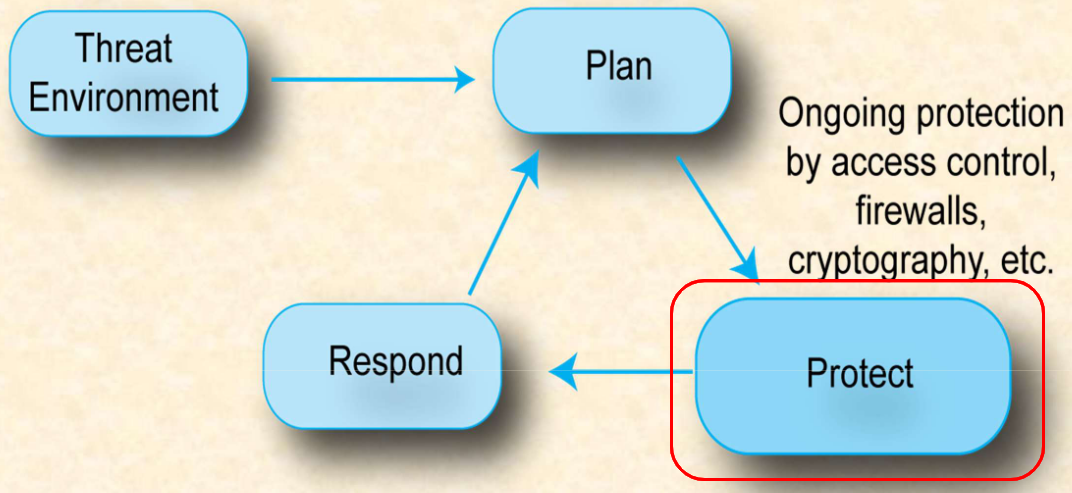
过程如下:
- 威胁环境(Threat Environment)驱动安全规划(Plan)
- 防护(Protect)环节落地加密等技术手段
- 事件发生后进入响应(Respond)阶段,再迭代优化安全规划
我们也需要先了解一些概念和术语:
| 术语 | 定义 |
|---|---|
| 明文(Plaintext) | 未加密(not encrypted)的原始可读数据 |
| 密文(Ciphertext) | 加密算法输出(output of an encryption algorithm)的不可读数据 |
| 密码算法(Cipher) | 执行加密/解密的数学函数 |
| 密钥(Key) | 算法用于加密/解密(decrypt)的字符 / 比特序列(sequence) |
| 加密(Encryption) | 明文
|
| 解密(Decryption) | 密文
|
8.1.2 密码分析(Cryptanalysis)
密码分析学是一个试图攻破密码系统并将加密信息恢复到其原始形式的过程。密码分析的目标是利用各种数学算法来破译密文。

其目的是通过数学算法破译密文,常见攻击方式包括:
- 暴力破解(Brute Force Attack):尝试所有可能的密钥组合
- 字典攻击(Dictionary Attack):利用预设单词/常用密码库尝试破解
- 彩虹表攻击(Rainbow Table Attack):预先计算哈希值与明文的映射表,加速破解
8.1.3 密码学的主要类型
密码学主要分为三类,其差异主要在于密钥的使用方式:
| 类型 | 密钥特点 |
|---|---|
| 对称加密(Symmetric Encryption) | 仅使用一个密钥,加密和解密用同一把密钥 |
| 非对称加密(Asymmetric Encryption) | 使用一对密钥(公钥 + 私钥),公钥加密、私钥解密 |
| 哈希(Hashing) | 无密钥,单向不可逆运算 |
8.1.4 加密和解密的过程(Encryption and Decryption Process)
-
加密(Encryption)
用加密算法以及密钥,将明文(可读数据)转换为密文(不可读格式),目的是防止未经授权的人员访问敏感信息。例如,如果明文= “HELLO”,加密后可能会变成 “XJ#94@K”(密文)。
-
解密(Decryption)
用解密算法,一般是逆向数学函数(reverse mathematical function),和匹配密钥,将密文还原为明文。目的是使授权用户恢复可读数据。示例:密文 = “XJ#94@K” , 解密后还原成 “HELLO”。
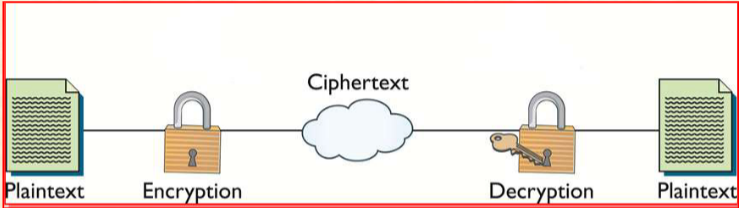
用符号来表示就是:
- M 为明文;C 为密文;E 为加密;D 为解密;K 为密钥。
对于哈希加密,过程可以表示为:
对于对称加密,过程可以表示为:
对于非对称加密,过程可以表示为:
8.1.4.1 加密算法(cryptographic algorithm)
加密算法就是由用于加密和解密信息的数学步骤组成的。
密码(cipher)的类型有以下几种:
| 类型 | 原理 |
|---|---|
| 替代密码(Substitution ciphers) | 字符/位替换(Replace)(如A→D,B→E) |
| 置换密码(Transposition ciphers) | 字符位置重排(rearrange)(如”HELLO”→ “OLLEH”) |
| 乘积密码(Product ciphers) | 结合替换(substitution)、置换(permutation)与模运算(modular arithmetic)的复合算法 |
密钥(key):
密钥是在加密和解密过程中使用的特殊数据片段。算法保持不变,但使用不同的密钥。密钥越复杂,系统的安全性就越高。
因此密钥的长度是十分重要的,由此我们可以得到一个安全系数公式:
- 组合数规律:密钥每增加 1 位,可能组合数翻倍;8 位密钥仅 256 种组合,极易被破解。假设有一串56 位密钥,按每秒尝试 100 万次密钥计算,则理论的破解时间约 2285 年;当提高到64 位密钥,破解所需时间为约 585000 年。然而现代计算机算力更强,黑客可利用大量机器并行攻击,实际破解难度远低于理论值
8.1.4.2 加密实现方式
明文可以通过比特流(Bit Stream)或分组密码(Block Cipher)的方法进行加密。
- 比特流:每个明文比特一次转换为一个密码比特(或字节),进行实时处理。RC4 是最广泛使用的流密码(但是因 WEP 漏洞而被弃用)。
- 分组密码:消息被分成块(例如,8 位或 16 位的块组),每个块都使用算法和密钥转换为加密的密码比特块。DES(64 位块,已弃用)和 AES(128 位块,现行标准)是分组密码的常用方式。
常见的加密模式主要由两种:
- 电子密码本(Electronic Code Book, ECB):每个块单独加密。
- 密码块链(Cipher Block Chaining, CBC):下一个输入取决于上一个输出(链式反馈)。
8.1.5 密码系统(Cryptosystem)
密码系统也叫加密系统,是用于通过密码学对消息进行加密和解密的完整工具包,包含了所有程序、协议、加密算法及操作指令。
关于加密算法的选择完全取决于具体的应用场景:
- 实时数据流加密(Encrypting streams of data in real-time):例如比如视频通话、直播,就需要低延迟、高效率的算法。使用流密码(ChaCha20),因为其低延迟的特性。
- 本地文件加密(encryption files on your local computer):比如硬盘数据、文档,更侧重长期存储的安全性。因此一般使用对称加密(AES-256),加解密速度快,吞吐量大,适合大量数据保护。
- 网络通信加密(Network communication encryption):比如消息传输、密钥交换等场景下,一般使用公钥加密(RSA-2048),无需预先共享密钥,能安全解决密钥分发问题。
密码学用于实现信息安全的目标:
-
保密性(Confidentiality):只有授权人员可以访问/读取信息;
-
完整性(Integrity):保证信息在传输或存储过程中未被篡改,发送的信息与接收的信息一致;
-
认证(Authentication):使用数字签名(using digital signature)确认信息发送者(Guarantee of originator)的真实身份,同时验证电子传输的真实性;
-
不可否认性(Non-repudiation):通过数字签名确保信息发送方(Originator of information)无法否认(deny )自己发送过内容,以及无法否认内容是原始状态。
8.1.6 加密算法详解
8.1.6.1 私钥加密(Secret-key Cryptography, SKC)
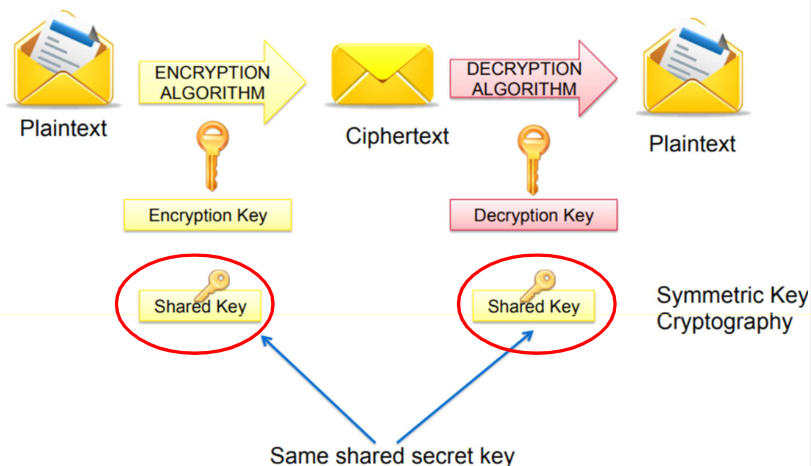
SKC 就是对称加密算法,其使用单个密钥对信息进行加密和解密。主要的问题就是需要保证私钥不会被泄露,因此需要一种方式使双方能够在不担心被窃听的情况下进行通信。
-
SKC 的优势有:
- 速度:算法计算效率高,使其适合加密大量数据。
- 简单性(Simplicity):与非对称加密相比,更容易实现。
- 广泛采用(Wide Adoption):用于许多实际应用中,如 SSL/TLS、磁盘加密和文件加密。
-
当然其劣势也十分明显:
- 密钥分发(Key Distribution):在各方之间安全地共享秘密密钥是一个主要挑战。
- 可扩展性(Scalability):在有许多用户的网络中,如何管理每对用户独特的秘密密钥是一个难题。
常用的对称加密算法有:DES、3DES、AES、CAST、RIVEST、Blowfish、IDEA 等。DES 是第一个用于商业应用的对称密钥算法,而 3DES 是替代 DES 的临时解决方案。AES 是当前的黄金标准,广泛用于世界各地的众多商业和政府应用程序。
(1) 数据加密标准(Data Encryption Standard, DES)
采用64位块加密,这意味着64位的明文会生成64位的密文。而密钥的有效长度为56位,在每个64位分组里基于密钥执行16次替换和置换(一种转置形式),以此实现加密和解密。
不需要知道其具体的工作流程,只需要了解即可,考试只会考概念性的东西。
尽管大多数现代应用中已被 AES 取代,但是DES在密码学上的影响也是不容小觑的,其具有一定的优势:① 在硬件和软件中实现简单且高效;② 经过充分研究和理解,使其成为密码学的良好教学工具,并对现代密码学产生了影响。但是由于密钥长度较短(56 位),因此DES极其容易受到暴力攻击。并且据说美国政府通过使用固定的 S 盒留有了潜在的后门。
接下来讲一下 2DES,其实就是使用 DES 两次,也就是使用两个密钥(2×56=112 位):
虽然两次DES使用的密钥均不相同,但是对于两对已知明文/密文的密钥,双 DES 可以以极高的置信度(high confidence)被猜测出来,所以其计算复杂度大致与破解 DES 本身相同,而且它还容易受到已知明文/密文对的中间相遇攻击(Meet-in-the middle- attack)。
而 3DES 也类似,使用三个不同的密钥,进行 3 次 DES 加密。是从 DES 到 AES 的良好过渡。3DES有一个问题:如果 Key1 = Key2 = Key3,则三次运算会退化成:
(2) 高级加密标准(Advanced Encryption Standard, AES)
AES是一种 128 位块加密的算法。其密钥长度可以是 128 位、192 位或者 256 位,同样加密轮数也是可变的,10 轮、12 轮或者 14 轮。
AES 不像 DES 那样在每个阶段只使用替换和排列,而是由替换、移位、列混合和 KeyAdd 作的多个循环组成:
同样的,并不需要知道具体工作原理,只需要记住每一个有效分组块的大小为128位,记住密钥能支持的位数,以及轮密钥长度和加密轮数是可变的就行。
AES 的安全性较高,能抵抗暴力破解,因为AES-128 有
8.1.6.2 公钥加密(Public-key Cryptography, PKC)
虽然对称加密强度足够并且计算速度也快,但是如何安全地交换(key exchange)私钥又成了一个问题,并且随着通信节点增加,密钥数量呈指数级增长,密钥的管理也越来越复杂。
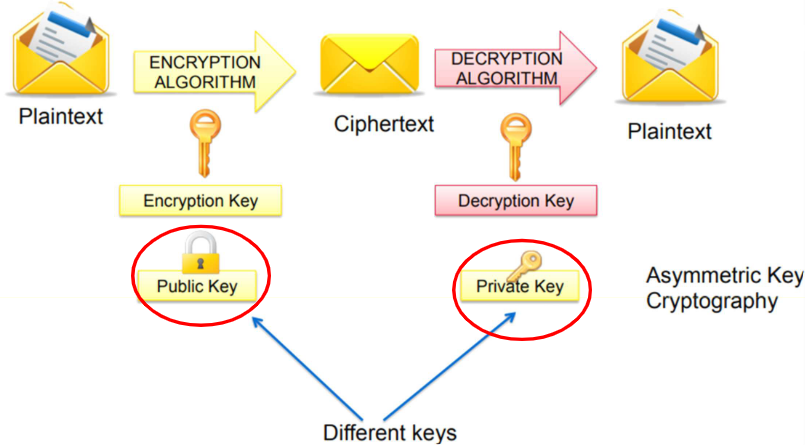
于是出现了非对称加密,也就是公钥加密。非对称加密使用两个不同但是相关的密钥,任何一个密钥都能加密或者解密信息,如果 A 能加密,那只有 B 才能解密。所以其中一个(B)作为私钥,由用户妥善保管(only to the recipient),绝不公开;而另一个(A)作为公钥,可对外公开(be known by anybody),用于加密或验证签名。
密钥在数学上相互关联,但从公钥推导出私钥是不可行的。
常见的公钥算法包括:
- Diffie-Hellman
- El-Gamal
- RSA
- Elliptic Curve Cryptography
而公钥密码学最重要的就在于它用一对 “公私钥” 解决了两个安全问题,一个是机密性(confidentiality),另一个则是身份认证:
- 公钥加密:用接收者的公钥加密的消息,只有拥有匹配私钥的人(possessor)才能解密。这用于确保机密性。即“公钥加密,私钥解密”。
- 数字签名(Digital Signatures):用发送者的私钥签名的消息,任何拥有发送者公钥的人都可以验证,因此,签名者很可能是与所用公钥相关联的人。 其逻辑就是“私钥签名,公钥验证”。
公钥密码学的一个核心问题是证明某个特定公钥是正确的且未被篡改(not been tampered with)。解决这个问题的常用方法是使用公钥基础设施(Public-key infrastructure, PKI),其中一个或多个证书颁发机构(Certificate Authorities, CA)对密钥对的所有权进行认证。
接下来是公钥加密中最重要的一部分,考试也是必考的内容:
(1) Diffie-Hellman 密钥交换算法
首先明确一个核心认知:
Diffie-Hellman 是一个仅用于「密钥交换」的公钥算法,它本身不加密、不解密消息本身。
它是如今最常用的加密协议之一,是 SSL/TLS(HTTPS 的基础)、VPN、SSH 等安全协议中电子密钥交换的核心方法。其目的就是为了让通信双方在不安全的网络中,协商出一个共享的对称密钥,之后再用这个密钥去加密实际的通信内容。
安全性是基于**离散对数问题(Discrete Log Problem)**的 ,给定公式如下:
已知
已知
我们可以用一个非常形象的颜料混合比喻来理解 Diffie-Hellman 的核心逻辑:
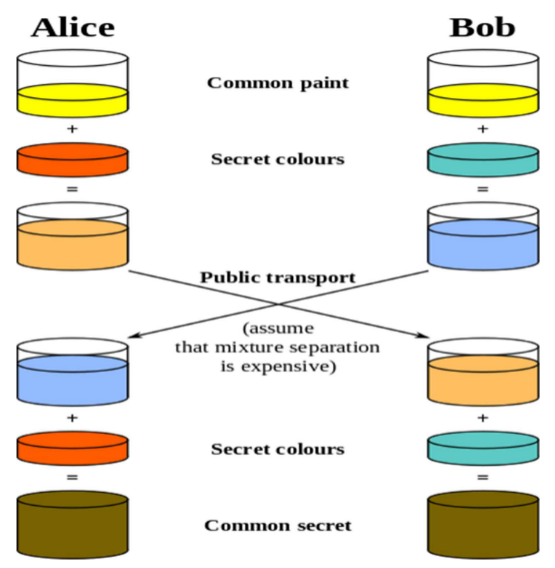
从上图可以看出,Alice 和 Bob 一开始共享一罐公开的黄色颜料(对应算法中的公开参数
-
Alice 把黄色颜料和自己的橙色颜料混合,得到一罐淡橙色混合液(公钥
-
Bob 把黄色颜料和自己的青色颜料混合,得到一罐淡蓝色混合液(公钥
最终结果如下:
- Alice 收到 Bob 的淡蓝色混合液后,加入自己的橙色颜料,得到深棕色(共享密钥
- Bob 收到 Alice 的橙色混合液后,加入自己的青色颜料,也得到了完全一样的深棕色(共享密钥
因此即使第三方截获了中间的混合液,也无法分离出原始的秘密颜色(就像无法从
这个比喻就对应了 Diffie-Hellman 的核心逻辑:(公开参数 + 各自私钥)
由此,我们可以把 Diffie-Hellman算法的流程拆解为 6 个步骤:
Step 1:确定全局公开元素(Global public Elements)
-
选择一个任意质数
-
计算
Step 2:用户 A 生成密钥对(Key Generation by User A)
-
随机选择一个小于
-
计算公钥
Step 3:用户 B 生成密钥对(Key Generation by User B)
-
随机选择一个小于 q 的数作为私钥
-
计算公钥
Step 4:交换公钥(Exchange the Public Key Between A & B)
- 用户 A 将自己的公钥
- 用户 B 将自己的公钥
Step 5:用户 A 计算共享密钥(Sharing Key Generation by User B)
- 用户 A 用收到的
Step 6:用户 B 计算共享密钥(Sharing Key Generation by User a)
- 用户 B 用收到的
关键结论:
因为:
双方最终得到的共享密钥完全一致!
接下来用几个例子来帮助理解:
Example 1:
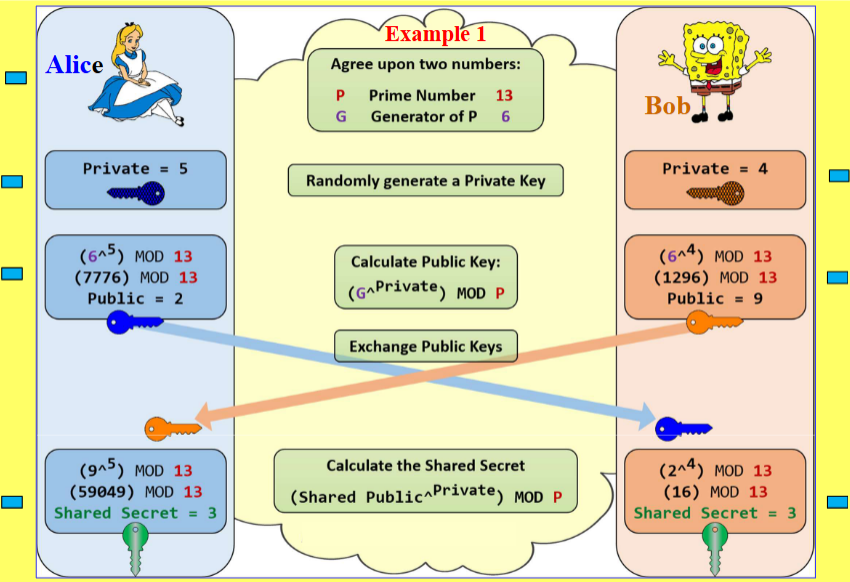
Answer:
可以看到公开参数有:素数
-
Alice 私钥
-
Bob 私钥
-
共享密钥计算:
-
Alice:
-
Bob:
-
-
所以双方共享密钥均为3
Example 2:

Answer:
可以看到公开参数有:素数
由于题目并没有指定
-
Alice 私钥
-
Bob 私钥
-
共享密钥计算:
-
Alice:
-
Bob:
-
-
所以双方共享密钥均为27
(2) RSA 算法
RSA 的安全性,源于大数因式分解的数学难题:
给定两个大素数 p 和 q,计算它们的乘积 N=p×q 非常容易;但已知 N,要反推出原本的 p 和 q,在计算上几乎是不可能的(尤其是当 p、q 为 2048 位甚至 4096 位的大素数时)。
这就是 RSA 能实现 “公开加密、私有解密” 的底层保障。
RSA 的核心是生成非对称密钥对,并完成加密/解密,整体分为三个核心阶段:
-
密钥对生成(核心步骤)
每一个用户都需要独立生成一对密钥:公钥(公开给所有人) 和 私钥(仅自己保留)。
-
选素数:随机选取两个大素数
-
算模数:计算乘积
-
算欧拉函数:计算
-
选公钥指数
- 条件 1:
- 条件 2:
- 常用值:
- 条件 1:
-
**算私钥指数
- 最终形式:
- 最终形式:
最终密钥对:
- 公钥:
- 私钥:
-
-
加密过程
发送方用接收方的公钥
- 设明文为
- 加密公式:
- 设明文为
-
解密过程
接收方用自己的私钥
- 解密公式:
- 解密公式:
我们用两个案例,一步步还原 RSA 的计算过程:
Example 1:
当
Answer:
-
算模数:
-
算欧拉函数:
-
选公钥
- 排除与 40 不互质的数(如 2、5)
- 选择 2:它会与 4 和 10 有共同的因数。
- 选择 3:它不会与 4 和 10 有共同的因数。
- 选择 5:它会与 10 有共同的因数。
- 选择 7:它不会与 4 和 10 有共同的因数。
- 排除与 40 不互质的数(如 2、5)
-
算私钥
-
方程:$3d=1 , (mod , 40) $
-
变形:
-
试
无余数
-
-
字符加密(消息 “DC”)

- 字符转数字:根据字符表,
- 加密(
- 字符转数字:根据字符表,
-
解密(
-
数字转字符:还原 “DC”。
Example 2:
当
Answer:
-
算模数:
-
算欧拉函数:
-
选公钥
-
算私钥
- 若
- 若
- 若
Practice:
Q1.
Choose p = 5, q = 11.
Compute public/private keys.
Encrypt message M = 9.
Decrypt to check.
Q2.
Choose p = 17, q = 19.
Let e = 5.
Compute n, φ(n), d.
Encrypt M = 25.
Decrypt to confirm.
Q3.
Choose p = 13, q = 23.
Let e = 7.
Encrypt M = 30.
Decrypt to verify.
8.1.6.3 ElGamal算法
和 Diffie-Hellman 一样,依赖离散对数难题。不仅支持加密,还包含数字签名算法,是一套完整的公钥密码体系。但是也有很明显的缺陷,首先就是密文体积是明文的2 倍(需要传输两个部分),存储和传输成本更高;其次就是运算速度较慢,不适合加密大量数据。
8.1.6.4 椭圆曲线加密(Elliptic Curve Cryptography, ECC)
ECC已经成为加密货币(如比特币)的核心加密方案。
传统公钥算法(RSA、Diffie-Hellman)依赖大素数运算,密钥越长越安全,但也越慢、越占存储。但是 ECC 基于椭圆曲线离散对数难题,因此在相同安全级别下,密钥长度远小于 RSA。
下面这张表就展示了 ECC 和 RSA 同等安全下的密钥长度差异
| 对称加密安全级别 | ECC 密钥长度 | RSA 密钥长度 |
|---|---|---|
| 56 位 | 112 位 | 512 位 |
| 80 位 | 160 位 | 1024 位 |
| 112 位 | 224 位 | 2048 位 |
| 128 位 | 256 位 | 3072 位 |
| 192 位 | 384 位 | 7680 位 |
| 256 位 | 512 位 | 15360 位 |
可以看到:要实现 128 位对称加密的安全强度,RSA 需要 3072 位密钥,而 ECC 仅需 256 位 ,存储和计算效率提升了 12 倍!
- 应用领域
- 加密货币:比特币(ECDSA签名)、以太坊
- 现代协议:TLS 1.3、Signal协议
- 移动设备:Apple iMessage、Android Keystore
8.1.7 混合加密系统(Hybrid System)
公钥算法虽好,但有个致命短板:慢。而对称加密(如 AES)速度极快,却又面临 “密钥如何安全分发” 的老问题。于是就有了混合加密系统,把两者的优点结合起来,既拥有对称加密的高速,又拥有非对称加密的密钥管理便捷性。
主要思路就两步:
- 密钥交换阶段:用公钥算法安全交换一个临时的对称会话密钥。
- 数据加密阶段:用这个会话密钥,通过对称加密算法加密实际的消息数据。
以客户端和服务器的交互为例,讲述混合加密的工作过程:
- 客户端发起会话请求:向服务器索要公钥。
- 服务器返回证书与公钥:服务器将包含公钥的数字证书发送给客户端(证书由权威机构签发,防止伪造)。
- 客户端生成会话密钥:随机生成一个对称会话密钥(比如 3486),用服务器的公钥加密后发送给服务器。
- 服务器解密会话密钥:用自己的私钥解密,得到会话密钥。
- 对称加密通信:双方用这个会话密钥,通过对称加密算法(如 AES)加密后续所有通信数据,实现高速安全传输。
实际上就是用非对称密钥对对称密钥进行加密然后实现了对称密钥的共享,随后的通信就使用对称密钥进行加密。
8.1.8 非对称与对称加密技术的比较
最后,再来总结一下两种加密方式的不同之处:
| 维度 | 对称加密 (Symmetric) | 非对称加密 (Asymmetric) |
|---|---|---|
| 密钥使用 | 加密 / 解密用同一把密钥 | 加密 / 解密用不同密钥(公钥 + 私钥) |
| 速度 | 极快,适合加密大量数据 | 较慢,不适合大数据加密 |
| 密钥分发(Key Distribution) | 困难(需要安全传递密钥) | 简单(公钥可以公开传输) |
| 典型用例 | 批量数据加密(Bulk data encryption)(如文件、消息) | 密钥交换、数字签名(如 HTTPS 握手) |
简单来说,对称加密是 “高速卡车”,适合运大量货物,但钥匙不好递;非对称加密是 “安全快递员”,负责把卡车钥匙安全送过去,然后让卡车运货。
8.2 数字签名(Digital Signature)
| 特性 | 手写签名 | 数字签名 |
|---|---|---|
| 物理存在 | 是文档的物理部分 | 无物理实体 |
| 验证方式 | 与真实签名样本比对 | 公开算法验证 |
| 防伪造性 | 容易被模仿伪造 | 极难伪 |
手写签名依赖视觉比对,很容易被伪造;而数字签名通过密码学技术,让伪造在计算上变得不可行,同时还能验证文档是否被篡改。
数字签名也被称为 “数字指纹”,是一种基于密码学的消息摘要,用来对消息进行身份认证,即内容来自已声明的来源且未被更改。它的核心逻辑基于非对称加密(公钥密码学):
- 发送者用自己的私钥对消息摘要进行签名,签名会成为消息的一部分。
- 接收者用发送者的公钥来验证签名的真实性。
它能实现两个核心安全目标:
- 消息完整性(Integrity):任何对消息的微小篡改都会被检测到(依赖哈希函数的雪崩效应)。
- 不可否认性(Non-repudiation):发送者无法否认自己签署过这条消息(signing the message),因为只有他持有对应的私钥。
它有两个极其重要的核心特性:
- 只有私钥持有者才能计算签名
- 任何持有匹配公钥的人都能验证签名
8.2.1 数字签名原理
数字签名方案的工作包含两个主要步骤:
-
准备消息代表(Prepare a message representative)
先通过哈希函数,把任意长度的原始消息压缩成一个固定长度的短二进制串 —— 也就是消息摘要(Message Digest)。这个摘要就是消息的 “数字指纹”,能唯一代表原始消息。 -
应用签名变换(Apply a signature transform)
用发送者的私钥,对这个消息摘要进行加密运算,最终生成数字签名。这一步相当于用你的私钥给 “数字指纹” 盖了章,让它和你绑定在一起。
而签名验证流程和签名流程刚好相反,是一个 “逆向校验” 的过程:
-
撤销签名变换(Undo the signature transformation)
用发送者的公钥,对收到的数字签名进行解密,还原出发送方生成的预期消息摘要。
-
检查消息摘要(Check the message digest for any issues)
接收方对收到的原始消息,用同样的哈希函数生成一个新的消息摘要,然后和第一步还原出的预期摘要进行对比。
-
如果两者完全一致:说明消息未被篡改,且签名确实来自私钥持有者。
-
如果不一致:要么消息在传输中被篡改,要么签名是伪造的。
-
数字签名的工作原理就是:我们使用哈希函数从消息中提取一个值(二进制字符串)。然后使用数字签名算法根据哈希值和私钥生成签名,接着就可以使用公钥和签名对消息进行认证了。
8.2.2 数字签名流程
数字签名方案有两个组成部分:
-
一种私人签名算法,允许用户对消息进行安全签名
-
一种公开验证算法,允许任何人验证签名是否真实。
8.2.2.1 哈希运算
由于数字签名是基于哈希函数,因此我们先了解一下哈希运算的规则。
哈希算法适用于任意长度的位串。其设计方式是,消息中的每一位都会对生成的消息摘要产生一定影响。然后,消息摘要可以输入到数字签名算法(DSA)中,该算法会为消息生成或验证签名。
哈希运算有几个关键特性:
-
首先是输入输出特性
- 可处理任意大小的数据块
- 输出固定长度(fixed-length)(与输入长度无关)
-
然后是核心的安全特性:
| 属性 | 定义 | 示例攻击难度 |
|---|---|---|
| 单向性(One-way or pre-image resistant) | 无法从哈希值
|
暴力破解需
|
| 抗第二原像攻击 | 给定
|
SHA-1已不满足 |
| 抗碰撞性(collision resistant) | 难以找到
|
MD5已破(可人工制造碰撞) |
哈希函数是一种特殊的数学函数,可执行单向加密:
-
一旦算法处理完成,就没有可行的方法利用密文来恢复明文。
-
不存在可行的方法生成两个不同的明文,使其计算出相同的哈希值。
两种常用的哈希算法是安全哈希算法(SHA)系列和消息摘要(MD),对比如下:
| 算法 | 输出长度 | 安全性状态 | 典型应用 |
|---|---|---|---|
| MD5 | 128位 | 已破解(碰撞攻击) | 仅用于校验文件完整性(非安全场景) |
| SHA-1 | 160位 | 已破解(谷歌2017年碰撞演示) | 历史系统(已淘汰) |
| SHA-2 | 224/256/384/512位 | 安全(NIST推荐) | TLS 1.2/1.3、比特币(SHA-256) |
| SHA-3 | 224-512位 | 抗量子计算候选 | 新兴系统(如区块链2.0) |
哈希函数有雪崩效应"Over":哪怕输入只改变一个字符,输出的摘要都会完全不同。
8.2.2.2 两种数字签名模式
(1) 无消息保护模式(Without Message Protection)(仅认证)
验证消息的来源与完整性,不对消息本身加密。
流程如下:
- 发送方(Bob):对消息哈希生成摘要
- 接收方(Alice):用 Bob 公钥解密签名得到预期摘要
由于消息是明文传输,适合无需保密但需认证的场景。
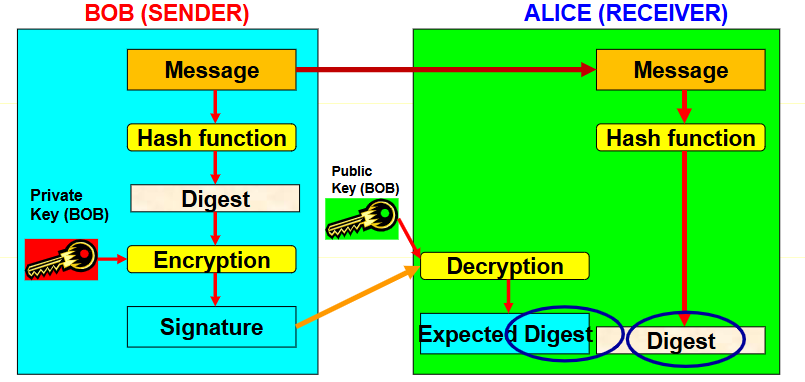
**(2) ** 有消息保护模式(With Message Protection)(认证 + 加密)
在认证的基础上,对消息本身加密保护。
流程如下:
- 发送方(Bob):对消息哈希生成摘要
- 接收方(Alice):用私钥解密得到 (消息 + 签名)
由于消息全程加密,兼顾保密性、完整性、不可否认性。
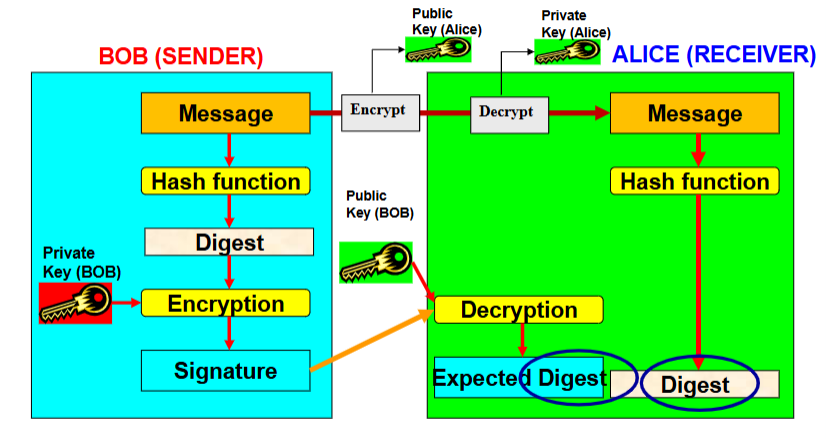
8.2.2.3 RSA 数字签名
- 密钥生成(Setup)
- 选择两个大质数
- 选择公钥指数
- 公钥:
- 签名与验证
-
签名(Signature):发送方用私钥对消息
-
验证(Verification):接收方用公钥计算
Example:
When
Solution:
-
- 消息
- 验证:
8.3 数字证书(Digital Certificates)
直接使用发送方公钥存在风险:攻击者可能伪造公钥冒充发送方。因此需要可信第三方,也就是证书颁发机构(Certification Authority, CA) 来绑定身份与公钥。
数字证书是一种由可信的 CA 签发的电子文档,类似于数字签名,附加在文件上,用于证明该文件来自其声称的组织,且未偏离原始格式(original format),以此解决公钥与身份的绑定问题。其包含:
- 持有者信息:名称、组织等。
- 公钥:证书主体的加密公钥。
- CA 的数字签名:用 CA 私钥对证书内容签名,确保证书未被篡改。
8.3.1 数字证书验证流程
-
测试数字签名(Testing the Digital Signature)
-
数字证书本身具有包含CA数字签名
-
必须用 CA 广为人知的公钥进行测试
-
如果测试通过,则证书是真实且未被修改的
-
-
检查有效期限(Checking the Valid Period)
-
证书仅在数字证书中的有效期限内有效
-
如果当前时间不在有效期限内,则拒绝该数字证书
-
-
检查吊销情况(Checking for Revocation)
- 证书可能因不当行为(improper behavior)或其他原因被吊销
- 必须对吊销情况进行测试
- 无法通过查看证书内的字段(looking at fields)来完成
- 接收方必须向 CA 查询
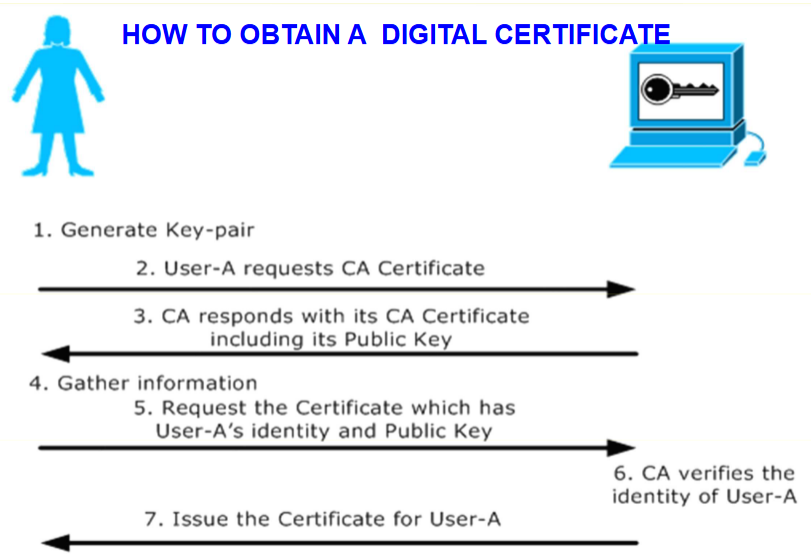
完整验证流程:1. 签名验证 → 2. 有效期检查 → 3. 吊销检查 (任何一步失败则拒绝证书)
8.4 密码算法总结
| 分类 | 代表算法 | 优势 | 劣势 |
|---|---|---|---|
| 对称加密(Symmetric) | AES, DES, 3DES, RC4 | 运算速度快、效率高 | 存在密钥分发(Key distribution)难题(安全传递密钥) |
| 非对称加密(Asymmetric) | RSA, ECC, Diffie-Hellman | 支持安全密钥交换、数字签名 | 计算复杂度高、速度较慢 |
| 哈希函数(Hash Functions) | SHA-2, SHA-3, MD5, SHA-1 | 保障数据完整性(Data integrity)、可用于密码存储 | 部分算法(MD5, SHA-1)易受碰撞攻击(collisions) |
| 数字签名(Digital Signature) | RSA, DSA, ECDSA | 实现身份认证与不可否认性 | 依赖公钥基础设施(PKI)(Relies on PKI infrastructure) |
现代密码学也面临了一些挑战:
-
密钥管理(Key management):涵盖密钥生成、安全存储与分发全生命周期的管理难题。
-
量子计算威胁(Quantum computing threat):Shor 算法可破解 RSA、ECC 等主流非对称加密算法,对现有密码体系构成潜在风险。
-
性能权衡(Performance trade-offs):需在安全强度与运算效率之间找到最优解。
-
过时算法淘汰(Obsolete algorithms):DES、MD5、SHA-1 等已被证明存在安全漏洞,应逐步废弃。
但由此也衍生出更多的新型密码技术:
- 同态加密(Homomorphic Encryption):支持在加密数据上直接进行计算,无需解密。
- 轻量级密码学(Lightweight Cryptography):专为资源受限(limited resources)的 IoT 设备设计,平衡安全与性能。
9 Web Security
Web 被企业、政府和个人广泛使用,但是互联网和网络由于使用 HTTP(超文本传输)协议,这是一种运行在 TCP/IP 上的简单且无状态的客户端 / 服务器应用程序,这一协议不是一种安全协议,所以它十分脆弱,容易受到很多威胁,包括但不限于:
- 完整性:数据修改(Data modification)、插入
- 保密性:网络窃听(Eavesdropping)、从服务器机器窃取数据(Theft from server machine)
- 认证:冒充(Impersonation)、数据伪造(forgery)
- 拒绝服务:被黑客攻击的网络服务器
9.1 HTTP and HTTPS
9.1.1 HTTP
HTTP(超文本传输协议)是互联网的基础协议,它定义了浏览器和服务器之间如何通信。
-
应用层协议(application-layer protocol):专门用于客户端(浏览器)和 Web 服务器之间的通信;
-
请求 - 响应模型(request-response model):客户端发请求,服务器返回响应,一次交互就完成;
-
无状态协议(Stateless Protocol):每个请求都是独立的,服务器不会记录你的会话状态,除非用 Cookie 等技术额外管理。
-
常用请求方法
-
GET:从服务器获取数据(比如打开一个网页) -
POST:向服务器发送数据(比如提交表单、登录账号) -
PUT:更新服务器上的数据 -
DELETE:删除服务器上的数据 -
HEAD:只获取响应头(Retrieve headers),不获取响应体
-
-
但 HTTP 有一个很致命的问题就是完全明文传输,没有任何安全保障:
- 所有数据(账号密码、聊天记录、支付信息)都是裸奔的,任何人都可以在传输途中窃听;
- 无法验证服务器身份,你以为连的是银行官网,实际可能是钓鱼网站;
- 数据可以被中途篡改,比如你收到的网页内容可能被黑客替换。
9.1.2 HTTPS
HTTPS(HTTP Secure)本质上就是HTTP + SSL/TLS,在 HTTP 的基础上增加了加密层,解决了 HTTP 的所有安全问题。
- 数据加密(Confidentiality):传输的数据都是密文,第三方无法窃听读取;
- 数据完整性(Integrity):数据在传输中无法被篡改,一旦修改就会被检测出来;
- 身份认证(Authentication):通过数字证书验证服务器的真实身份,防止钓鱼网站伪装。
9.1.3 HTTPS 与 HTTP 的对比
| 特性 | HTTP | HTTPS |
|---|---|---|
| 端口号 | 80 | 443 |
| 安全性 | 明文传输,无加密 | TLS/SSL 加密传输 |
| 身份认证 | 无 | 服务器身份可验证 |
| 数据完整性 | 可被篡改(can be modified) | 无法被篡改(cannot be altered) |
| 性能 | 更快,无加密开销(overhead) | 略慢(Slightly slower),需 TLS 握手(handshake)和加密计算 |
9.2 SSL/TLS
每天用的几乎所有互联网服务 — 电商购物、聊天软件、视频网站、银行 APP,背后都在使用 SSL/TLS。
安全套接层(Secure Socket Layer, originated by Netscape, SSL) 和 传输层安全(Transport Layer Security, TLS) 是一套密码学协议,用于在网络上建立安全、加密的通信链路。TLS 是 SSL 的升级版本,现在 SSL 已经被淘汰,我们日常说的 “SSL 证书” 实际都是 TLS 证书。
-
SSL(Secure Socket Layer)
这里需要了解其主要的目标即可,不做过多讲解:
- 保密性:通过加密让第三方无法读取传输内容;
- 完整性:通过消息认证码检测数据是否被篡改;
- 身份认证:通过数字证书(digital certificate)验证服务器身份,防止中间人攻击(客户端认证不常用)。
-
TSL
没啥好说的,就是SSL升级版而已。
SSL/TLS 位于应用层(HTTP)和传输层(TCP)之间,分为两层协议:
- SSL 记录协议:负责数据的加密、压缩和完整性校验,为上层提供可靠的安全传输通道
- SSL 握手协议:在数据传输前,客户端和服务器协商加密套件、交换密钥、验证服务器身份,建立安全会话
- 辅助协议:修改加密套件协议、告警协议(处理错误)
9.2.1 SSL/TLS 的密钥体系(Key Size for SSL/TLS)
SSL/TLS 中使用两种不同类型的加密速率:会话密钥以及公钥和私钥。
(1) 公钥 / 私钥对(非对称加密)
用于服务器身份认证和会话密钥的安全交换
-
密钥长度要求:
- 512 位:已被破解,完全不安全
- 1024 位:已可被暴力破解,不推荐使用
- 2048 位:当前主流安全标准,所有主流服务商都推荐使用
- 4096 位:更安全,但加密解密开销更大
(2) 会话密钥(对称加密)
-
每次有人连接到网站时,在 SSL/TLS 握手过程中动态生成,只用于本次会话的数据加密
-
为什么会话密钥比公钥短?
-
这是因为如果会话密钥被破解,只有一个会话的数据会面临风险,而且这也能减轻服务器的负载。
-
对称加密速度更快,减少服务器性能开销。会话密钥的长度通常在 40 位到 256 位之间。任何低于 128 位的都被视为不安全。
-
如果浏览器支持 256 位加密,但Web 服务器只支持 128 位,那么 SSL 连接将采用 128 位加密。
-
9.2.2 SSL/TLS 的分层架构
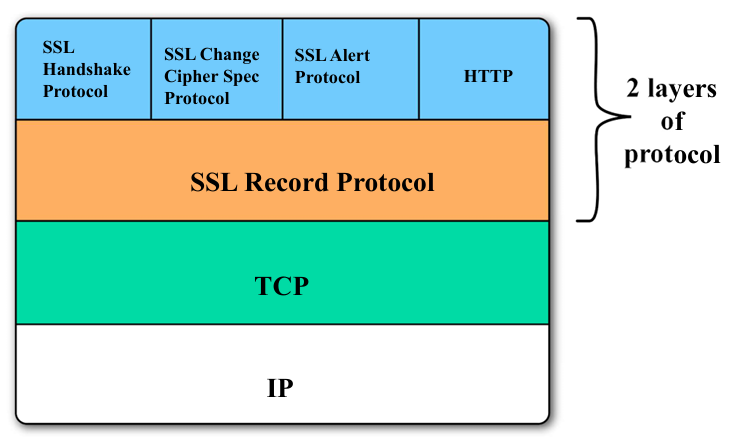
SSL(Secure Sockets Layer)是安全套接层协议,后续升级为 TLS(Transport Layer Security),二者本质是同一类协议的不同版本。SSL/TLS 并非单一协议,而是由两层协议和核心基础概念构成:
-
上层:握手协议(Handshake Protocol)以及应用层相关协议
这是 SSL/TLS 的 “谈判环节”,负责客户端和服务器的身份验证、加密算法协商、密钥生成等核心操作,是整个安全连接的基础。
-
下层:记录协议(Record Protocol)
这是 SSL/TLS 的 “数据处理车间”,负责对上层传输的应用数据进行分段、压缩、加密、添加校验码(MAC),最终封装成加密的网络数据包,确保数据端到端的安全传输。
此外,还有两个辅助协议:
- 更改密码规格协议(Change Cipher Spec Protocol):非常简单,作用是让客户端 / 服务器将 “待生效的加密配置” 切换为 “当前生效的加密配置”,相当于通知对方 “加密规则已确定,正式启用”。
- 警告协议(Alert Protocol):负责传递 SSL/TLS 连接中的异常信息,比如证书过期、握手失败、数据校验错误等,分为 “警告(非致命)” 和 “致命错误(终止连接)” 两类。
9.2.3 会话与链接(Session and Connection)
-
会话(Session)
是客户端和服务器之间建立的长期安全关联,由握手协议创建。它就像双方的 ""安全通行证”,定义了一套固定的加密参数(Defines secure cryptographic parameters)(比如用哪种加密算法、会话密钥是什么)。
一个会话可以对应多个连接—比如你打开同一个网站的多个标签页,这些标签页的连接都可以复用同一个会话,无需重复握手,大幅提升效率。
-
连接(Connection)
是客户端和服务器之间的端到端临时通信通道(End-to-End reliable secure communication),是会话的具体实现。每个连接都有明确的生命周期,负责一次完整的数据收发,且所有连接都必须关联一个会话。
9.2.4 SSL/TLS 记录协议完整流程
记录协议是 SSL/TLS 保障数据安全的核心执行环节,流程图清晰展示了它对应用数据的处理步骤,我们一步步拆解。
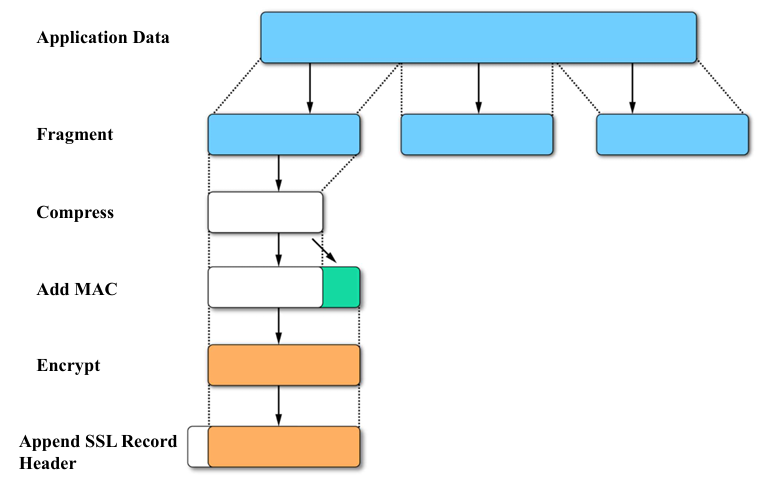
完整处理流程(从应用数据到加密数据包),了解即可:
-
应用数据(Application Data)
这是最原始的业务数据,比如你输入的账号、浏览的网页内容、支付金额等,由客户端的应用层(浏览器、APP)生成。
-
分段(Fragment)
把原始数据拆分成合适大小的片段(默认最大 16KB),避免单条数据过大导致传输失败,这是网络传输的常规预处理步骤。
-
压缩(Compress)
对分段后的数据进行无损压缩(可选步骤,早期 TLS 支持,现在 TLS 1.3 已移除),减少数据体积,提升传输速度。
-
添加 MAC(Add MAC)
给压缩后的数据添加消息认证码(MAC) — 这是基于会话密钥和数据生成的一段校验码,作用是验证数据完整性。如果数据传输中被篡改,接收方计算 MAC 时会发现不一致,从而判定数据异常。
-
加密(Encrypt)
用协商好的对称加密算法(比如 AES),结合会话密钥,对 “数据 + MAC” 的组合进行加密,这是保障数据机密性的关键步骤。
-
添加 SSL 记录头部(Append SSL Record Header)
给加密后的数据添加记录头部(包含协议版本、数据长度、类型等信息),最终形成完整的 SSL/TLS 记录数据包,通过网络传输给对方。
接收方则会反向执行这些步骤:解析头部、解密、验证 MAC、解压、重组,最终还原出原始应用数据。
其中有几个较为重要的协议需要重点了解:
-
Change Cipher Spec(CCS)协议的作用
- 核心功能:
- 通知对端切换至新协商的加密参数(如AES-256密钥、HMAC-SHA256哈希算法)。
- 将握手阶段生成的"pending state"转为"current state",此后数据加密生效。
- 核心功能:
-
Alert协议
- 核心功能:
- 传递 SSL/TLS 相关的警告或错误消息,信息会被压缩(compressed)或加密。
- 信息:两个字节,一个定义致命/警告,另一个定义警报代码。
- 意外消息(Unexpected message)、错误记录 MAC(bad record MAC)、解压缩失败(decompression failure)
- 握手失败(无共同点)、非法参数(illegal parameters)(不一致或无法识别的参数)
- 无证书、错误证书、不支持的证书、证书已吊销(certificate revoked)、证书过期(certificate expired)、证书未知。
- 核心功能:
9.2.5 SSL/TLS 握手协议(SSL/TLS Handshake Protocol)
如果说记录协议是 “数据处理车间”,那握手协议就是建立安全连接的核心谈判环节—— 它是 SSL/TLS 最复杂的部分,却也是最关键的部分,决定了后续通信的加密强度、密钥和身份合法性。
握手协议的四个核心任务:
- 客户端和服务器互相验证身份(Authenticate each other)(主要是服务器验证客户端,客户端验证服务器);
- 协商(Negotiate)确定加密算法、MAC 算法等加密套件;
- 协商生成后续通信要用的加密密钥;
- 最终建立一套安全的会话状态(establish a state),为后续连接复用做准备。
9.2.5.1 SSL/TLS 1.3 密钥交换
TLS 基于 “混合”(hybrid) 密码系统。在混合密码系统中,公钥加密用于在双方之间安全地交换密钥,然后该密钥用于对交换的数据进行加密/解密。使用公钥密码术有两种主要方式。
(1) RSA 密钥交换
TLS 1.2 及之前版本,RSA 是最常用的密钥交换方式,核心逻辑很简单:
-
客户端生成共享密钥,用服务器的公钥加密后发送;
-
服务器用自己的私钥解密,得到预主密钥;
-
双方结合随机数计算出会话密钥。
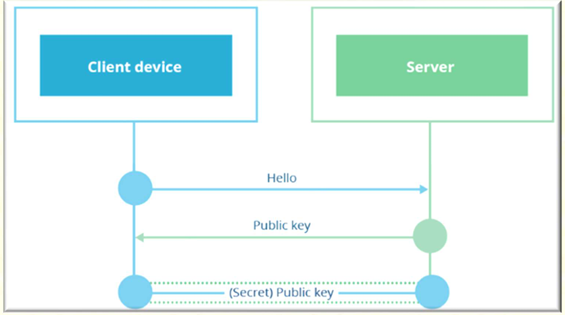
- 优点:实现简单,兼容性强,是早期网站的首选。
- 致命缺点:不支持前向保密(Forward Secrecy),也就是说如果黑客提前记录了加密通信数据,一旦未来拿到服务器的私钥,就能解密所有历史通信内容,存在巨大安全隐患。
(2) Diffie-Hellman(DH)密钥协议
DH 密钥协议是一种 “双方共同生成密钥” 的方式,核心逻辑是 “基于离散对数难题”,无需直接传输密钥,更安全:
-
客户端和服务器各自生成公钥和一个私钥对;
-
双方互相发送自己的公钥片段(Key Share);
-
客户端用自己的私钥和服务器的公钥,服务器用自己的私钥以及客户端的公钥,分别计算出相同值的预主密钥(pre-master secret);
-
然后服务器使用数字签名来确保交换未被篡改。
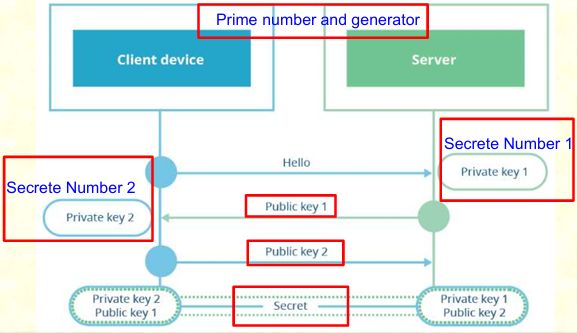
关键变种:Ephemeral DH(EDH/DHE)
另外,“临时 DH(Ephemeral DH)”,指客户端和服务器每次握手都生成全新的公钥 / 私钥对,而非复用固定密钥。这一特性完美解决了 RSA 的前向保密问题 —— 即使服务器私钥泄露,黑客也无法解密历史通信,因为每次的密钥都是临时生成的。
9.2.5.2 TLS 1.3 握手阶段
TLS 1.2 需要多轮消息交互(往返多次),而 TLS 1.3 大幅精简:
-
客户端 Hello 消息开始握手,但是,TLS 1.3 已将支持的密码数量从 37 个减少到 5 个,这意味着客户端可以猜测将使用什么密钥协议/交换协议,然后从它猜测的任何协议发送其密钥共享。
-
服务器将使用自己的 Server Hello 消息进行响应,并将发送证书和自己的密钥共享部分,计算会话密钥,并以 Server finished 消息结束。
-
客户端将对 SSL 证书进行身份验证,并使用两个密钥共享来计算自己的会话密钥副本。完成后,它会发送自己的 Finished 消息。 密钥是使用临时 Diffie-Hellman(EDH 或 DHE) 生成/共享的,TLS 1.3 中允许的三种主要签名算法是:RSA(仅签名)、椭圆曲线数字签名算法(ECDSA) 和爱德华兹曲线数字签名算法(EdDSA)。
TLS 1.2 和 TLS 1.3对比图:
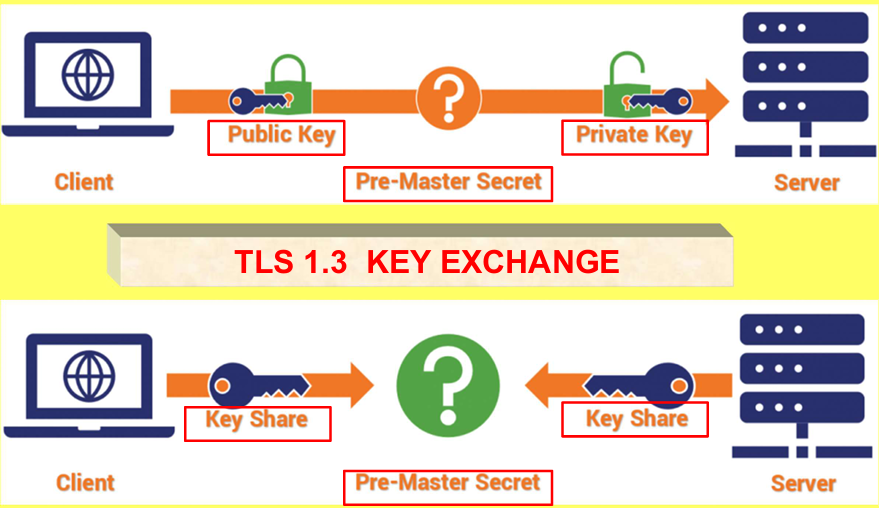
- TLS 1.2(RSA):客户端仅用服务器公钥加密预主密钥,单向传输密钥,依赖服务器私钥解密。
- TLS 1.3(DH):客户端和服务器互相发送 Key Share,双向协商生成密钥,无需依赖服务器私钥长期保护密钥,安全性拉满。
TLS 1.2 和 TLS 1.3握手次数对比图:
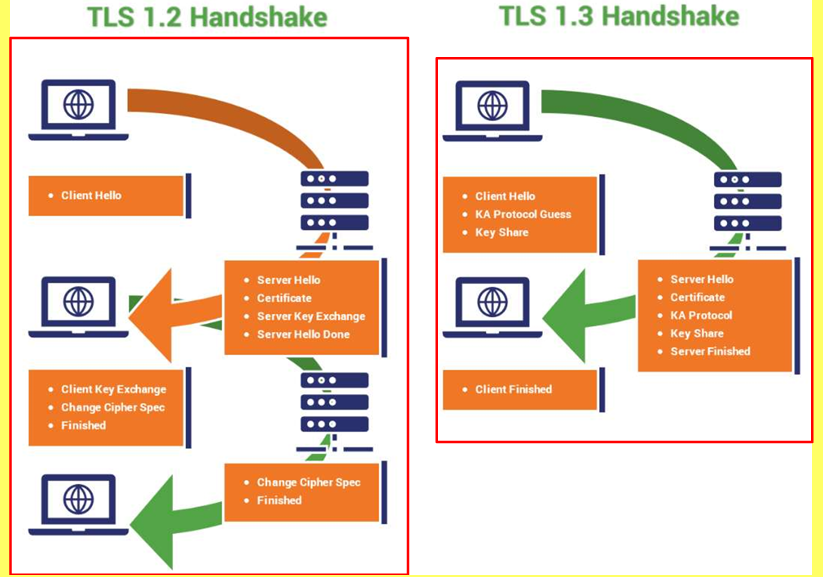
TLS 1.3 中的改进:
- 删除了过时的加密算法(RSA 密钥交换、SHA-1);
- 更快的握手(将往返次数从 2 次减少到 1 次);
- 完全正向保密(Perfect Forward Secrecy, PFS):确保即使密钥泄露,过去的通信也保持安全;
- 更强的加密(ChaCha20、AES)。
9.2.5.3 常见的SSL/TLS 攻击和缓解措施
| 攻击类型 | 描述 | 缓解措施 |
|---|---|---|
| 中间人攻击(Man-in-theMiddle) | 攻击者拦截通信 | 使用HTTPS,验证证书 |
| 降级攻击(Downgrade Attack) | 强制使用旧的不安全TLS/SSL版本 | 禁用TLS 1.0/1.1,强制使用TLS 1.2或1.3 |
| 野兽攻击(BEAST Attack) | 利用TLS 1.0的弱点 | 升级到TLS 1.2或1.3 |
| 贵宾犬攻击(POODLE Attack) | SSL 3.0漏洞 | 禁用SSL 3.0,使用TLS 1.2或1.3 |
| 心脏出血(Heartbleed) | OpenSSL漏洞导致内存泄漏 | 更新OpenSSL补丁 |
| DROWN 攻击(DROWN Attack) | 利用配置错误的服务器上的SSLv2 | 禁用SSLv2和弱密码 |
9.2.5.4 SSL/TLS的问题
| 类别 | 说明 |
|---|---|
| 性能影响 | 会降低服务器性能(slows down servers)(加密/解密增加计算开销) |
| 保护范围 | 仅保护传输中的数据(protects data in transit),不保护数据库存储的数据(not databases) |
| 认证限制 | 无法认证:计算机操作者身份(actual operator of a computer),网店所有者身份(owner of an online shop),消费者身份(actual online consumer),支付系统其他参与方身份( other parties involved in online payment system) |
| 支付安全 | 无法防止盗用信用卡在线交易(the use of stolen credit cards online) |
| 证书成本 | 证书价格(Cost of the certificate)差异大(DV证书免费,EV证书价格较高) |
| 协议特性 | 是双方协议(atwo-party protocol)(不同于三方的SET协议) |
9.3 安全电子交易(Secure Electronic Transaction, SET)
SET协议诞生于1996年,由万事达(Master Card)、Visa两大卡组织牵头,联合微软、IBM、网景(Netscape)等科技巨头共同开发,核心目标是解决开放互联网上银行卡支付的安全问题,防止交易中的信息泄露、伪造和抵赖。
很多人会误以为SET是一种支付系统,但它的本质是一套安全协议与数据格式标准——它不直接处理资金划转,而是定义了支付全流程中各方的通信规则、加密方式和信任机制,让银行、商户、用户之间的交互都能安全进行。不过遗憾的是,这套协议最终并未大规模部署,成为了支付安全史上一个“理念超前却落地失败”的典型案例。
-
SET 建模了支付中的所有参与方(持卡人(Purchaser)、商户(Merchants)、银行(Banks),定义了各方的信任关系(trust relationships),甚至明确了数字签名的法律效力(legal meaning of digital signatures);
-
SET还对交易中涉及的每个实体都提供加密身份认证(cryptographic identity authentication)(多方安全(multiparty security));
-
SET采用**消息加密而非通道加密(messagenot channel encryption)**的思路,区别于SSL加密整个传输通道,SET会对支付消息本身进行加密,不同角色只能解密自己权限内的信息,最大程度保护用户隐私;
-
每个持卡人都会被颁发数字签名,搭配支持SET协议的软件,就能组成一个SET电子钱包(SET electronic wallet),作为用户侧的安全支付工具;
-
它的消息格式与传统银行网络(traditional banking networks)沿用多年的格式兼容,银行无需对内部系统做大规模改造,就能接入互联网支付场景。
9.3.1 SET与SSL的区别
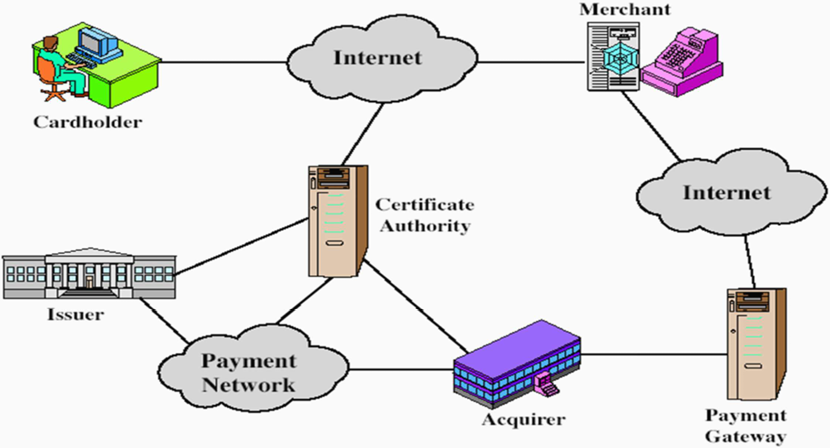
SET 向商家保证,持卡人不会声称 “不是我操作的”;银行有证据证明是我进行了购买。SET 向持卡人保证商家是合法的,因此具有双向安全性。
-
优点:
- 商家无法获取客户的账户信息(not have access to client’s account)(财务数据的保密性)。
- SET 提供完整的卡片支付系统(支付传输、确认和查询)。
- 保密性:对称密钥(Symmetric Key)加密
- 授权:公钥加密 RSA
- 完整性:哈希算法
-
缺点:SET 要求在银行网络、商家所在地以及消费者的计算机上安装相应的软件。
而SET 协议的参与方可以分为四大主体,每个角色承担着不同的职责,共同构成了完整的支付链路:
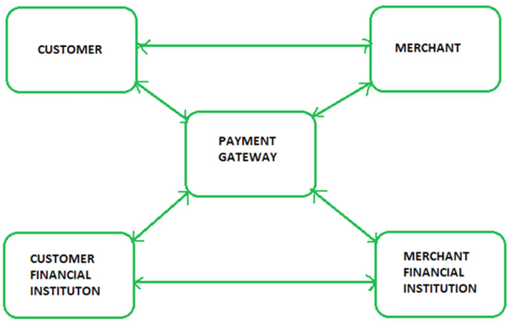
可以从上图看到 SET 的两个区别于 SSL 的关键:
-
身份认证(Authentication):用数字证书给各方 “验明正身”
SET 通过数字证书对所有参与方进行身份验证,避免 “冒充消费者”“假商家诈骗”“伪造支付网关” 等风险。
- 消费者:持有由发卡行颁发的数字证书,证明自己是合法持卡人
- 商家:持有由收单行颁发的数字证书,证明是正规经营主体
- 支付网关/银行:持有权威机构颁发的证书,确保交易中转方的合法性
-
消息机密性与完整性(Message Confidentiality & Integrity):用技术手段防篡改、防窃听
SET 结合多种加密技术,实现了交易数据的三重安全防护:
- 加密(Encryption):通过对称密钥加密核心交易数据,防止传输过程中被第三方偷看,保障机密性;
- 数字签名(Digital Signatures):利用非对称加密(如 RSA)对交易信息签名,既证明数据未被篡改,又能实现 “不可抵赖”(消费者无法否认自己发起了支付);
- 哈希(Hashing):通过哈希算法生成数据摘要,快速验证交易内容是否被恶意修改,确保数据完整性。
为了更直观的了解两者的差异,下面给出一张对照表:
| 对比维度 | SSL/TLS协议 | SET 协议 |
|---|---|---|
| 核心目标(Main Aim) | 实现数据的加密传输,本质是一个 “传输通道加密工具” | 专门为电子商务(Ecommerce)设计的完整支付机制,从一开始就瞄准了支付全流程的安全 |
| 认证能力(Certification) | 仅支持服务器端认证 | 支持双向认证(商户+持卡人) |
| 客户端身份识别 | ❌ 无法验证客户真实身份 | ✅ 可验证持卡人身份 |
| 商家欺诈风险(Risk of Merchant Fraud) | 存在风险,因为用户需要把自己的财务信息直接发给商家 | 几乎不可能,因为用户的财务信息只会发送给支付网关,商家全程接触不到用户的账户数据 |
| 用户欺诈风险(Risk of Customer fraud) | 存在风险,没有机制防止用户事后否认交易(比如 “我没付过钱”) | 风险极低,用户必须对支付指令进行数字签名,无法抵赖 |
| 用户欺诈的责任方(Action in case of customer fraud) | 由商家承担责任,比如用户拒付,商家只能自己兜底 | 由支付网关承担责任,因为网关持有用户的数字签名凭证,可作为仲裁依据 |
| 不可否认性 | ❌ 无法提供 | ✅ 通过数字证书实现交易不可抵赖 |
| 数据完整性 | 保护传输过程数据 | 额外确保订单内容不可篡改 |
| 适用场景 | 通用网络通信加密 | 专为电子支付设计 |
| 当前应用现状 | 全网普及(HTTPS标准) | 技术未消亡但实际使用率为零 |
| 电商适用性 | 存在缺陷(但无替代方案) | 理论更安全但未推广 |
10 网络安全控制(Network Security Control)
网络安全控制指的是为增强网络安全性(enhance the security of a network)而采取的各种措施,例如访问控制(Access Control)、身份验证(Authentication)、授权(Authorization)、加密(Cryptography)、网络安全(Web Security)、安全策略(Security Policy)等。常见的网络安全防护措施有三种:防火墙(Firewall)、入侵检测系统(IDS)、蜜罐(Honeypots)。
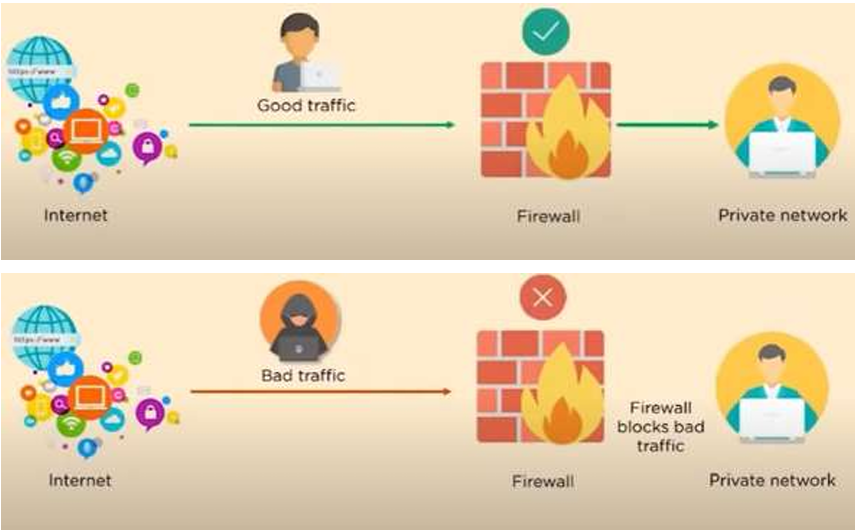
10.1 防火墙(Firewall)
-
防火墙是一套网络安全设备/软件
它根据基于企业 / 个人预先设置好(previously established)的安全策略(security policies),持续监控(monitors)并过滤(filters)进出网络的流量(incoming and outgoing network traffic)。简单类比,它就像小区门口的保安,手里拿着一份 “放行规则”,每一辆进出的车都要逐一检查,符合规则的放行,不符合的直接拦下。
-
防火墙是内网与公网之间的核心屏障
可以类比成一堵"砖墙"(barrier)把左侧的私有内网(服务器、办公电脑)和右侧的公网设备彻底隔开。我们的个人电脑、公司的服务器都属于"私有内网"(private internal network),而开放的互联网是充满风险的公网,防火墙就是横在两者之间的唯一大门,所有进出的流量都必须经过这扇门,没有例外。
它的终极目的非常明确:让正常的、无威胁的流量顺利进出(allow non-threatening traffic in),同时把恶意的、危险的流量彻底挡在门外(keep dangerous traffic out),避免内网设备和数据被攻击、窃取。
10.1.1 防火墙的形式
防火墙可以是硬件、软件,也可以是两者的结合,其核心工作就是监控所有试图穿过网络边界(perimeter)或网络传输的数字信息数据包(packets of digital information)。
| 类型 | 保护范围 | 部署位置 | 成本与配置 | 适用场景 |
|---|---|---|---|---|
| 硬件防火墙 | 整个网络 | 路由器层面(router leve) | 价格更高,配置更复杂( harder to configure) | 企业、学校、园区等大型网络 |
| 软件防火墙 | 单台计算机 | 终端设备系统内 | 价格更低(甚至免费),配置简单 | 个人电脑、单台服务器 |
软件防火墙的工作机理:
- 当每个单独的数据包到达防火墙的任意一侧(传入你的计算机或从你的计算机传出)时,对其进行检查。不管是进入你电脑的入站(Inbound)流量,还是从你电脑发出去的出站(Outbound)流量,都会被逐一检查。
- 然后根据预设的安全规则,判断这个数据包应该被放行,还是应该被拦截。
防火墙怎么挡住蠕虫和黑客(Keeping Worms and Crackers out )?— 简单来说让你的设备 “隐身” 在公网,就是当你在浏览器里输入一个网址,请求网页内容时,并不是你的电脑直接向互联网的服务器发起请求,而是防火墙先接收到你的请求,然后伪装成是它自己发起的请求,去互联网上获取内容。
PPT 里那句 “Your firewall is just a dumb box”,并不是说它没用,而是说它的功能非常单一、纯粹,只做流量转发和过滤,没有多余的服务和可被利用的漏洞,黑客就算想攻击它,也很难找到突破口。就算攻破了防火墙,也很难穿透进入你的内网。
10.1.2 防火墙的完整运行流程
接下来的 4 张 图完整还原了企业级边界防火墙的工作全流程,
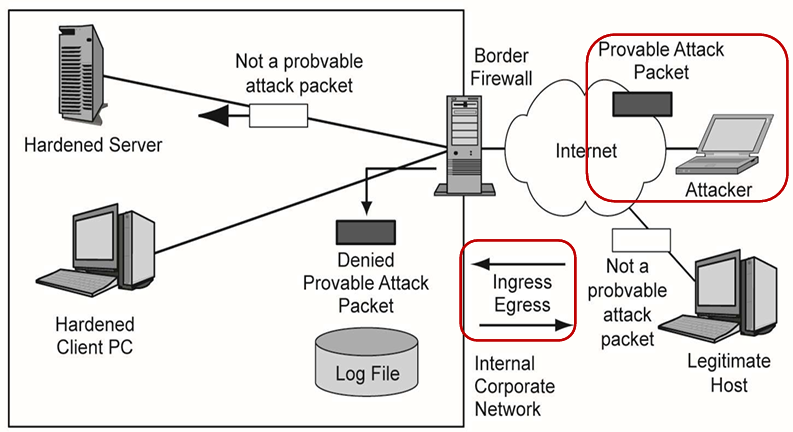
首先,我们先看懂这张通用的企业网络拓扑图:
- 左侧是企业内部网络(Internal Corporate Network),里面有经过安全加固的服务器(Hardened Server)和客户端电脑(Hardened Client PC),还有记录防火墙所有动作的日志文件(Log File)。
- 中间是边界防火墙(Border Firewall),是内网和互联网之间的唯一关口,所有进出的流量都必须经过它,没有例外。
- 右侧是开放的互联网,里面有两类主体:发起攻击的黑客(Attacker),和正常访问的合法主机(Legitimate Host)。
Step1 区分流量的来源与方向
-
防火墙要先搞清楚两个最基础的问题:这个流量是谁发的?要往哪里去?
-
流量的性质:合法流量以及攻击流量
合法的主机发送的是无害数据包(innocent packets),也就是正常的业务流量;而攻击者发送的是攻击数据包(attack packets),也就是带有恶意特征的攻击流量。
-
流量的方向:入站和出站
- Ingress(入站流量):从互联网进入企业内网的流量,比如用户访问公司官网的请求、黑客的扫描攻击,都属于入站流量。
- Egress(出站流量):从企业内网发往互联网的流量,比如员工访问外网、服务器同步数据的请求,都属于出站流量。
-
-
所有的流量,都会先被防火墙标记清楚 “来源、去向、性质”,再进行下一步的处理。
Step 2 拦截并记录可确认的攻击流量
-
对于可确认的攻击数据包(Provable Attack Packet),防火墙会直接执行两个操作:
- Drop(丢弃):直接把这个攻击包扔掉,不让它进入内网,黑客的攻击就被彻底阻断了。
- Log(记录):把这个攻击包的来源 IP、攻击时间、攻击类型等信息,全部记录到日志文件里。方便后续的安全运维人员排查问题、追溯攻击来源,甚至优化防火墙的安全规则。
-
比如,防火墙识别到一个数据包是常见的 SQL 注入攻击,或者是来自黑名单 IP 的恶意扫描请求,就会直接把它拦下来,同时记下来 “这个 IP 在 XX 时间发起了攻击”,为后续的安全运维留下依据。
Step 3 放行正常流量,同时认清防火墙的局限性
-
很多人以为防火墙能挡住所有攻击,其实不是。防火墙也有局限性:
-
防火墙的核心原则:不误杀优先
防火墙不会随意丢弃数据包,除非它能 100% 确认这个包是攻击包。也就是说,只要防火墙没法证明这个包是恶意的,就会默认放行,避免把正常的业务流量拦下来,影响企业的正常办公和业务运行。
而正是因为这个 “不误杀” 的原则,有些攻击数据包如果伪装得足够好,防火墙没法确认它是攻击包,就会穿过防火墙,进入内网。
-
10.1.3 防火墙策略(Firewall Policies)
为了保护私有内网和单机设备免受公网威胁,防火墙会基于一套预先定义好的规则集合( predefined set of rules)(也就是防火墙策略),对入站(从公网进内网)和出站(从内网出公网)的流量进行过滤(filter incoming or outgoing traffic)。
防火墙的规则是从上到下顺序匹配,数据包匹配到第一条符合条件的规则后,就会立即执行对应的动作,不再继续往下匹配;如果前面的规则都不匹配,就会执行最后一条兜底的默认拒绝规则。
如果把IP 地址比作房子,端口号比作房子里的房间。
只有受信任的人(源地址),才被允许进入房子(目的地址);就算进了房子,也只能进入指定的房间(目的端口)。
房主(管理员)能进所有房间(所有端口),孩子和客人(普通用户 / 访客)只能进指定的房间(特定端口)。
Example:
给出基础规则表:
| 规则编号 | 源 IP | 目的 IP | 端口 | 动作 |
|---|---|---|---|---|
| 1 | 192.168.1.0/24(内网网段) | Any(任何) | 80(HTTP 服务) | Allow(放行) |
| 2 | Any(任何) | 10.0.0.5 | 22(SSH 服务) | Deny(拦截) |
| 3 | Any(任何) | Any(任何) | Any(任何) | Deny(拦截) |
Solution:
首先我们对这几个规则进行解读:
-
规则 1:只要是从
192.168.1.0/24(内网网段,也就是 192.168.1.1~192.168.1.254 的所有内网设备)发出来的请求,不管目标地址是哪里,只要是访问 80 端口(网页),就直接放行。 -
规则 2:不管请求从哪里来,只要目标地址是
10.0.0.5、访问的是 22 端口(远程管理),就直接拦截。 -
规则 3:兜底规则。所有请求,只要前面 2 条规则都没匹配上,不管来源、目标、端口是什么,全部拦截。
接下里,我们来看 3 个测试案例:
-
Example 1
数据包源 IP=192.168.1.25,目的 IP=8.8.8.8,端口 = 80
完全匹配规则 1 的所有条件,执行 Allow,直接放行。
-
Example 2
数据包源 IP=172.16.5.10,目的 IP=10.0.0.5,端口 = 22
完全匹配规则 2 的所有条件,执行 Deny,直接拦截。
-
Example 3
数据包源 IP=192.168.1.30,目的 IP=10.0.0.5,端口 = 443
规则 1 不匹配(端口不是 80),规则 2 不匹配(端口不是 22),最终匹配兜底的规则 3,执行 Deny,拦截。
c注意:规则的顺序极其重要!如果把默认拒绝规则放在最前面,所有流量都会被拦截,网络直接中断。
10.1.4 个人防火墙
个人防火墙是一款软件应用,专门用来保护单台接入互联网的电脑(single Internet-connected computer),免受入侵者攻击,比如 Windows 自带的 Microsoft Defender 防火墙、MacOS 内置防火墙,都属于这类。
个人防火墙主要有以下几个功能:
- 可以阻止黑客访问你的计算机(Stop hackers from accessing your computer);
- 保护你的个人信息(Protects your personal information);
- 拦截"弹出式" 广告和某些 Cookie(Blocks “pop up” ads and certain cookies);
- 确定哪些程序可以访问互联网(Determines which programs can access the Internet)。
但同时,个人防火墙也有其局限性:
- 不能防止电子邮件病毒**(Cannot prevent e-mail viruses)**
- 邮件病毒藏在附件 / 邮件内容里,防火墙无法识别邮件内的恶意程序,只有带有更新定义的杀毒软件**(antivirus product with updated definitions)**才能防止电子邮件病毒
- 不是设置一次就一劳永逸**(After setting it initially, you can forget about it)**
- 防火墙需要定期更新**(require periodic updates)**规则集和软件本身,才能应对新的攻击方式,长期不更新就会逐渐失效。
10.1.5 防火墙的优劣势
-
核心优势
-
增强边界安全(Enhanced Security):拦截未授权访问(Blocks unauthorized access)和绝大多数常规网络攻击,是内网和公网之间的第一道防线;
-
精细化流量管控(Traffic Filtering):可以灵活控制哪些数据包能进出网络**(Controls which data packets are allowed)**,比如禁止员工上班访问娱乐网站、拦截恶意 IP 的连接;
-
日志与告警能力(Logging and Alerts):会完整记录所有可疑活动**(suspicious activity)**,比如攻击来源、扫描行为,还能在发现异常时发出告警,方便事后追溯和应急响应。
-
-
核心劣势
- 性能影响(Performance Impact):防火墙需要逐包检查流量,配置大量复杂规则时,会消耗网络资源,拖慢网速**(slow down network speed)**;
- 配置门槛高(Complex Configuration):企业级防火墙需要专业知识**(Requires expertise)**配置维护,规则写错要么网络中断,要么留下安全漏洞;
- 无法防御内网威胁(NoProtection Against Insider Threats):防火墙只管控内网和外网的边界,来自内网内部的攻击(比如员工电脑中毒在内网传播、内部人员恶意操作),它完全无法拦截**(cannot stop attacks from internal users)**;
- 有被绕过的风险(Bypass Risk):攻击者可以通过 VPN 隧道**(tunneling)、加密恶意流量等方式,把攻击伪装成正常流量,绕过防火墙检测(evade detection)**;
- 对高级攻击防御有限(Limited Defense Against Advanced Attacks):无法防护社会工程学攻击(比如骗你手动运行木马),也防不了零日漏洞攻击(利用未公开、无补丁的新漏洞,防火墙没有对应的拦截规则)(Cannot protect against social engineering or zero-day exploits)。
10.1.6 防火墙的类型
10.1.6.1 传统基础型防火墙
-
数据包过滤防火墙(Packet Filtering Firewall)
- 原理:只检查数据包的头部**(Examines individual packets header)**,基于源 IP、目的 IP、端口过滤,不看数据包内容;
- 特点:速度快、资源消耗小,但无状态**(Stateless)(不记录之前的数据包上下文(no context of previous packets)),没有深度检测能力(lacks deep inspection capabilities)**,安全性弱;
- 现状:现在仅作为防火墙的基础功能,很少单独使用。
-
状态检测防火墙(Stateful Inspection Firewall)
- 原理:会监控活跃的网络连接,跟踪会话状态**(tracks the state of network traffic)**,比如你主动向外发起的请求,对应的返回包会被自动放行,无需单独写规则;
- 特点:比包过滤防火墙安全得多,能识别伪造的攻击包,是传统防火墙的主流类型;缺点是需要更多系统资源**(requires more resources)**记录会话状态。
-
代理防火墙(Proxy Firewall)
- 原理:充当用户和互联网的中介**(intermediary between users and the internet)**,用户的所有请求都先发给防火墙,防火墙再替用户访问互联网,返回内容给用户,内网和外网没有直接连接;
- 特点:安全性极强**(strong security),外网完全接触不到内网设备;但会严重拖慢网络性能(can slow down network performance)**,延迟很高;
- 适用场景:对安全性要求极高的涉密内网,现在很少大规模使用。
10.1.6.2 现代新型防火墙
-
下一代防火墙(Next-Generation Firewall, NGFW)
- 原理:在传统防火墙的基础上,新增了入侵防御**(intrusion prevention, IPS)**、深度包检测(DPI,能检查数据包内容)、应用层识别(能识别微信、抖音等应用,而不只是看端口);
- 特点:功能全面,能防御应用层攻击;缺点是价格更高,对资源要求更高。
-
云防火墙(Cloud-Based Firewall)
- 原理:部署在云基础设施上**(Hosted on cloud infrastructure),以 SaaS 服务的形式为远程用户提供可扩展防护(scalable protection)**,无需本地硬件;
- 特点:扩展性极强,能给远程办公员工、多分支机构、云上业务提供统一的防护,减少本地硬件依赖**(Reduces on-premises hardware dependency),但是极度依赖第三方云服务商(relies on third party services)**;
- 适用场景:云上业务、多分支企业、远程办公场景。
-
Web 应用防火墙(WAF,Web Application Firewall)
-
原理:专门针对 Web 应用防护,检测 HTTP/HTTPS 流量,防护 SQL 注入**(SQL injection)、跨站脚本(cross-site scripting, XSS)**等 Web 层攻击;
-
特点:聚焦应用安全**(Focused on application security)**,普通防火墙管不了的 Web 攻击,只有 WAF 能有效防护;
-
适用场景:有网站、Web 系统、小程序的企业,是 Web 业务的必备防护工具。
-
10.1.7 数据包过滤防火墙(Packet Filtering Firewall)
接下来重点了解一下数据包过滤防火墙,这是防火墙最基础、最经典的技术形态,核心特点是成本低、对网络性能影响小(low impact on network performance),它分为 3 个子类型:
| 类型 | 核心逻辑 |
|---|---|
| 静态过滤(Static Filtering) | 提前写死固定的规则,数据包只要完全匹配规则,就直接执行放行或丢弃动作**(packet filter will drop or accept it)**,规则不会自动变化。 |
| 动态过滤(Dynamic Filtering) | 能理解网络协议的工作原理,根据包头信息和突发安全事件(比如攻击),自动更新或创建规则**(update or create rules)**来应对威胁。 |
| 状态检测(Stateful Packet Inspection,SPI) | 用状态表**(state table)记录内网和外网之间的每一条网络连接,不再孤立看单个数据包,而是跟踪数据包的会话上下文(keep track of each network connection)**。 |
包过滤防火墙的规则,主要如下面的流程:
1 | 源地址 → 目标地址 → 服务/端口 → 动作(允许/拒绝) |
10.1.7.1 静态包过滤防火墙
这是互联网最早的防火墙过滤机制,现在已经基本淘汰,不再作为边界防火墙的主过滤机制,仅作为大型网络的辅助过滤手段。
- 核心特点
- 无状态、孤立检查(Examines packets one at a time, in isolation):逐个、单独检查每个数据包,不看这个包和之前的数据包有没有关联,不记录会话上下文。
- 只看包头,不看内容(looks at some internet and transport headers):仅检查网络层、传输层的包头信息(源 / 目的 IP、端口、协议类型),不会解析数据包的内容。
- 不能防御绝大多数复杂攻击**(unable to stop many types of attacks)(因为它不看会话上下文,无法判断流量的合法性),但可以能拦截伪造源 IP 的欺骗攻击(can stop attacks Packets with spoofed IP addresses)**。
10.1.7.2 SPI 状态包检测防火墙
这是现在几乎所有企业边界防火墙都在用的主流技术,也是需要重点掌握的内容。
SPI 全称 Stateful Packet Inspection,状态包检测防火墙。它和静态过滤最大的区别是:
-
会检查相同的数据包 IP以及端口信息,还会用状态表完整记录有关TCP 连接的信息,
-
利用状态表跟踪**(Keeps track)**内部系统和外部系统之间建立的每个网络连接。
-
通过记录哪个站点在何时发送了什么数据包,来跟踪对话中每个数据包的每一条会话的状态、上下文(谁发的包、什么时候发的、属于哪个会话)。
-
SPI 防火墙能够判断一个入站数据包是否属于内网主动发起的合法会话**(legitimate sessions)**的返回包。
-
SPI 防火墙会维护包含每个活动连接信息的表,这些信息包括数据包的 IP 地址、端口和序列号。借助这些表,SPI 仅允许作为对内部网络发起**(initiated)的连接的响应(in response)的入站 TCP 数据包(inbound TCP packets)**。
但这么做也有缺点,那就是管理数据包以及根据状态表验证数据包需要额外的处理资源;极端情况下,攻击者可以用大量虚假连接打满状态表,造成 DoS 拒绝服务攻击**(expose the system to a DoS attack)**,导致防火墙瘫痪。
(1) SPI 的连接阶段
连接具有不同的状态或阶段,而一个网络连接可以分为 3 个阶段,每个阶段的攻击风险不同,SPI 会给不同阶段和状态设置不同的过滤规则**(different filtering rules)**:
- 连接打开阶段(Connection Opening State):比如 TCP 三次握手,建立连接的过程(仅占所有流量的 1%);
- 持续通信阶段(Ongoing Communication State):连接建立后,正常传输数据的过程(占所有流量的 99%);
- 连接关闭阶段(Connection Closing State):数据传输结束,断开连接的过程。
Example 1. 合法流量的放行流程
内网客户端60.55.33.12:4400主动访问外网的 Web 服务器123.80.5.34:80
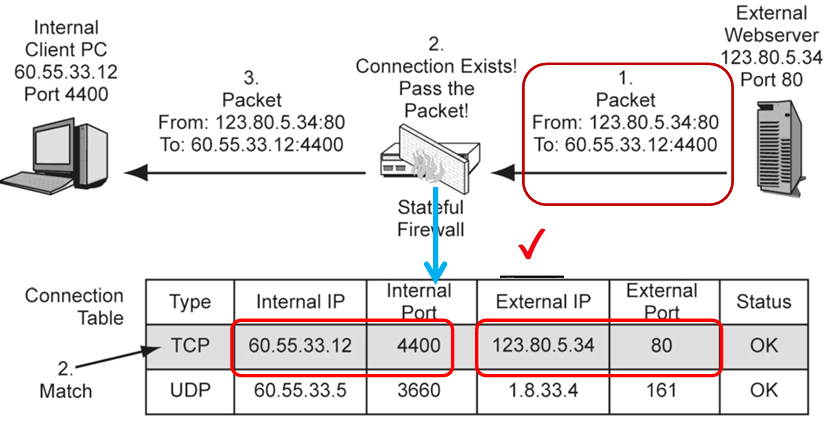
- 外网 Web 服务器给内网客户端返回响应数据包,源是
123.80.5.34:80,目标是60.55.33.12:4400; - 状态防火墙检查自己的连接表,发现里面已经有这条 TCP 连接的记录(内网主动发起,状态正常);
- 会话匹配成功,直接放行数据包,传给内网客户端。
Example 2. 伪造攻击包的拦截流程
攻击者伪造了一个数据包,假装是外网服务器发来的,源 IP 写成10.5.4.80,目标是内网客户端60.55.33.12:2121
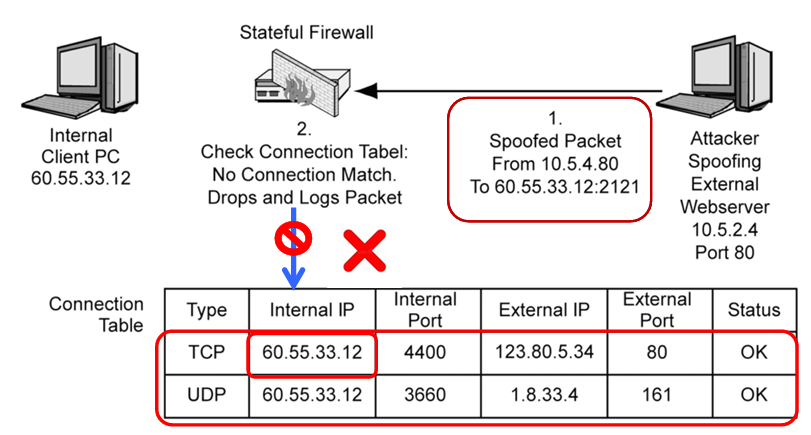
- 防火墙收到这个数据包,先查询自己的连接表;
- 连接表里根本没有这条连接的记录(内网客户端从来没有主动和
10.5.4.80建立过连接); - 没有匹配到合法会话,直接丢弃这个伪造包,同时记录攻击日志,把威胁拦在门外。
(2) SPI 防火墙的优势
- 低成本但高性能:99% 的流量都是已建立会话的数据包,处理逻辑极简,开销极低;仅 1% 的新建连接需要复杂处理,整体性能表现优秀。
- 高安全性(Safety):除了应用层攻击**(application-level attacks),绝大多数网络层攻击都无法穿透 SPI 防火墙,还可以搭配其他过滤方式增强防护(can use other forms of filtering)**。
- 市场绝对主导(Dominance):高安全以及低成本的优势,让 SPI 防火墙成为行业主流,现在几乎所有主流的边界防火墙**(main border firewalls),核心都是状态包检测技术(Stateful packet inspection)**。
10.1.8 应用程序网关/代理服务器(Application Gateway/Proxy Servers)
这是和包过滤完全不同的防火墙技术路线:包过滤是"检查数据包放不放行",而代理防火墙是 “替你和外网通信,内网和外网完全不直接接触”,实现极致的应用层安全。
应用程序网关通常安装在专用计算机上,也被称为代理服务器。一般放在网络的 DMZ 区(半信任的隔离区域,其一般介于外网[不可信的互联网]和内网[可信的企业内部网络]之间的隔离网段)。暴露给外网的只有代理服务器,真正的业务服务器(Web、数据库等)完全隐藏在内网,外网根本接触不到。同时,还可以在在代理服务器的内网侧,额外部署过滤路由器(包过滤防火墙),形成"应用层代理 + 网络层包过滤"的多层防护架构,进一步加固内网安全。
代理服务器还可以实现精细化的应用级流量管控。如果把应用网关配置为 Web 代理,它就只会放行 Web 相关的流量(HTTP/HTTPS),会直接拒绝 FTP、telnet、gopher 等其他所有非 Web 类型的流量。
另外,其也具备完整的应用层协议解析与访问能力(has full access to protocol)
- 用户向代理服务器请求服务**(User requests service from proxy)**。
- 代理验证请求是否合法**(Proxy validates request as legal)**。
- 然后处理请求并将结果返回给用户**(Then actions request and returns result to user)**。
这种方式通常比包过滤更安全:
-
只需仔细检查少数允许的应用程序**(only scrutinize a few allowable apps)**。
-
易于记录和审计所有传入流量**(Easy to log and audit all incoming traffic)**。
但这种方式的缺点也十分明显,由于所有流量都要经过代理来转发,会带来网络延迟和性能损耗。
Example 1. 应用防火墙通信流程(以 HTTP 代理为例)
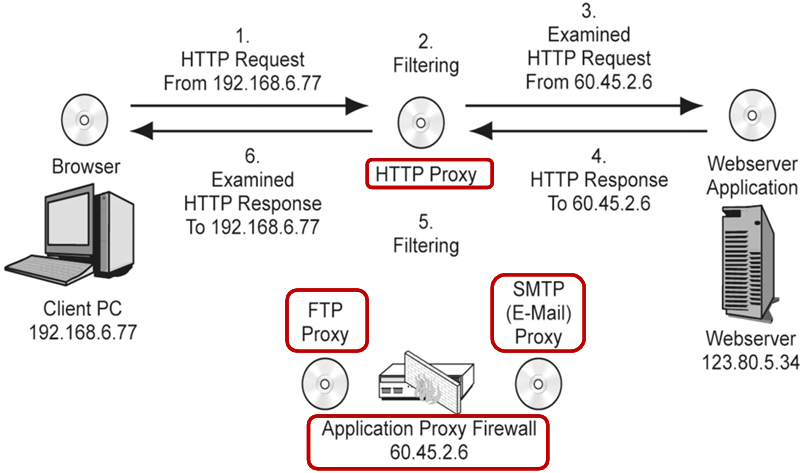
- 内网客户端
192.168.6.77的浏览器,把 HTTP 请求发给应用代理防火墙60.45.2.6; - 防火墙的 HTTP 代理模块,先过滤、检查请求是否合法;
- 检查通过后,代理防火墙用自己的 IP
60.45.2.6,替客户端向外网 Web 服务器发送 HTTP 请求; - Web 服务器把 HTTP 响应返回给代理防火墙;
- 代理防火墙再过滤、检查响应内容是否有恶意内容;
- 检查无误后,代理防火墙把响应返回给内网的客户端浏览器。
10.1.9 防火墙架构(Firewall Architechtures)
防火墙可配置为多种网络连接架构,适配不同的场景需求。最优架构的选择,取决于 3 个核心因素:网络的建设目标、企业的技术落地能力、可用预算。3 种最常见的防火墙架构包括了数据包过滤路由器(Packet Filtering Routers)、屏蔽主机防火墙(Screened Host Firewalls)、屏蔽子网防火墙(Screened Subnet Firewalls)。
10.1.9.1 数据包过滤路由器(packet filtering routers)
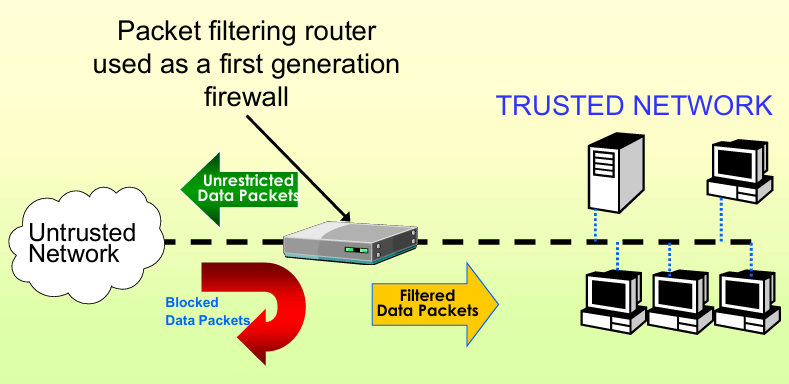
- 绝大多数接入互联网的企业,都会用路由器作为互联网接入接口;
- 这类路由器可配置包过滤规则,拒绝非法数据包进入内网;
- 核心缺点:缺乏审计能力和强身份认证能力,仅能做基础的包头部匹配,无应用层防护能力,防护能力极弱。
10.1.9.2 屏蔽主机防火墙(screened host firewalls)
把数据包过滤路由器和专用防火墙(dedicated firewall)(如应用代理服务器,也叫堡垒主机)结合,形成双层防护:外网流量先经过包过滤路由器做预过滤(prescreen packets),拦掉明显非法的流量,降低内部代理服务器的负载和攻击压力,剩余流量再交给专用防火墙做应用层深度校验。
而屏蔽主机防火墙中有两种不同的架构:
(1) 单主机架构(Single Host Firewall)
- 工作流程:
- 外网流量先经过包过滤路由器,非法流量直接阻断,合规流量仅能转发给堡垒主机;
- 堡垒主机对流量做应用层校验和代理,校验通过后,再以代理访问的方式,把请求转发给内网设备;
- 内网返回的流量,也必须先经过堡垒主机,再经过包过滤路由器,才能发到外网。
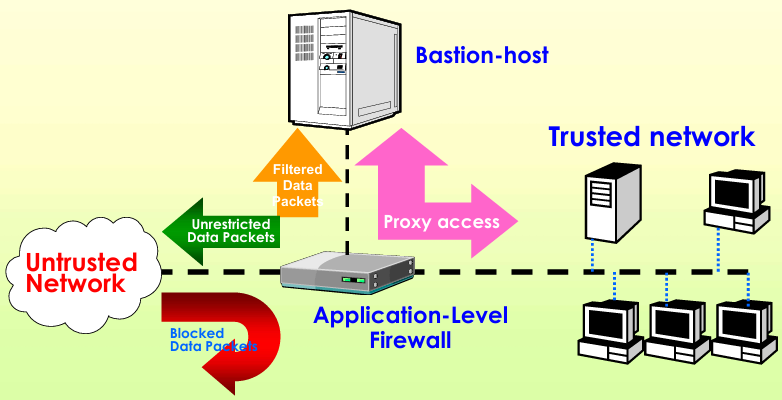
- 结构:单个防火墙(称为堡垒主机**(bastion host)或牺牲主机(sacrificial host)**)部署在内网和互联网之间(placed between the internal network and the internet),和包过滤路由器配合;
- 特点:结构简单,但专用防火墙是单点,一旦被攻击者攻陷,整个内网就完全暴露,变得很脆弱(vulnerable);专用防火墙是外网唯一能直接访问的设备,是外部攻击的核心目标(be target for external attacks),必须做极高强度的安全加固。
(2) 双宿主主机架构(Dual-Homed Host Firewall)
- 工作流程:
- 外网流量先经过外部过滤路由器做预过滤,仅能发给双宿主主机,无法直接访问内网;
- 双宿主主机对流量做校验、代理、NAT 转换后,把合规流量转发给内部过滤路由器,再发给内网设备;
- 内网对外流量,必须先经过内部过滤路由器,再经过双宿主主机的代理和 NAT 转换,才能发到外网。
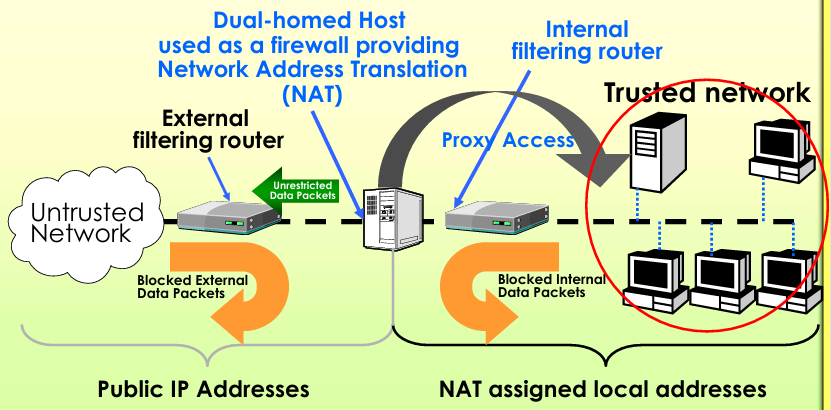
- 结构:防火墙主机有两个网络接口**(two network interfaces)**,一个连互联网,一个连内网,两个网络之间无直接路由连通,内外网是两个完全隔离的地址段 —— 外网侧是公网 IP,内网侧是 NAT 分配的私有地址,所有流量必须经过防火墙转发管控;
- 特点:比单主机架构多了一层隔离,NAT 功能隐藏了内网地址结构,因此比单主机架构更安全,彻底切断了内外网的直接路由,但依然是单点设备,存在单点故障风险**(single point of failure)**。
10.1.9.3 屏蔽子网防火墙(Screened Subnet Firewalls)
用内外两个包过滤防火墙(路由器),创建出一个隔离的非军事区(Demilitarized Zone, DMZ),企业对外提供服务的服务器(Web、邮件服务器等)都放在 DMZ 中。通过 DMZ 把内网系统和互联网彻底隔离,形成额外的安全层**(additional security layer)**,就算 DMZ 里的服务器被攻陷,攻击者也无法直接访问内网。
突出的优势:
-
形成三级防御体系(three levels of defense),攻击者要攻破内网,必须先后突破外部路由器、DMZ 设备、内部路由器三层防护,攻击难度极大;
-
外部路由器仅向互联网宣告 DMZ 网段的存在(only the existence of the screened subnet),因此内网的地址、结构对互联网完全不可见(invisible to the Internet);
-
内部路由器仅向内网宣告 DMZ 网段的存在,内网设备无法直接访问互联网(cannot construct direct routes to the Internet),所有对外访问必须经过 DMZ 的代理设备;
防火墙是网络安全的核心,但必须配合入侵检测系统**(intrusion detection systems, IDS)、终端防护(endpoint protection)等措施。单靠防火墙无法防御所有网络威胁,采取分层安全策略(a layered security approach)**是必要的。
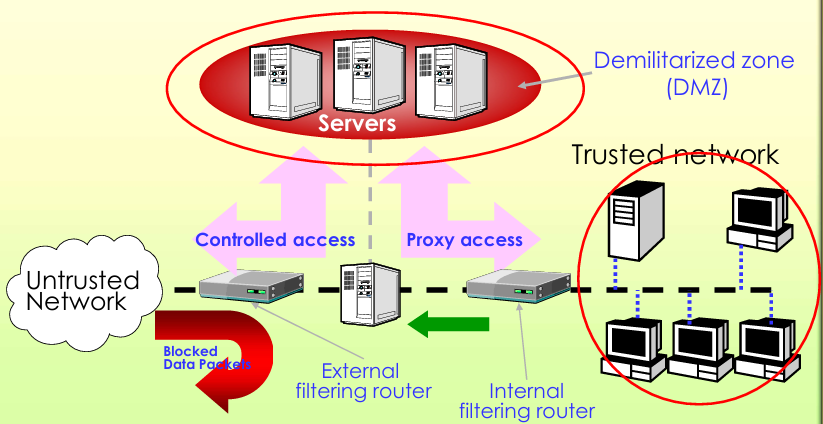
-
最外侧:不可信网络(互联网)
-
第一层防护:外部过滤路由器,连接互联网和 DMZ,阻断外网非法流量,仅允许外网访问 DMZ 内的服务器
-
中间隔离区:DMZ(非军事区),放置对外服务的服务器,是外网唯一能访问到的区域,和内网完全隔离
-
第二层防护:内部过滤路由器,连接 DMZ 和可信内网,仅允许 DMZ 的代理设备访问内网,阻断任何外网设备直接触达内网
-
最内侧:可信内网,企业的内部终端、核心业务服务器都在这里,完全不对外暴露
10.1.10 防火墙性能计算(Performance Calculation)
这部分是量化评估防火墙能不能扛住对应链路的流量负载,核心性能指标是pps(Packets Per Second,每秒数据包处理数)。防火墙是逐包处理流量的,哪怕链路带宽足够,pps 处理能力不足也会出现拥堵、丢包。需要重点掌握,考试必考。
Example 1:
已知条件:
防火墙最大处理能力为200,000 pps(每秒最多处理 20 万个数据包),网络平均包大小(Average packet size)为1000 bytes,链路带宽(Link speed)为1 Gbps,那么这个防火墙是否能承载该链路的满负载流量?
Solution:
-
**Step 1: ** 计算链路满载时,需要的 pps(每秒要处理的包数量)
首先做单位统一:1 byte = 8 bits,因此 1 个 1000 字节的数据包,总比特数为
因此,所需 pps = 链路总带宽 ÷ 单包比特数
-
Step 2: 对比防火墙能力与需求
防火墙处理能力
Example 2:
已知条件:
防火墙最大处理能力:100,000 pps,网络平均包大小(Average packet size)为1000 bytes,链路带宽(Link speed)为1 Gbps,那么这个防火墙是否能承载该链路的满负载流量?
Solution:
-
**Step 1: ** 因为平均包大小、链路带宽和 Example 1 完全一致,因此所需 pps 依然是 125,000 pps。
-
Step 2:
防火墙处理能力 100,000 pps < 所需 125,000 pps,因此该防火墙无法承载当前链路的流量负载,会出现拥堵、丢包。
相同带宽下,数据包越小,所需 pps 越高,防火墙的压力越大。比如同样 1G 带宽,64 字节的小包所需 pps,是 1000 字节大包的十几倍,因此 pps 是防火墙的核心硬性能指标。
10.1.11 传统边界防火墙安全模型的消亡(The Death of The Perimeter in Firewall Security)
传统基于边界 Perimeter的安全模型防火墙的设计,是把防火墙放在企业内网和互联网的边界,其是网络边界的主要防御核心,依据是假设是企业内网的所有设备、流量都是可信的,外网的所有内容都是潜在威胁。靠防火墙把 “可信内网” 和 “不可信外网” 彻底隔开,形成固定的安全边界。但如今这个固定边界的概念已经完全瓦解。导致边界失效主要有下面 5 个原因:
-
云计算(Cloud Computing)
企业不再把数据、业务只存在本地机房的服务器,而是大量迁移到 AWS、Azure、谷歌云等公有云环境**(store data in cloud environments),数据本身就不在传统内网边界里;同时员工可以从任何地点访问云资源(access corporate resources from anywhere),直接绕过了企业本地的边界防火墙(bypassing traditional firewalls)**,传统防火墙无法管控云内流量。
-
远程办公与BYOD(自带设备)(Remote Work and BYOD(BringYour OwnDevice))
员工大量使用个人设备**(use personal devices)、家庭网络(home networks)访问企业数据(access corporate data),这些设备和网络不在企业内网的边界范围内,传统防火墙无法对远程用户、个人设备有效执行安全策略(can’t enforce security policies)**,固定边界的管控完全失效。
-
零信任安全模型(Zero Trust Security Model)
零信任的核心原则是 “永不信任,始终验证(Never trust, always verify)”,彻底替代了传统基于边界的信任逻辑。访问权限不再由"你在内网还是外网"(网络位置)决定,而是基于身份、访问上下文、最小权限原则**(granted based on identity, context, and least privilege)** , 哪怕你在内网,每次访问也要做完整验证,传统的 “内网默认可信” 逻辑完全不成立。
-
加密流量(TLS/SSL)的普及(Increased Use of Encrypted Traffic(TLS/SSL))
如今绝大多数网络流量都是加密的,攻击者也会利用加密流量传输恶意内容,传统防火墙很难解密、检测加密流量里的威胁**(harder for firewalls to inspect traffic);同时攻击者会用 SSL/TLS 隧道技术,把恶意流量封装在加密隧道(SSL/TLS tunneling)里,直接绕过传统防火墙的检测(bypass traditional firewalls)**。
-
复杂定向攻击的兴起(Rise of Sophisticated Threats)
现在的黑客、恶意软件,不再从外网硬闯防火墙,而是通过钓鱼邮件**(phishing)、内部威胁(insider threats)、泄露的账号凭证(compromised credentials),直接渗透(infiltrate networks)到内网里。攻击者一旦进入内网,传统边界防火墙就完全失效(ineffective)** 。因为它默认内网是可信的,不会管控内网横向移动的攻击流量。
那么我们还需要防火墙吗?
答案是肯定的,需要,但只靠防火墙远远不够;防火墙不是消亡了,而是在持续演进,需要和现代安全体系整合。
-
下一代防火墙(Next-Generation Firewalls, NGFW)
这是传统防火墙的升级替代方案,核心能力包括:深度包检测**(deep packet inspection, DPI)、入侵防御(intrusion prevention, IPS)、应用层精细化过滤(application layer filtering)、基于机器学习的威胁检测(machine learning-based threat detection);同时可以解密检测加密流量(inspecting encrypted traffic)、监控用户行为(monitoring user behavior),落地零信任的访问控制原则(Can enforce Zero Trust principles)**,弥补了传统防火墙的所有核心短板。
-
云防火墙(Firewall-as-a-Service, FWaaS)
专为云原生、远程办公场景设计,无需本地硬件防火墙**(without requiring on-premises firewall hardware),直接在云端交付安全能力;可以保护云工作负载(cloud workloads)**和远程用户,把安全边界从本地机房延伸到云端。典型产品包括 Zscaler、Palo Alto Prisma、Cloudflare Gateway。
-
网络分段(Network Segmentation)
不再依赖单一的边界防火墙**(single perimeter firewall),而是把企业内网拆分成多个相互隔离的小网段(divide networks into smaller isolated zones),每个网段都有独立的访问控制。哪怕攻击者攻破了一个网段(breaches one segment),也无法在整个内网横向移动(can’t move freely across the network)**,把攻击限制在最小范围,相当于在网络内部加了多道 “微型防火墙”。
边界是转移而不是消失了
- 所谓 “网络边界已死” 是误导性**(misleading)的,实际是边界从固定的物理机房边界,变成了动态、去中心化(dynamic and decentralized)**的边界;
- 只在网络边缘**(at the network edge)放一台防火墙,已经不足以保护企业资产(no longer enough to secure corporate assets),但防火墙依然是网络安全的核心基础组件,防火墙正在演进,而非走向消亡,防火墙仍是网络安全的关键组成部分,但不再是唯一的防线(no longer the only line of defense)**,我们需要升级适配新的场景;
- 企业不应该抛弃防火墙**(should not abandon firewalls),而是要把它和零信任、终端安全、云安全等现代安全策略整合在一起(integrate them with modern security strategies)**;
- 新的安全边界,已经从固定的物理位置**(shifted from a fixed location),变成了基于身份的流动模型(a fluid, identity-based model),也就是安全策略跟着用户、设备、数据走,而不是绑定在物理网络上(being tied to a physical network)**。
10.2 入侵检测系统(Intrusion Detection System, IDS)
入侵检测系统(Intrusion Detection System, IDS)是一种安全机制,核心作用是监控网络或系统活动(monitor network or system activities),识别恶意行为(malicious behavior)(如攻击、异常访问),相当于网络的 “监控摄像头”,能发现威胁并告警,但本身不阻断攻击。
-
IDS 的 4 个优势:
- 早期威胁检测(Early Threat Detection):在攻击造成严重破坏前识别异常行为**(Identifies suspicious activities)**,为响应争取时间。
- 实时监控(Real-Time Monitoring):持续分析系统日志**(Continuously analyzes system)和网络活动(network activity)**,实现 7×24 小时动态监测。
- 取证分析支撑(Forensic Analysis):完整记录攻击日志**(logs and records of attack attempts)**,支持事后溯源、分析攻击路径。
- 安全合规辅助(Security Policy Enforcement):帮助企业满足等保、PCI-DSS 等监管安全法规要求**(comply with security regulations)**,提供审计依据。
-
入侵检测系统的劣势
-
误报(False Positives):异常检测可能把正常活动(如业务高峰流量)判定为威胁**(flag normal activity as a threat)**,产生无效告警。
-
漏报(False Negatives):特征检测无法识别无对应规则的新型攻击**(miss new, evolving threats)**(如零日漏洞攻击)。
-
资源消耗高(High Resource Consumption):处理全网流量需要较高的计算资源**(requires computing power)**,可能影响网络性能。
-
无主动防护能力(No Active Protection):仅检测和警报**(only detects and alerts),不阻断攻击(block attacks)**(这是 IDS 与 IPS(入侵防御系统) 的核心差异)。
10.2.1 IDS的类型
| 分类维度 | 类型 | 核心特点 |
|---|---|---|
| 按部署位置 | 主机型 IDS(Host-based IDS, HIDS) | 部署在单台主机上,监控主机内部活动 |
| 网络型 IDS(Network-based IDS, NIDS) | 部署在网络中,监控网段内的所有流量 | |
| 按检测方法 | 特征检测(Signature-based IDS) | 依赖一组预定义的攻击特征库来比对流量模式,识别已知攻击 |
| 异常检测(Anomaly-based(heuristic) IDS) | 监控活动并尝试将其分类为"正常"或"异常",基于正常流量基线,识别偏离行为,可检测未知攻击 |
10.2.1.1 网络型 IDS(NIDS)
基于网络入侵检测系统**(Network-based IDS, NIDS)是解析网络通信量(parse network traffic)的引擎(engines)。除了捕获(capturing)所有网络流量外,网络入侵检测系统还会将这些流量与一组预先分类的攻击特征码进行比对(compare the traffic with a set of pre-classified attack signatures)。一旦在网络数据包中发现某个特征码(Once a signature is found),就会启动保护措施(protective action is launched),阻止攻击并记录相关信息(the attack is stopped and logged)。网络入侵检测系统引擎的部署十分简便(easily deployed),无需对网络进行重大修改(without suffering major network modifications)**。
NIDS 是解析网络流量的引擎,大概组件就是上图所包括的:
1 | 网络流量 → 流量收集器(抓包) → 分析引擎(核心,同时比对特征库) → 生成告警(本地/中心存储) → 用户界面/报表 |
- 优点:
- 提供入侵检测系统覆盖所需的系统更少;
- 部署**(Deployment)、维护(maintenance)和升级(upgrade)**成本通常更低;
- ANIDS 能够洞察所有网络流量,并且可以关联多个系统之间的攻击**(can correlate attacks among multiple systems)**。
- 缺点
- 加密流量盲区:无法解析 HTTPS 等加密流量的内容,无法检测加密流量中的攻击。
- 主机内部盲区:看不到主机的进程**(doesn’t know about activity on the hosts)**、文件修改等活动,无法检测主机级攻击(如恶意进程)。
10.2.1.2 主机型 IDS(HIDS)
HIDS仅监控特定主机(specific host),通过检查主机日志**(Examines logs)、审计轨迹(audit trails)、进出流量(network traffic coming into or leaving)识别异常,可能触发告警(raise the alarm)**的典型场景包括:
- 多次登录失败**(Login failures)**
- 非规律时间登录**(Logins at irregular hours)**
- 权限提升操作**(Privilege escalation)**(如普通用户获取管理员权限)
- 新增未知用户账户**(Additions of new user accounts)**
-
优势:
- 可以针对特定操作系统优化**(operating system-specific)**;
- 可以降低误报率**(reduce false-positive rates)**;
- 可以检查已解密的数据**(examine data after it has been decrypted)**;
- 可以针对特定应用程序**(very application specific)**;
- 能检测文件篡改、进程异常等主机内部攻击,可以确定警报会对系统产生何种影响**(determine how an alarm will impact a system)**。
-
缺点:
- 必须处理您想要监视的每个系统上的信息**(process information on every system)**;
- 拥有和维护**(ownership and maintenance)**成本可能很高;
- 使用本地系统资源**(Uses local system resources)**,消耗主机的 CPU、内存,可能影响业务性能。
HIDS又可以被分为三种形式:
-
被动型HIDS(Passive HIDS):监控活动、对其进行分析并生成警报;
-
主动型HIDS(Active HIDS):具备与被动型主机入侵检测系统相同的功能,并且能够对活动做出反应**(react to activity),可能会运行脚本或终止进程(running a script or terminating a process)**。
-
现代HIDS(ModernHIDS):通常被称为基于主机的HIPS,在被动检测的基础上增加主动防御能力,并使用以下组件来防止攻击:
- 集成系统防火墙**(Integrated system firewall)**
- 基于行为和特征的IDS**(Behavioral- and signature-based IDS)**
- 恶意软件检测与防御**(Malware detection and prevention)**
现代HIDS主要有两种:
-
基于签名的IDS(Signature-Based IDS)
-
它也被称为基于知识的IDS**(knowledge-based IDS)**。
-
它会检查数据流量,寻找与特征相匹配的内容**(matches signatures),这些特征是预先配置好的(pre-configured)、既定(predetermined)**的攻击模式。
-
问题:随着新的攻击策略被发现,特征必须不断更新**(must be continually updated)**。
-
-
基于统计异常的IDSS(Statistical Anomaly-Based IDS)
- 它也被称为基于行为的IDS**(behavior-based IDS)**。
- 它会从正常流量中收集数据并建立基准线**(establishes a baseline)。基准线建立后,会基于统计方法定期对网络活动进行采样(periodically samples network activity),并将样本与基准线进行比较(compares samples to baseline)。如果活动超出基准线参数(outside baseline parameters)(称为阈值(clipping level)),IDS会通知管理员(notifies administrator)**。
- 该系统能够检测新型攻击**(able to detect new types of attacks),因为它会寻找任何类型的异常活动(looks for abnormal activity)。此外,它可能无法检测到微小变化(may not detect minor changes),并且可能会产生许多误报(generate many false positives)**。
10.3 入侵防御系统(Intrusion Prevention Systems, IPS)
入侵防御系统(Intrusion Prevention System, IPS) 是一种主动安全技术(proactive security technology),可实时检测和阻止恶意活动**(detects and blocks malicious activities)。与仅检测威胁并生成警报(only detect threats and generate alerts)的IDS不同,IPS 通过阻止恶意流量来主动阻止攻击(prevents attacks by blocking malicious traffic)**。IPS 通常集成到下一代防火墙 (NGFW)中,以实现高级网络安全。
IPS 是 IDS 的"主动升级版本",弥补了 IDS "只告警不阻断"的不足:
| 维度 | IDS | IPS |
|---|---|---|
| 核心功能 | 被动检测 + 告警 | 主动检测 + 实时阻断 |
| 部署方式 | 旁路监听(不影响流量转发) | 在线部署(流量必经路径) |
| 响应动作 | 仅日志/告警,不阻断攻击 | 直接丢弃恶意流量、阻断攻击连接 |
| 典型场景 | 事后取证、安全审计 | 实时防护、主动拦截攻击 |
| 典型工具 | Snort, Zeek, OSSEC | Palo Alto NGFW, Suricata(可做 IDS/IPS), Cisco Firepower |
现代 IPS 常集成在 下一代防火墙(NGFW) 中,结合防火墙、IDS/IPS、应用识别等功能,实现一体化安全防护。
10.4 蜜罐系统(Honeypot System)
蜜罐系统就像一个故意暴露、有漏洞的"假电脑/假系统"诱饵**(decoy),专门吸引黑客攻击(attract cyberattacks)**,并且收集情报。
其作用就是模仿黑客的目标**(mimics a target for hackers),让他们以为这是真实目标,趁机观察他们的攻击手法、工具和思路(gain information about cybercriminals and the way they are operating);并分散黑客注意力(distract them from other targets)**,保护真实系统;以及可以用来研究新型攻击、优化真实系统的安全防护。
蜜罐看起来像一个真实的计算机系统**(real computer system),带有应用程序和数据,欺骗网络犯罪分子认为它是一个合法的目标(fooling cybercriminals into thinking it’s a legitimate target)。例如,蜜罐可以模仿公司的客户计费系统,这是想要查找信用卡号的犯罪分子经常攻击的目标。一旦黑客进入,就可以跟踪他们,并评估他们的行为(their behavior assessed),以获取有关如何使真实网络更安全的线索。通过构建蓄意的安全漏洞(building in deliberate security vulnerabilities),蜜罐对攻击者具有吸引力。蜜罐安全有其局限性,因为蜜罐无法检测合法系统中的安全漏洞(cannot detect security breaches in legitimate systems)**,并且它并不总是能识别攻击者。
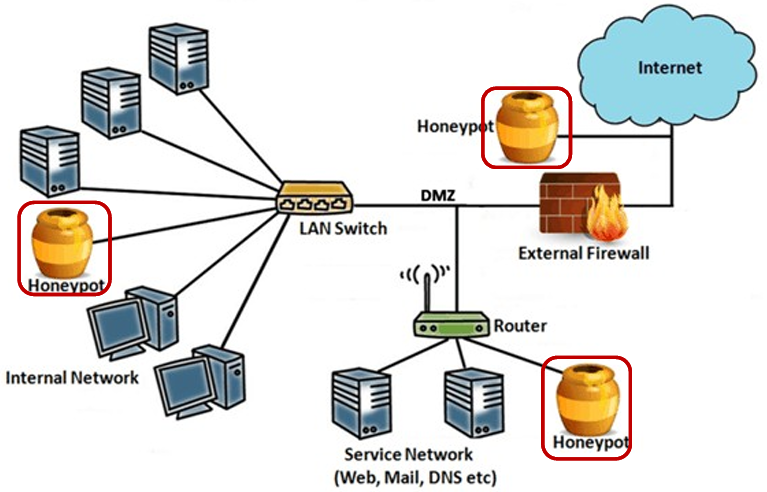
蜜罐可以放在不同位置,针对性地收集情报:
- 放在互联网出口:吸引外部黑客攻击;
- 放在内部网络:检测已经突破边界的内网横向攻击;
- 放在服务网络:模拟 Web、邮件等常见服务,诱捕针对这些业务的攻击。
遭受网络攻击后,企业会承受的几类核心损失:
- 财务损失(Financial implications):从几万到几百万美元不等,还不算后续修复、合规罚款的成本。
- 生产力损失(Productivity costs):攻击后需要花大量时间修复系统、处理故障,IT 团队和员工的工作都会被打乱,直接影响业务利润。
- 业务中断(Operational disruption):影响供应链、服务交付,导致物流延迟、业务停摆,连锁反应会波及整个企业流程。
- 声誉损失(Reputational damage):用户数据泄露会让客户失去信任,很难再挽回口碑,甚至直接导致客户流失。




