数字电路子系统设计
1 通用数字系统组成
一个标准数字系统由数据通路(Datapath)、控制单元(Control Unit)、存储器(Memory)、输入/输出模块(Input/Output Modules) 四个模块构成,通过互连网络(Interconnect)strong>将各模块连接,实现数据处理、存储与交互。
1.1 数据通路(Datapath)
数据通路是系统的核心,所有计算/逻辑运算都在这里完成。主要由逻辑门(与非门、异或门等)、算术模块(加法器、乘法器等)互连而成,还包含寄存器(暂存中间结果)。计算结果存到 Memory 中;操作顺序由控制单元决定。
1.2 控制单元(Control Unit)
控制单元主要是决定数据通路在任意时刻执行的操作,是系统的"指挥官"。它可以被视为有限状态机(FSM),由寄存器(触发器)和逻辑电路组成,属于时序电路(有记忆功能)。
1.3 存储器(Memory)
其实就是集中式数据存储区。
- 分类与作用
- 寄存器:存单个数据,可同时访问;
- ROM/RAM:存批量数据,一次仅访问 1-2 个。
1.4 输入/输出(Input/Output)
用来连接系统内部电路与外部世界。
- 输入保护:含保护电路,两个二极管将输入电压钳制在
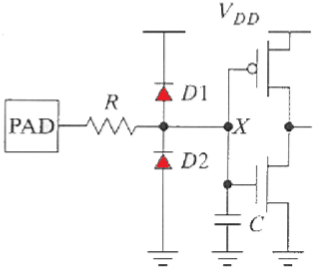
1.5互连(Interconnect)
连接各模块,分为总线式、点对点式等。
互连可以使得多个模块可连接,但同一时间仅一个模块能写总线;所有连接到总线的模块,输出端必须加三态缓冲器,避免总线冲突。
- 三态缓冲器是数字电路的总线专用核心器件,和普通反相器/缓冲器的区别是:
- 普通门电路只有逻辑 0、逻辑 1两种输出状态;
- 三态缓冲器多了高阻态(High-Z,也叫浮空态):相当于输出端和电路 “物理断开”,完全不影响总线上的其他信号。
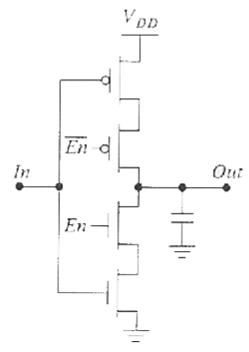
- 上图是反相型三态缓冲器(Inverting Tri-state Buffer):
- 使能端
En=1(高电平):缓冲器正常工作,输出 = 输入取反(Out = NOT In); - 使能端
En=0(低电平):缓冲器关闭,输出进入高阻态,和总线完全断开。
- 使能端
2 算术模块
数字系统里负责数据运算的数据通路,核心就是算术模块,最常用的三类:
- 移位器、加法器(减法器)、乘法器。
2.1 移位器(Shifter)
移位操作本质就是乘或除以2的n次方(左移 1 位
-
移位寄存器的缺点:每个时钟只能移 1 位,要移多位需要多个周期,速度慢,不适合单周期多位移位。
-
固定移位的实现:移位方向、位数固定时,直接用硬件连线改接即可(硬连线移位器)。
-
移位器四大类:硬连线移位器、可编程移位器、桶形移位器、对数移位器。
下面讲一下逻辑移位和算术移位:他们的区别就在于是否把数据当成有符号补码数,其右移补位规则不同
| 移位类型 | 针对数据 | 左移规则 | 右移规则 |
|---|---|---|---|
| 逻辑移位 | 无符号数 | 所有位左移,右侧空出补 0,左侧位移数丢弃 | 所有位右移,左侧空出补 0,右侧位移出丢弃 |
| 算术移位 | 有符号补码数 | 同逻辑左移(右侧补 0),注意可能溢出 | 所有位右移,左侧空出补原符号位(最高位),右侧位移出丢弃(保证符号不变): 原最高位是 1(负数)→ 补 1 原最高位是 0(正数)→ 补 0 |
💡 举个例子:8 位有符号数 - 1(补码11111111)
- 算术右移 1 位:
11111111(还是 - 1,正确) - 逻辑右移 1 位:
01111111(变成 127,完全错误)
2.1.1 硬连线移位器(Hard-Wired Shifter)
固定移位位数、方向,直接用硬件连线把输入位接到对应输出位,空位补 0。
其特点就是结构极简、速度快,但完全不灵活,只能实现一种固定移位(比如只能右移 3 位),仅用于模块间固定的移位需求。
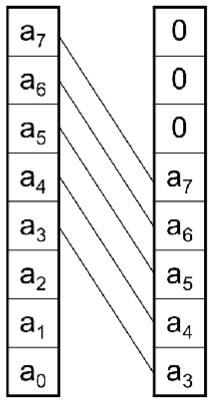
- 例子:8 位数
2.1.2 可编程移位器(Programmable Shifter)
基础单元是 1 位左右移单元,可选择左移 1 位、右移 1 位、不移动(unchanged)。
- 多位实现:把多个 1 位单元级联,实现任意位数移位。
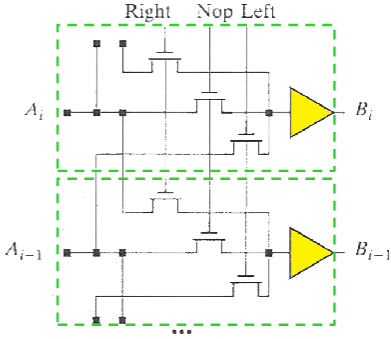
- 缺点:级联单元越多,电路越大、延迟越高(速度慢),不适合大位宽。
2.1.3 桶形移位器(Barrel Shifter)
用晶体管阵列实现,行数 = 数据位数,列数 = 最大移位位数,每个输出位可通过传输门选择任意输入位。
桶形移位器无论移多少位,延迟都固定(仅经过 1 个传输门),单周期可以完成任意移位,速度极快。但缺点是需要解码器生成控制信号,电路面积大(n 位数需要
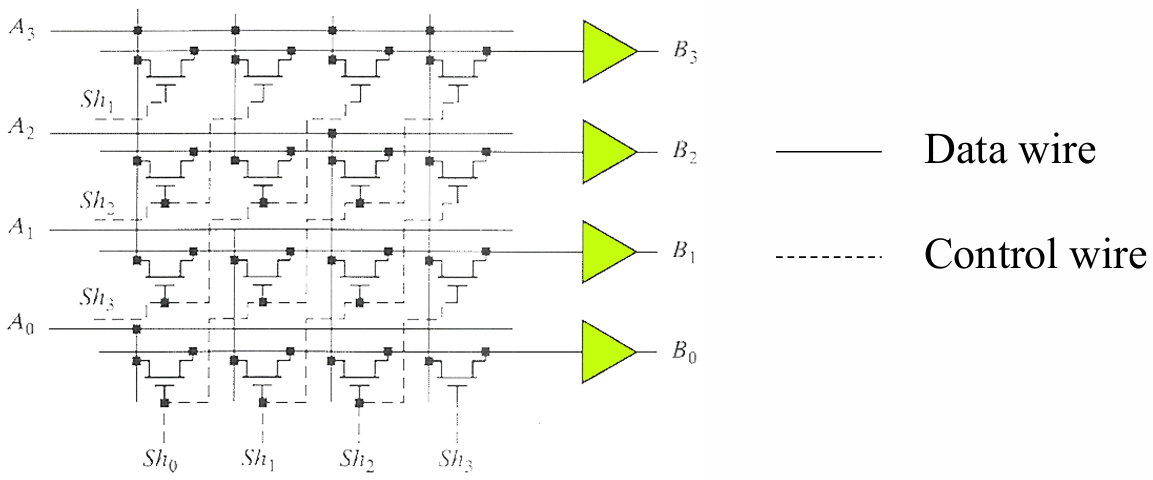
同样控制输入只能同时有一个为"1"。当
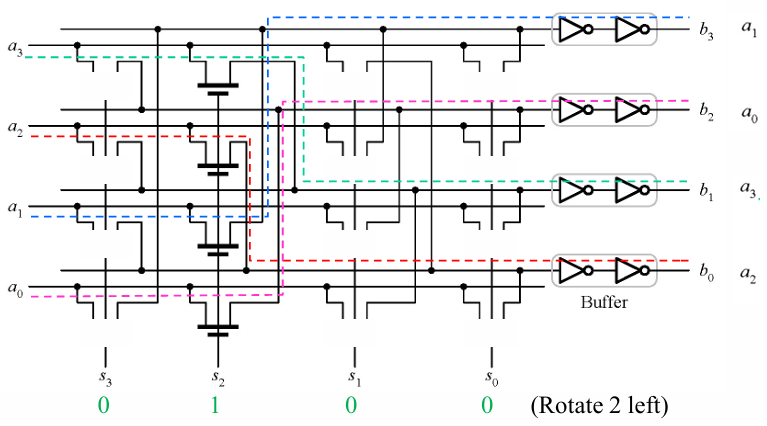
这是桶形移位器的一个特殊形式,旋转意味着 LSB 不会丢失,而是会被补充到 MSB。左移就是这里的下移。
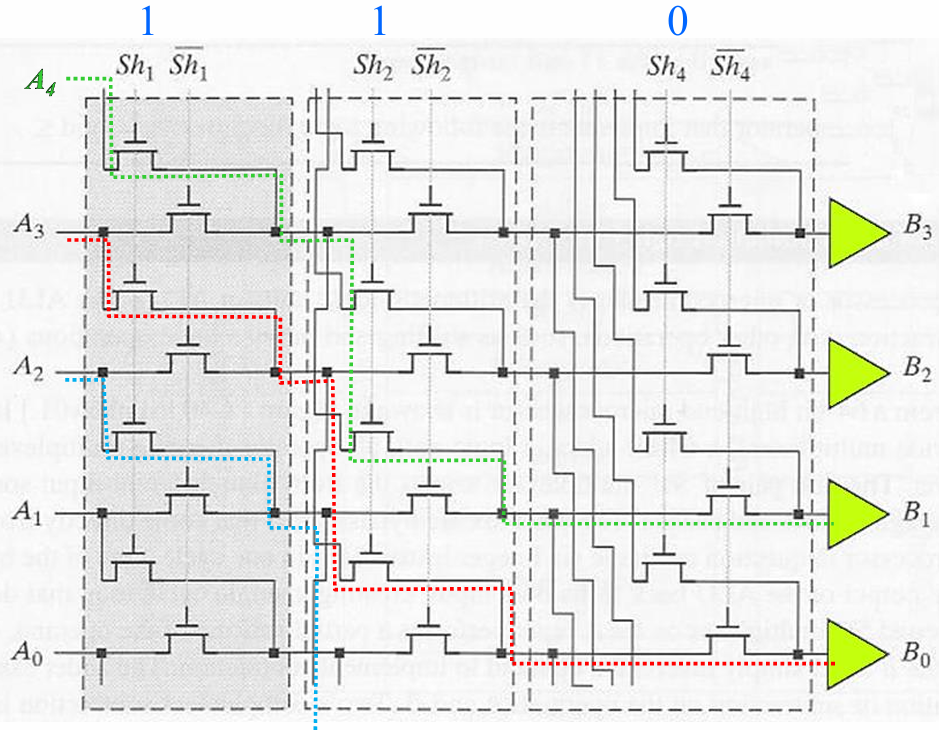
2.1.4 对数移位器(Logarithmic Shifter)
把总移位位数拆成2的幂次(比如移 3 位 = 移 2 位 + 移 1 位,3=2+1),用
对比桶形的核心优势:
- 控制信号是编码的,数量少,不需要解码器;
- 大位宽下面积更小、速度更快(n 位数仅需 n×log₂n 个晶体管);
- 更适合大移位位数的场景。
延迟:对数级延迟(比如最大移 7 位,仅需 3 级),比桶形固定延迟略高,但远快于级联的可编程移位器。
2.2 加法器
加法是数字系统中所有算术操作的基石,乘法、除法、移位、地址计算等功能都依赖加法实现,是 ALU 的核心功能。但多位加法的进位链延迟是限制芯片主频的关键因素,因此加法器的性能直接决定了整个数字系统的运行速度。
加法器优化的两个层级:
| 优化层级 | 核心思路 | 典型工程方法 |
|---|---|---|
| 逻辑级优化 | 重排布尔方程,消除冗余、缩短关键路径 | 超前进位加法器(CLA)、进位选择加法器(CSLA)、进位旁路加法器(CBA) |
| 电路级优化 | 调整晶体管尺寸、电路拓扑,优化时序 / 功耗 / 面积 | 传输门逻辑、多米诺动态逻辑、镜像加法器、混合逻辑结构 |
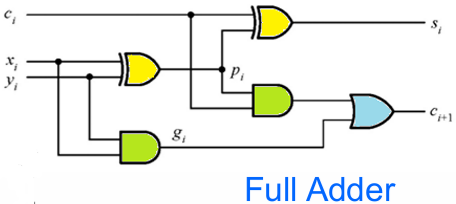
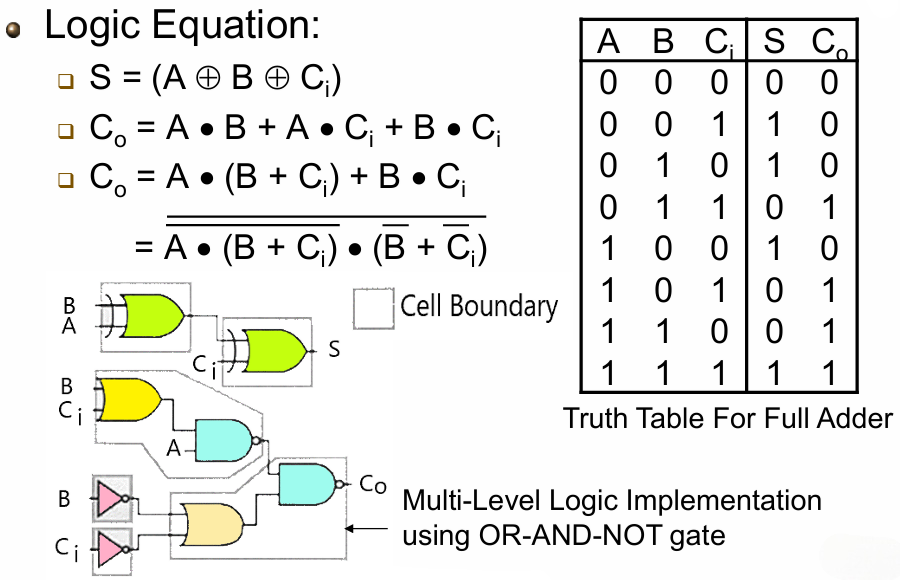
2.2.1 全加器(Full Adder)
全加器是1 位二进制加法的基础单元,是构建所有多位加法器的核心模块。
先来看各端口定义:
| 端口类型 | 信号名 | 含义 |
|---|---|---|
| 输入 |
|
两个 1 位二进制加数 |
| 输入 |
|
来自低位的进位输入 |
| 输出 |
|
本位和(1 位) |
| 输出 |
|
向高位的进位输出 |
为了得出布尔式,我们需要完整覆盖所有输入组合的输出,写出其真值表:
a |
b |
cᵢ |
s |
cₒ |
|---|---|---|---|---|
| 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 1 | 1 | 0 |
| 0 | 1 | 0 | 1 | 0 |
| 0 | 1 | 1 | 0 | 1 |
| 1 | 0 | 0 | 1 | 0 |
| 1 | 0 | 1 | 0 | 1 |
| 1 | 1 | 0 | 0 | 1 |
| 1 | 1 | 1 | 1 | 1 |
最终可以得到如下式子:
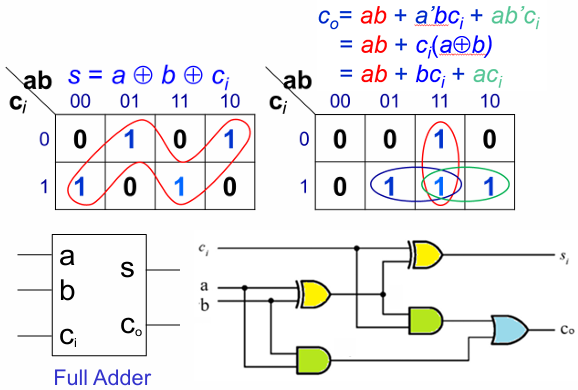
- 红色圈出的是
- 蓝色 / 绿色圈出的是
上图右下角则是给出了全加器的标准电路结构:
- 用2 个异或门实现
- 用2 个与门和 1 个或门实现
2.2.2 行波进位加法器(Ripple-Carry Adder, RCA)
n 位加法器由 n 个全加器级联构成:初始进位
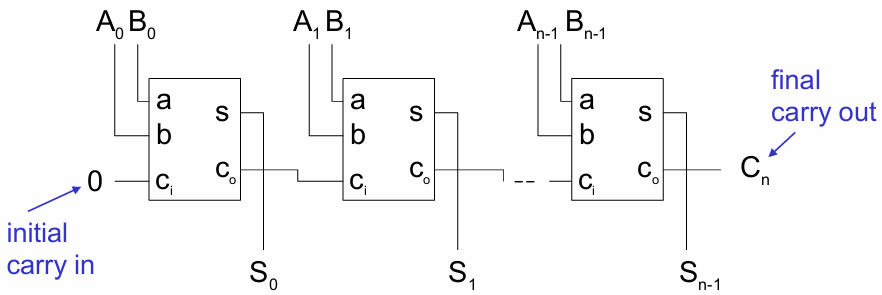 很重要的一环是延迟分析,我们取最坏情况进行解释:进位从最低位(LSB)全程传播到最高位(MSB),例如 8 位加法:01111111+00000001=10000000。
很重要的一环是延迟分析,我们取最坏情况进行解释:进位从最低位(LSB)全程传播到最高位(MSB),例如 8 位加法:01111111+00000001=10000000。
-
延迟公式:
-
-
-
由于加法器的关键路径在进位链,所以必须最小化每个全加器的进位延迟。为了减少延迟,我们需要先了解一下全加器单元的反演特性(Inverting Property):
-
反演特性公式:
含义:输入全取反时,输出也全取反(真值表可验证)。
-
利用该特性移除进位链中的反相器,减少反相级数量,直接降低进位延迟(如 4 位加法器的交替反相 / 非反相单元结构)。
2.2.3 互补静态 CMOS 全加器(28T)
接下来我们用CMOS电路来实现全加器:
-
逻辑公式:
- 进位输出(反相):
- 和输出:
- 进位输出(反相):
-
电路组成:标准静态 CMOS(PMOS 上拉 + NMOS 下拉),共 28 个晶体管。
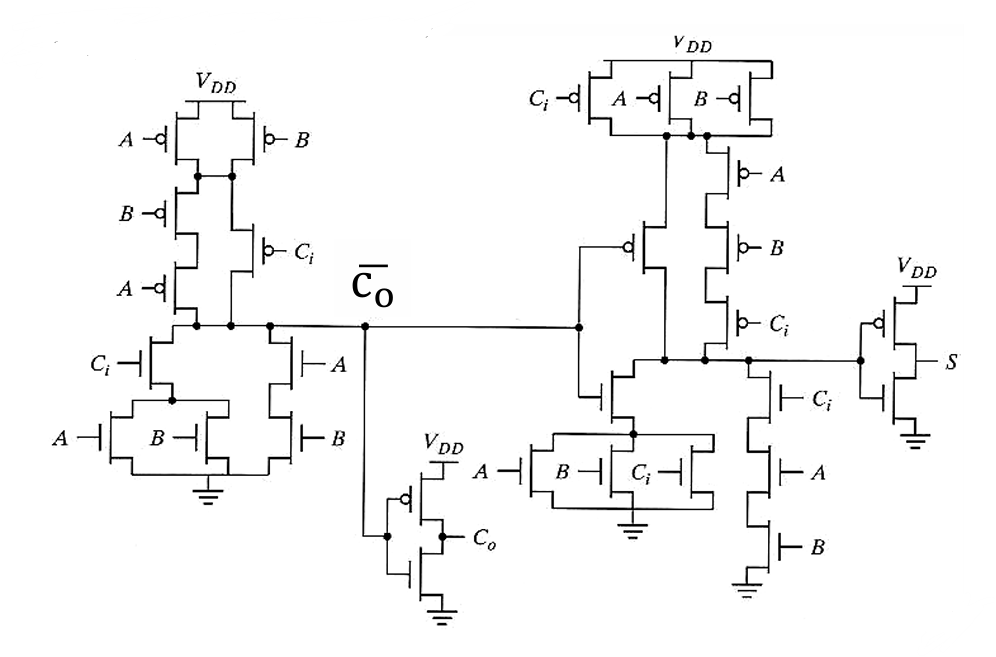
但其具有很明显的缺陷:
| 缺点 | 影响 |
|---|---|
| 晶体管数多(28 个) | 面积大、功耗高 |
| PMOS 堆叠结构 | 延迟大、速度慢 |
| co本征电容大 | 负载大,进位延迟高 |
| 进位经 2 个反相级传播 | 关键路径延迟增加 |
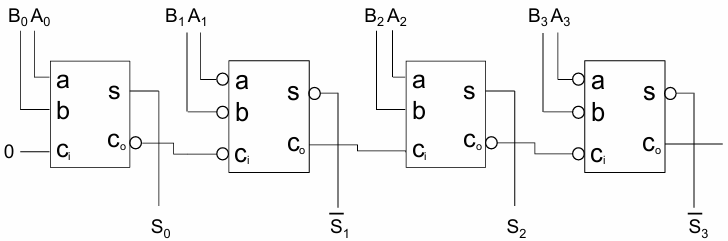
我们可以利用反演特性,交替使用反相/非反相全加器单元,移除进位链中的反相器,减少反相级数量,降低延迟。例如下图所示的四位加法器:
2.2.4 基于传输门的加法器(Transmission–Gate-Based Adder)
引入中间变量
- 和输出:
- 进位输出:
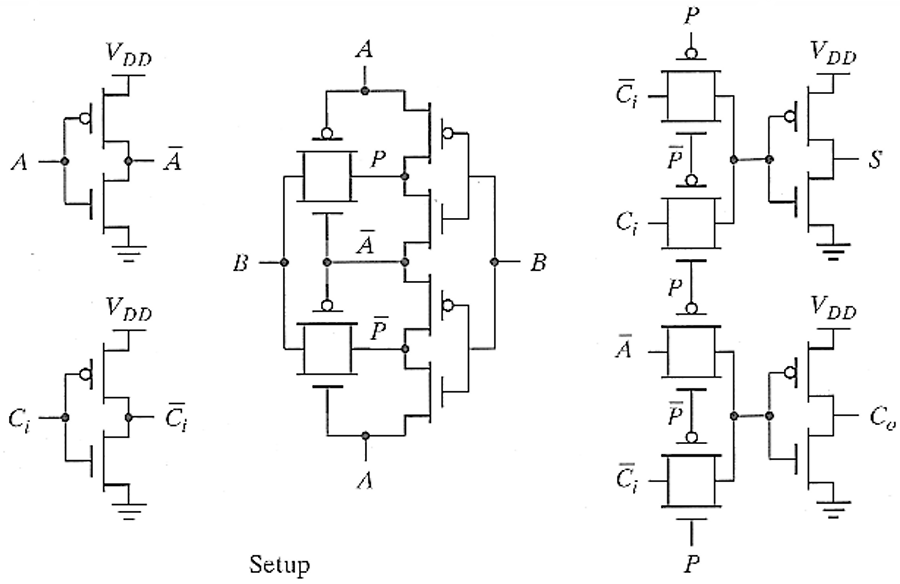
这种方法的优势就是晶体管数大幅减少(约 16T),结构紧凑、速度更快。
2.2.5 曼彻斯特进位门(Manchester Carry Gates)
-
定义三个核心信号:
-
-
-
-
-
进位公式:
进位公式在后面超前进位加法还会进行推导,两者的基本进位公式几乎雷同。
-
电路:分为静态、动态(时钟控制)两种,动态结构适合高速进位链(如超前进位加法器),大幅提升大位宽加法速度。
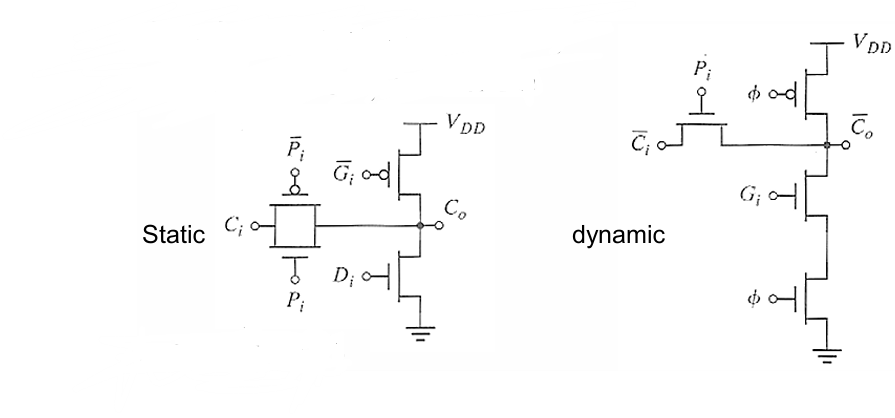
以动态CMOS的方法来实现P/G 信号:
- 预充电(Clk=0):PMOS 管导通,内部节点被预充到 VDD;
- 求值(Clk=1):NMOS 下拉网络根据输入信号决定是否放电,输出反相逻辑;
- Keeper(保持管):弱 PMOS 管,用于补偿下拉路径的漏电,维持输出电平,解决动态逻辑的电荷泄漏、电荷共享问题。
(1)
用两个并联 NMOS 管实现"或逻辑"(简化了异或
(2)
用两个串联 NMOS 管实现"与逻辑",仅当
Example:4 位曼彻斯特进位链(4-bit Manchester Carry Chain)
- 预充电阶段(
- 求值阶段(
- 若
- 若
- 递推公式:
- 若
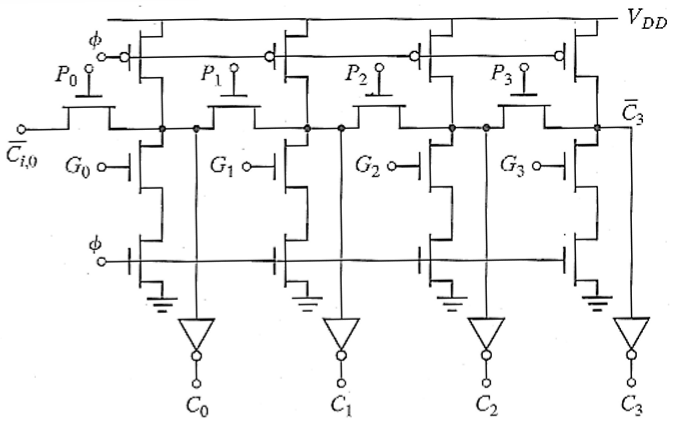
2.2.6 进位旁路加法器(Carry-Bypass Adder)
在行波进位链基础上增加一条旁路通道(Bypass Path)。
原理:
计算一组进位传播信号的块传播信号(Block Propagate, BP)。
(以 4 位块为例,只有当所有位都满足传播条件
- 行为规则
- 若 BP=1:直接将输入进位
- 若 BP=0:按正常行波方式逐级传播进位。
- 若 BP=1:直接将输入进位
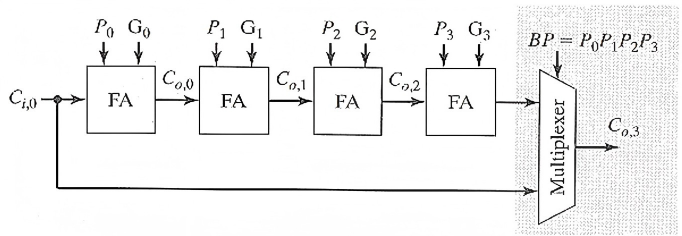
其实单这样没啥用,延迟还是很高而且还多此一举。
我们可以改成曼彻斯特进位旁路加法器,这样就可以减小进位链的延迟:
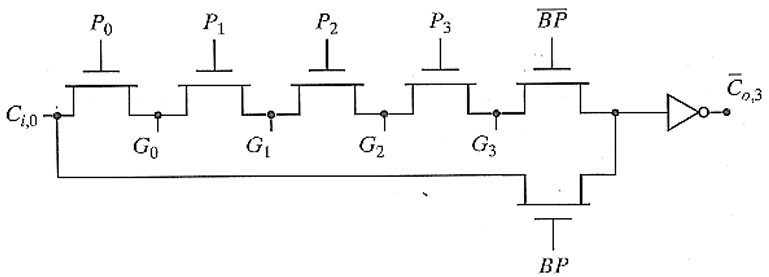
但是如果在一个大的电路里,拆分成几个,就可以加速并行计算,从而提高计算效率。
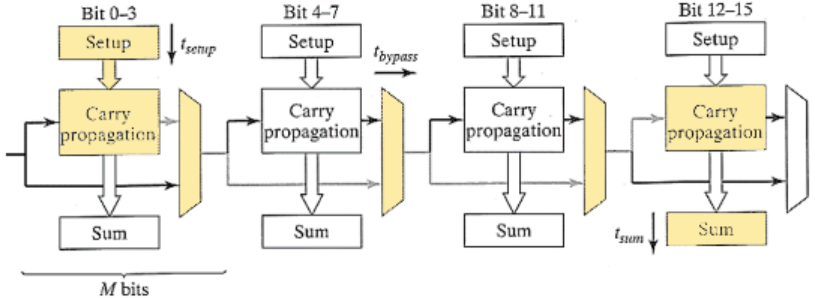
如上图所示,如果有 N-bit 的加法器,可以分为
所以其延迟就是:
其中
-
-
-
-
2.2.7 进位选择加法器(Carry-Select Adder)
它的原理就是利用"预计算"消除等待时间,先利用并行计算,让每个块预先计算两种情况——假设输入进位为 0 和 假设输入进位为 1 时的本组结果。然后当前一级进位
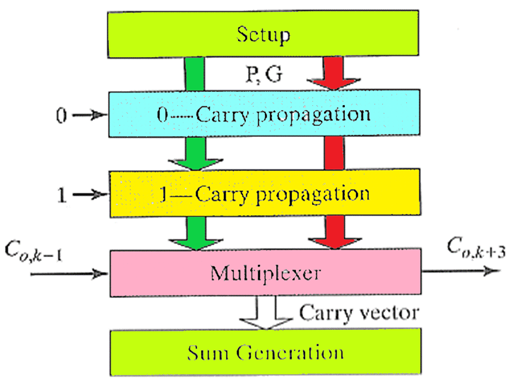
进位选择器常见的有三种改进方案:
(1) 线性进位加法器(Linear Carry-Select Adder)
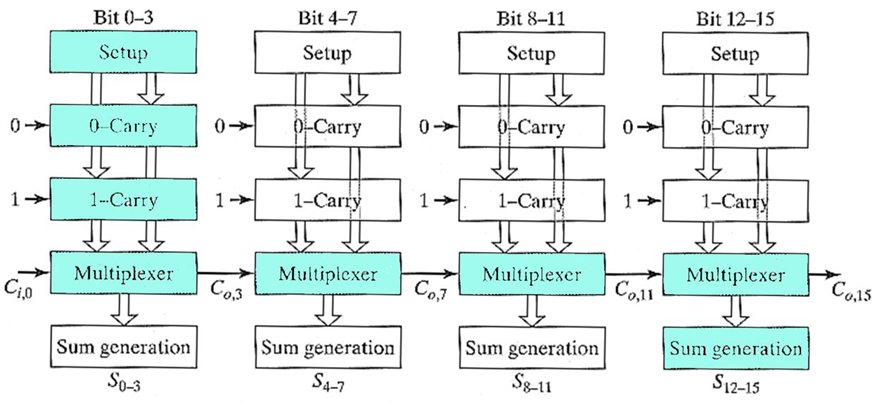
N 位加法器内置 M 位进位选择,划分成
这种电路结构占用面积较小,设计简单。
(2) N 位平方根进位选择加法器(N-bit Square-Root Carry-Select Adder)
线性选择加法器前面的块要等的时间短,后面的块要等的时间长,那既然这样,我们可以让:
- 前面的块更小(算得快,尽快出进位给后面)
- 后面的块更大(等的时间长,不用那么快出,减少总块数)
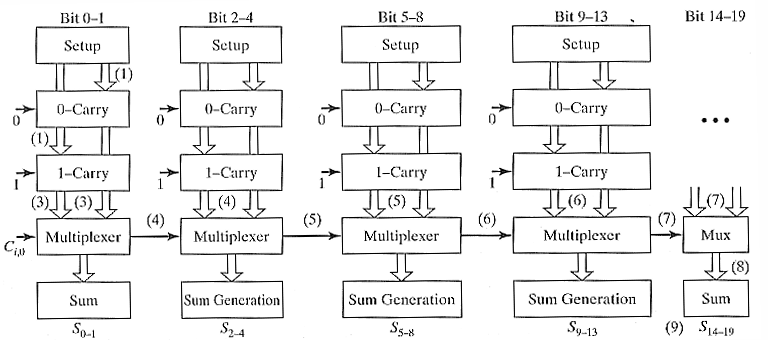
如上图,总位数 N 其实就是一个首项为 2、公差为 1 的等差数列求和:
变形得:
也就是总块数 P 和
由此,就可以得到延迟公式:
2.2.8 超前进位加法器(Carry-Look-Ahead Adder, CLA)
从根本上打破行波进位
数学展开式如下:
- G(Group Generate):
- P(Group Propagate):
- 最终简化:
- 所以最终第
关于进位公式如何推导,可以看B站上的视频:
但这一种方式造成芯片面积巨大,连线复杂(P、G 信号扇出极多),功耗高。
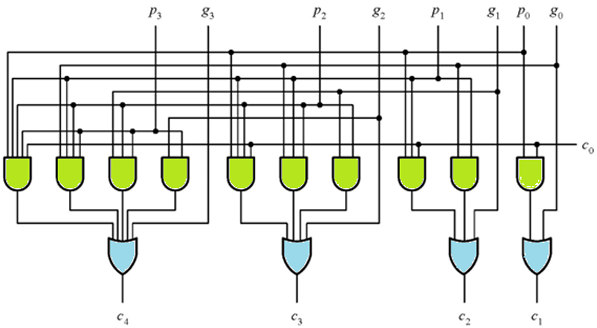
上图是用超前进位加法器实现的全加器的整体架构,所有
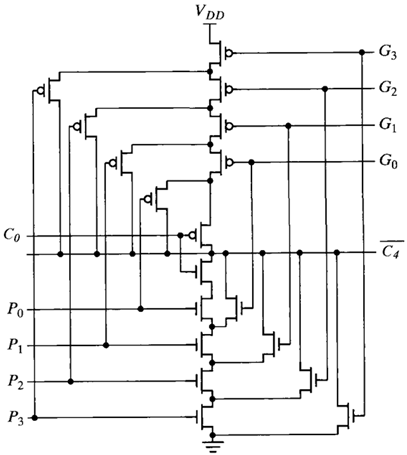
Example: 4-bit Look-ahead Carry Generator
这里给出一种从
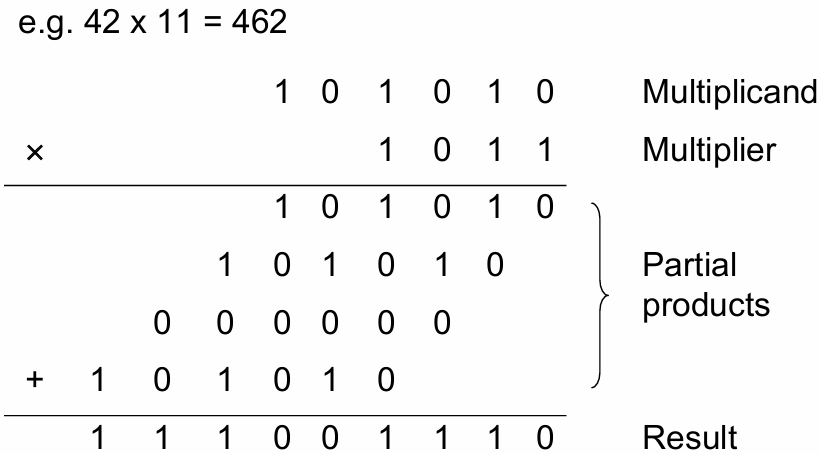
2.3 乘法器
2.3.1 二进制乘法(Binary Multiplication)
设两个无符号二进制数:
- M位被乘数 X:
- N位乘数Y:
乘积
将两个按权展开的数相乘,交换求和顺序:
二进制乘法可拆分为多个部分积(Partial Product)的和:
-
-
如下图所示,这就是二进制乘法的计算过程:
我们可以将
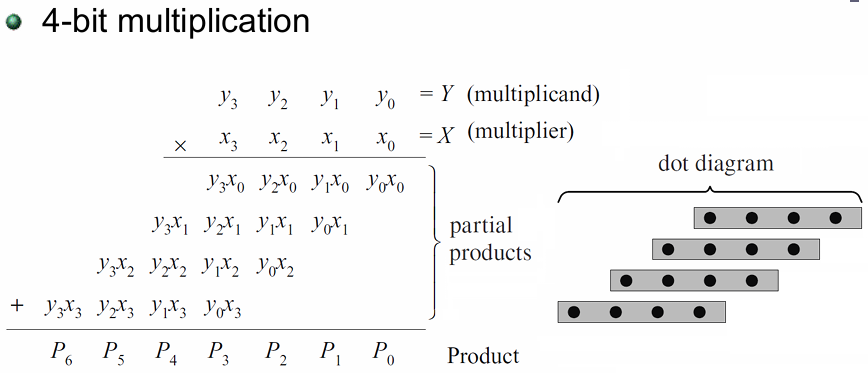
| 乘积位 | 点的数量 | 对应部分积项 |
|---|---|---|
|
|
1 |
|
|
|
2 |
|
|
|
3 |
|
|
|
4 |
|
|
|
3 |
|
|
|
2 |
|
|
|
1 |
|
|
|
1(进位) | 加法产生的最高位进位 |
这是乘法器的输入级电路,展示了部分积的硬件实现原理:
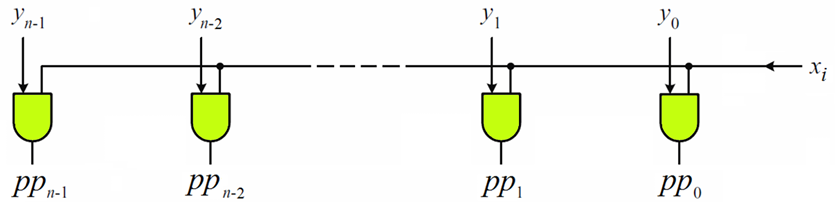
二进制位相乘
- 并行生成:所有部分积可同时生成,延迟仅为 1 个与门的延迟
- 面积开销:M位
2.3.2 位串行乘法器
这是面积最小、但速度最慢的乘法器结构,以时间换面积,是低成本、低功耗场景的极简实现。
要实现
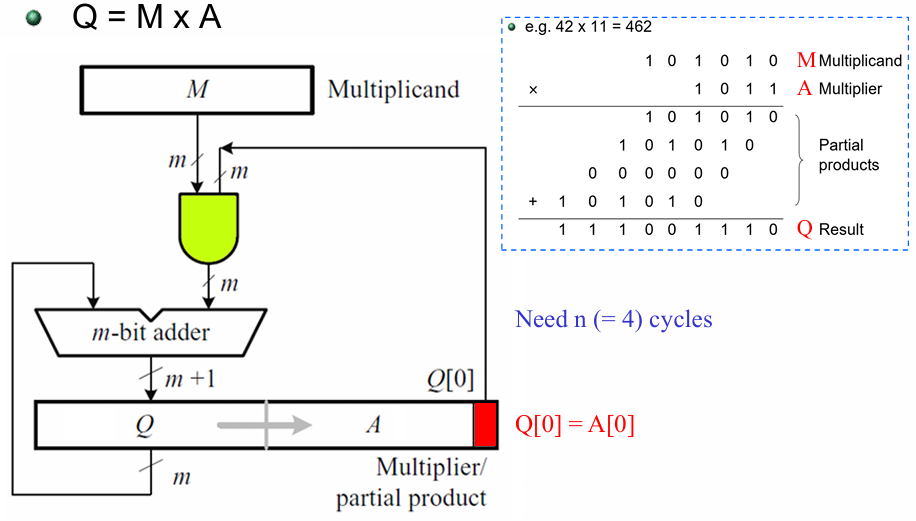
其工作流程如下:
- 初始状态:移位寄存器低
- 单时钟周期动作:
- 取寄存器最低位
- 部分积与寄存器高
- 加法结果整体右移 1 位,最低位作为乘积的 1 位固定输出,进位保留在高位,乘数同步右移 1 位,进入下一个周期。
- 取寄存器最低位
- 总耗时:
2.3.3 阵列乘法器(Array Multiplier)
最基础的全并行乘法器,其先通过与门阵列并行生成所有部分积,再通过全加器组成的二维阵列,逐行累加部分积,直接输出最终乘积。
我们以
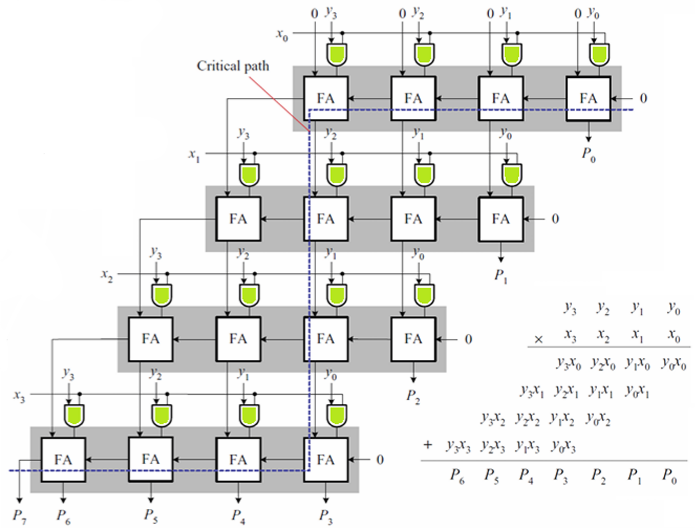
- 部分积生成:
- 加法阵列:共
- 进位规则:每行全加器产生的进位,传递到下一行的同列全加器的进位输入端,逐行完成累加。
所以阵列乘法器的延迟公式:
其中:
-
-
-
这个公式是根据下图推理出的,
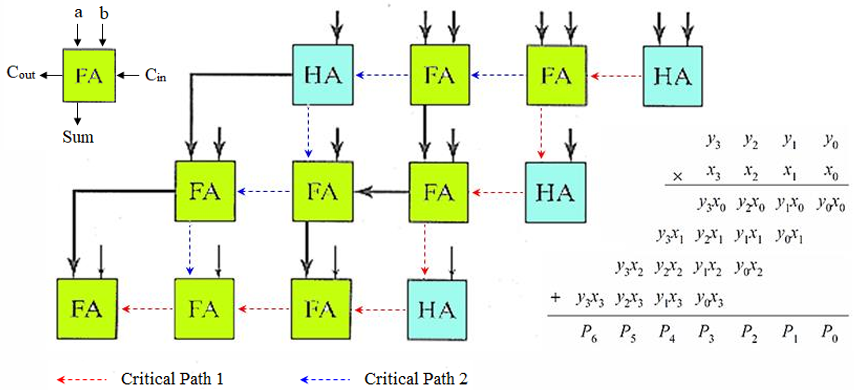
2.3.4 进位保存乘法器(Carry-Save Multiplier)
阵列乘法器的痛点主要有进位逐行跨列传播,路径超长;因此需要一种新的方案。
高速乘法器的核心基础结构,其原理就是先不传播进位,把进位保存下来,到最后一步再统一传播:
- 进位保存的优化:全加器作为3-2 压缩器使用,把 3 个输入(当前位部分积、上一级和、上一级进位)压缩为 2 个输出(本位和、进位);产生的进位不传递到同列下一级,而是传递到下一级的右一列(对应更高 1 位的权值),进位仅在本级内保存,不跨级传播。
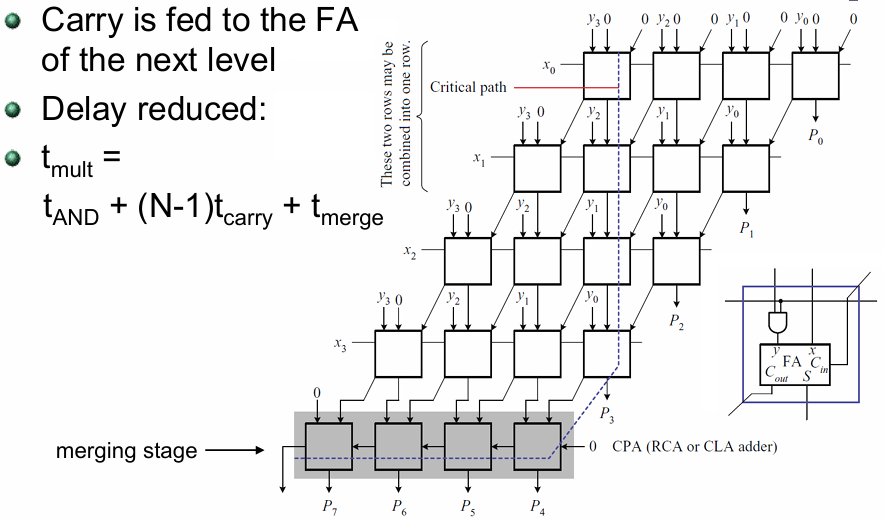
-
与门阵列:并行生成所有部分积;
-
CSA 压缩树:N−2 级进位保存加法器,每一级把部分积的行数减少,最终把 N 行部分积压缩为 2 行:1 行和(Sum)、1 行进位(Carry);
-
合并级(Merging Stage):1 个进位传播加法器(Carry-Propagate Adder, CPA, 如超前进位加法器 CLA),把最后 2 行的和与进位相加,得到最终乘积。
-
延迟公式:
延迟仅与乘数位宽
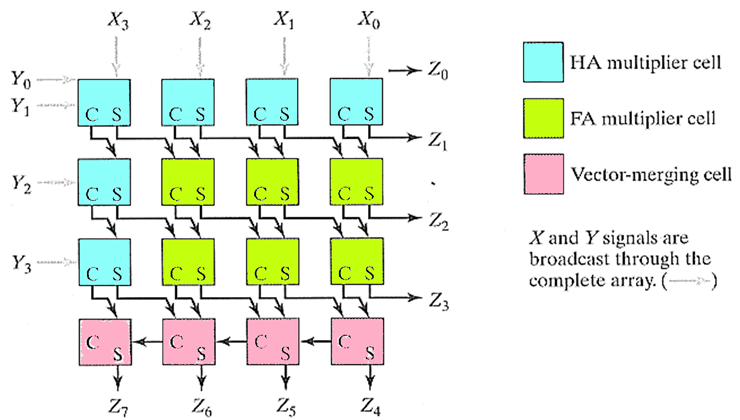
- 浅蓝色 HA 单元:半加器乘法单元,用于仅 2 个输入的列,实现 2-2 压缩;
- 黄色 FA 单元:全加器乘法单元,核心的 3-2 压缩单元,用于 3 个及以上输入的列;
- 粉色 Vector-merging 单元:向量合并单元,即最后一级的 CPA,完成和与进位的最终合并。
2.3.5 华莱士树与Dadda树(Wallace Tree and Dadda Tree)
两种树型结构的核心目标一致:用最少的压缩级数,把多列的部分积压缩到每列仅 2 个点,最终用 CPA 合并得到乘积,仅压缩策略不同。
部分和加法器可以设计成树形,可以减少关键路径和所需的加法器单元数目。根据点图,我们可以将点图重新安排成下图(b)中的树形,由此看出其深度。可以用全加器:三个输入和两个输出,一个输出和到当前列,一个输出进位到下一列;半加器:两个输入和两个输出。
| 结构 | 压缩策略 | 实现细节 |
|---|---|---|
| Wallace Tree(华莱士树) | 尽可能早压缩:每一级只要列中点数≥3,就用 FA 压缩,最大化减少每一级的点数 | 2 级压缩,Stage1 用 3 个 FA+1 个 HA,Stage2 用 2 个 FA+2 个 HA,最终用 4 位 CPA 合并 |
| Dadda Tree(Dadda 树) | 尽可能晚压缩:仅压缩到满足下一级的最大允许点数,不做多余压缩 | 2 级压缩,Stage1 用 2 个 FA,Stage2 用 2 个 FA+2 个 HA,最终用 6 位 CPA 合并 |
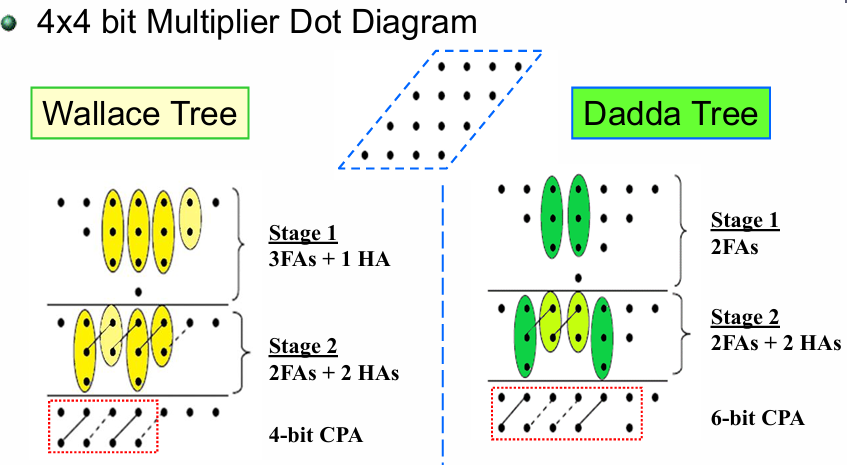
关于华莱士树,可以看如下视频:
而Dadda树则可以复习以下视频:
| 对比维度 | Wallace Tree(华莱士树) | Dadda Tree(达达树) |
|---|---|---|
| Strategy for adding PP(部分积压缩策略) | As soon as possible(尽早压缩) | As late as possible(尽晚压缩) |
| CSA Tree(CSA 树结构) | More complex(更复杂) | Simpler(更简单) |
| CPA(最终进位传播加法器) | Shorter(位宽更短) | Longer(位宽更长) |
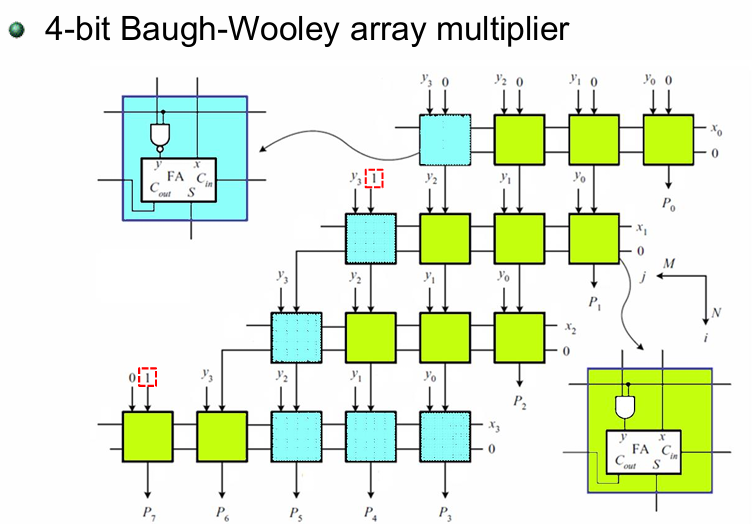
2.3.6 有符号乘法器(Signed Multiplication)
对于正数,补码与其原码相同。对于负数,补码是其反码加1。反码是将原码的数值部分逐位取反(0变1,1变0)。
以十进制数 -5 为例:
-
原码表示:10000101(最高位为符号位,1表示负数)。
-
反码表示:11111010(将原码除符号位外的所有位取反)。
-
补码表示:11111011(反码加1)。
为了消除负号,使用补码的基本恒等式:
其中

Example: 4 位 Baugh-Wooley 阵列乘法器
3. 数据通路的功耗考量(Power Considerations in Datapath)
CMOS 动态功耗公式如下:
我们列个表对各项参数进行解释:
| 参数 | 含义 | 通俗比喻 | 对功耗的影响 |
|---|---|---|---|
|
|
动态功耗(CMOS 最主要功耗来源,由节点电容充放电产生) | 水管的 “水耗” | 核心优化目标 |
|
|
工作频率(时钟每秒翻转次数) | 水管开关频率 | 线性相关:频率越高,功耗越高 |
|
|
负载电容(节点总电容,含栅电容、线电容) | 水管容积 | 线性相关:电容越大,功耗越高 |
|
|
电源电压 | 水压 | 平方相关:降VDD是最有效的降功耗手段 |
|
|
开关活动性(节点翻转概率,Σα为总翻转率) | 水管通水比例 | 线性相关:翻转越多,功耗越高 |
通过上述公式不难看出:
要降低功耗,但同时也需要补偿降VDD带来的性能损失(在保性能的前提下降功耗),普遍的方法有:
-
并行架构(Parallel Functional Blocks)
利用用多个并行模块,每个跑更低频率 + 更低
-
流水线架构(Pipeline Structure)
将大组合逻辑拆分为多级流水线,每级负载电容更小,因此可用更低的
-
多电源电压(Multiple Supply Voltages, MSV)
关键路径(需高速)用高
- 注意:需电平转换电路(Level Shifter)实现不同电压域的信号交互。
-
动态电压频率调节(Dynamic Voltage and Frequency Scaling, DVFS)
根据系统负载动态调整频率和电压:负载低(如手机 idle)时降频降压,负载高(如玩游戏)时升频升压。
-
掉电模式(Power-down Mode)
将空闲模块设为待机(Standby),切断 / 降低供电,消除静态 + 动态功耗。
3.1 时钟门控(Clock Gating)
时钟树是芯片中功耗最高的部分(时钟持续翻转、负载极大),时钟门控的原理是:切断空闲模块的时钟,让触发器停止翻转,消除动态功耗(
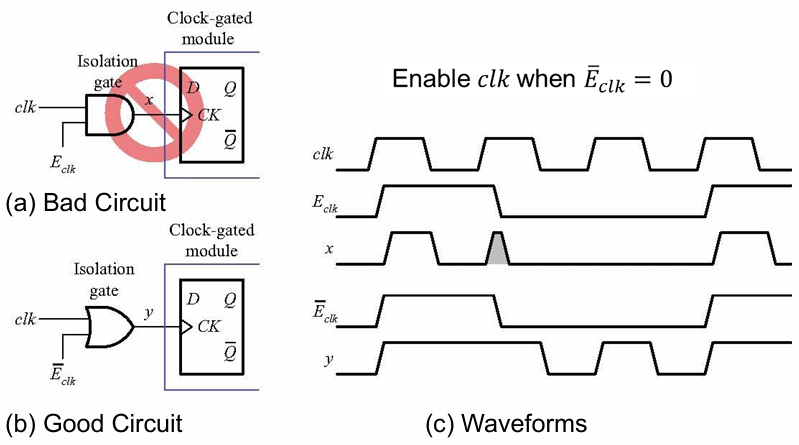
| 电路 | 方案 | 问题 / 优势 | 波形表现 |
|---|---|---|---|
| Bad Circuit | 与门(AND)做隔离门,输入
|
错误方案:
|
|
| Good Circuit | 或门(OR)做隔离门,输入
|
正确方案:
|
|
3.2 电源门控(Power Gating)
电源门控是为了彻底消除静态功耗(时钟门控仅消动态功耗,电源门控关电源,漏电流几乎为 0)。在空闲模块的电源轨串联电源开关(大尺寸 PMOS),空闲时切断电源,消除静态漏电流和动态功耗;工作时恢复供电。
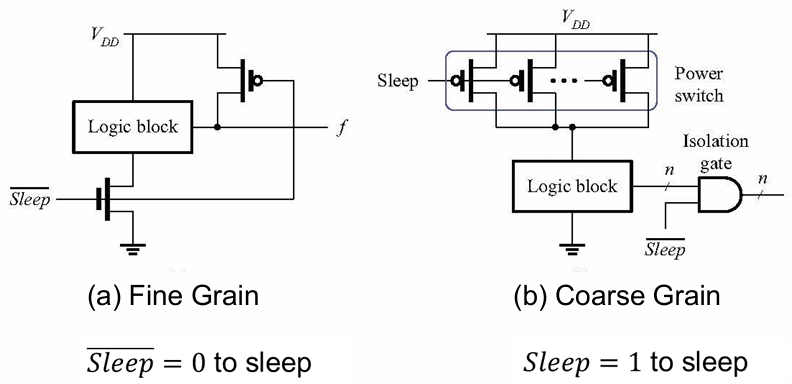
| 特性 | 细粒度(Fine Grain) | 粗粒度(Coarse Grain) |
|---|---|---|
| 控制粒度 | 每个逻辑门 / 小模块加睡眠管 | 整个大功能模块(如 CPU 核)用一个电源开关 |
| 面积开销 | 大(逐门加管) | 小(仅模块级加开关) |
| 时序影响 | 大(每个门串联电阻,延迟增加) | 小(仅模块级影响,可优化补偿) |
| 设计复杂度 | 高(逐门设计,时序收敛难) | 低(模块级设计,时序收敛易) |
| 适用场景 | 小模块、对面积不敏感的场景 | 大模块、现代芯片主流方案(如手机 SoC) |
4 设计方法
4.1 设计抽象层级
通过分层抽象降低设计复杂度,从底层器件到顶层系统的层级如下:
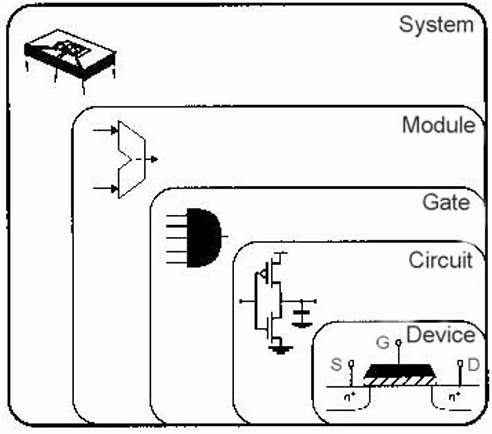
| 层级 | 核心定位 | 设计对象 |
|---|---|---|
| Device(器件) | 物理底层 | MOS 晶体管(G/S/D 极、n 阱结构) |
| Circuit(电路) | 单元电路 | 反相器、与非门等 CMOS 基本电路 |
| Gate(门级) | 逻辑单元 | 与门、或门、触发器等标准逻辑门 |
| Module(模块) | 功能模块 | ALU、寄存器、多路选择器等子系统 |
| System(系统) | 完整芯片 | CPU、SoC、存储器控制器等整机系统 |
如下所示是 Gajski-Kuhn Y 图(Gajski-Kuhn Y Diagram):
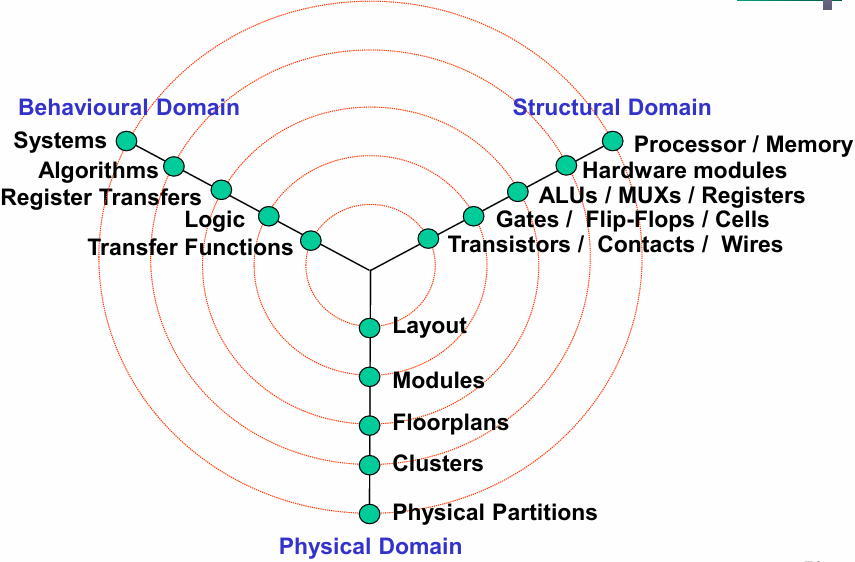
IC 设计的经典三维模型,将设计划分为三个核心域,每个域对应不同抽象层级:
- 行为域(Behavioural Domain):描述"做什么"(功能、算法、时序),从系统级到电路级的功能定义。
- 结构域(Structural Domain):描述"用什么做"(硬件结构、模块连接),从处理器 / 存储器到晶体管的硬件实现。
- 物理域(Physical Domain):描述"物理实现"(版图、布局、布线),从版图到物理分区的物理落地。
4.2 设计流程
我们用完整的流程图来看看 IC 设计流程:
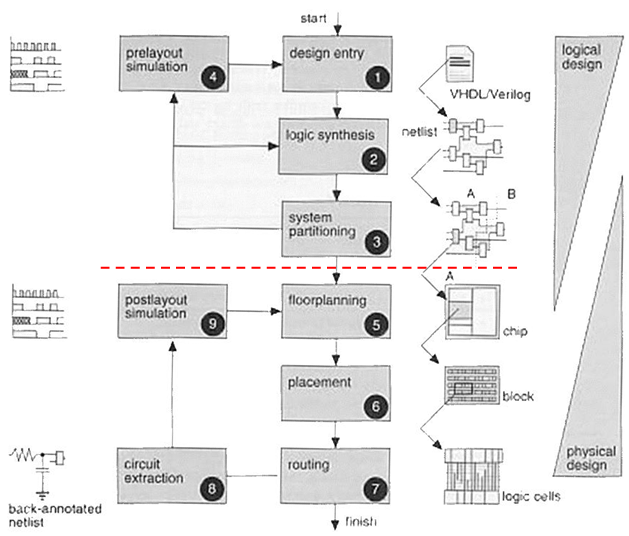
分为 前端(逻辑设计,prelayout)和后端(物理设计,postlayout) 两大阶段:
-
前端流程(逻辑设计,红线以上)
- Design Entry(设计输入):用 Verilog/VHDL 编写 RTL 代码,或原理图 / 状态图输入
- Logic Synthesis(逻辑综合):将 RTL 代码综合为门级网表,映射到标准单元库
- System Partitioning(系统划分):模块划分、布局规划
- Prelayout Simulation(布局前仿真):功能仿真(前仿真),仅验证逻辑正确性,不考虑时序 / 寄生
-
后端流程(物理设计,红线以下)
- Floorplanning(平面规划):芯片电源、IO、模块布局,确定芯片面积
- Placement(布局):标准单元 placement,优化时序、面积
- Routing(布线):单元间连线,完成物理实现
- Circuit Extraction(电路提取):提取版图寄生参数(RC),生成后标注网表
- Postlayout Simulation(布局后仿真):时序仿真(后仿真),验证带寄生参数的时序或功能,确保满足约束
最终进行流片(Tapeout),进入芯片制造环节。
4.3 EDA 工具
| 类别 | 核心定位 | 覆盖环节 |
|---|---|---|
| Design Entry(设计输入) | 设计的起点,将需求转化为可处理的设计文件 | 原理图编辑、HDL 代码编写、层次化设计 |
| Analysis and Verification(分析与验证) | 验证设计的功能、时序、可靠性 | 全层级仿真、静态时序分析、形式验证等 |
| Synthesis and Implementation(综合与实现) | 从逻辑到物理的落地 | 逻辑综合、布局布线、版图生成 |
| Testing(测试) | 芯片制造后的测试与良率保障 | 可测试性设计(DFT)、自动测试向量生成(ATPG) |
4.3.1 设计输入工具(Design Entry Tool)
- Schematic Editor(原理图编辑器)
- 核心组件:Cell Library(单元库),包含可复用的逻辑门、模块等组件
- 核心功能:放置、移动、删除、连接、旋转 / 翻转、复制 / 粘贴等编辑操作
- 层次化设计:模块可嵌套底层原理图,支持大规模设计的分层管理
- 网表格式:EDIF(Electronic Design Interchange Format),用于不同工具间的网表交互
4.3.2 仿真类型
| 类型 | 抽象层级 | 核心特点 | 适用场景 |
|---|---|---|---|
| Circuit Simulation(电路仿真/晶体管级仿真) | 晶体管级 | 基于晶体管非线性模型,精度最高,仿真耗时最长,输出连续电压 / 电流波形 | 模拟电路、关键路径、小模块验证,不适合大规模数字电路 |
| Timing Simulation(时序仿真) | 晶体管级(简化模型) | 用简化晶体管模型,降低复杂度、提升仿真速度,牺牲部分精度 | 数字电路时序验证,平衡精度与效率 |
| Switch Level Simulation(开关级仿真) | 开关级 | 将晶体管建模为开关 + 线性电阻,关断时电阻无穷大,导通时用平均导通电阻,电路等效为时变线性 RC 网络 | 数字电路仿真,精度与效率介于晶体管级与门级之间 |
| Gate Level Simulation(门级仿真) | 门级 | 以逻辑门为基本单元,仿真速度快,仅验证逻辑与时序 | 综合后网表验证,大规模数字电路 |
| Static Timing Analysis(静态时序分析,STA) | 门级/网表级 | 无需输入激励,静态分析电路时序,验证建立 / 保持时间,速度极快 | 数字 IC 时序验证的核心手段,流片前必做 |
| Functional Simulation(功能仿真) | RTL/门级 | 仅验证逻辑功能,不考虑时序,仿真速度快 | 前端设计阶段,快速定位逻辑错误 |
| Behavioural Simulation(行为级仿真) | 行为级/算法级 | 基于算法 / 行为描述,不涉及具体硬件,仿真速度最快 | 系统级架构验证、算法验证,设计早期阶段 |
4.3.2.1 静态时序分析(Static Timing Analysis)
STA 是一种验证芯片时序性能的方法,它会检查所有可能的信号路径,确保芯片能在指定频率下稳定工作。
- 三种关键路径延迟:
-
Entry Delay (输入延迟)
- 定义: 指信号路径从芯片的外部输入端口开始,到芯片内部某个 时序逻辑单元(如 D 触发器)的数据输入端(如 D 输入) 结束。
- 作用: 衡量外部信号到达内部触发器所需的时间。
-
Stage Delay (级间延迟)
- 定义: 指信号路径从一个时序逻辑单元的时钟输入端开始,到另一个时序逻辑单元的数据输入端结束。这通常是时序分析中最关键的路径,因为它决定了整个芯片的最高工作频率。
- 构成: 这条路径包括源触发器的时钟到输出(Clock-to-Q)延迟、中间所有组合逻辑的延迟以及互连线的延迟。
-
Exit Delay (输出延迟)
-
定义: 指信号路径从芯片内部某个时序逻辑单元的输出端开始,到芯片的外部输出端口结束。
-
作用: 衡量内部信号到达芯片外部所需的时间。
-
-
4.3.2.2 功能仿真(Functional Simulation)
功能仿真是逻辑仿真的一种扩展和应用。
- 关键特点:
- 复杂度:仿真的电路可以包含任何复杂程度的元件,从简单的与门到复杂的乘法器、RAM 等。
- 电路中每个元件的功能都是通过硬件描述语言(如 VHDL 或 Verilog)来描述的。
- 仿真的输出是代表逻辑电平(0 或 1)的信号。
- 延迟模型复杂度:为了加快仿真速度,功能仿真通常采用零延迟模型。这意味着它忽略了所有门延迟和线延迟,假设信号是瞬时传播的。
4.3.2.3 行为级仿真(Behavioural Simulation)
行为级仿真是一种更高抽象层次的仿真。
-
功能描述(Functional): 代表了预期的硬件结构,即描述了哪些模块是如何连接在一起的。它更接近实际的电路实现。
-
行为描述(Behavioural): 只描述了电路的输入-输出功能,而不关心其内部是如何实现的。它更像是一个算法或功能的描述。
-
行为级仿真的特点::
- 行为级仿真通常忽略具体的门级时序,而是以时钟周期为单位来描述操作。
- VHDL 和 Verilog 都支持行为级描述。
- 行为级仿真的输出不仅可以是逻辑值,还可以是数值(如整数、浮点数),这使得它非常适合算法验证。
4.4 延迟模型(Delay Models)
延迟是信号从一个点传播到另一个点所需的时间,是决定芯片速度的关键因素。延迟模型是用来描述和量化逻辑单元(如一个与非门、一个触发器)内部信号传播延迟的数学模型。
- 三种核心延迟类型:
- Pin-to-pin delay (引脚到引脚延迟)
- 定义: 指信号从一个逻辑单元的输入引脚到其输出引脚的总传播延迟。
- 特点: 这个模型将整个逻辑单元视为一个 “黑盒子”,不关心其内部结构,只关注整体的输入输出延迟。它不包含单元之间互连线的延迟。
- Pin delay (引脚延迟)
- 定义: 指将延迟归属于某个特定的输入引脚。可以理解为信号从输入引脚进入单元内部,到单元内部第一个逻辑节点的延迟。
- 特点: 这是一种更精细的建模方式,允许时序分析工具更灵活地计算路径延迟。
- Net delay (Wire delay) (互连线延迟)
- 定义: 指信号在连接不同逻辑单元的 互连线(Net) 上传播所产生的延迟。
- 特点: 随着芯片制造工艺越来越先进,线宽变窄,线延迟在总延迟中所占的比重越来越大,甚至可能超过逻辑门本身的延迟。因此,精确计算线延迟对于现代芯片设计至关重要。
- Pin-to-pin delay (引脚到引脚延迟)
5 设计验证(Design Verification)
仿真结果并不能保证设计的正确性和功能性,仿真仅说明设计在给定的一组输入激励下如何反应。设计验证用于检测电路中的设计错误。主要有三种类型的设计验证:
-
电气验证(Electrical Verification)
针对晶体管级电路的电气特性检查,核心规则如下:
- CMOS 电路反相数规则:两个
- 伪 NMOS 管尺寸规则:伪 NMOS 门中,PMOS 上拉管与 NMOS 下拉管的尺寸必须满足特定比例,以保证良好的低电平噪声容限(NML)。
- 驱动管尺寸规则:根据扇出(fanout)设置驱动管的最小尺寸,确保电路的上升 / 下降时间满足设计要求。
- CMOS 电路反相数规则:两个
-
时序验证(Timing Verification)
针对电路时序路径的延迟分析,核心要点:
-
关键路径识别难点:复杂电路中难以手动定位关键延迟路径,需依赖时序验证工具。
-
工具核心能力:遍历电路网络,计算所有路径的延迟,识别关键路径。
-
伪路径(False Path)检测:智能工具可识别实际不会发生的路径(如示例中与门输出恒为 1,对应路径无实际延迟),避免误判关键路径。
例如,输入
-
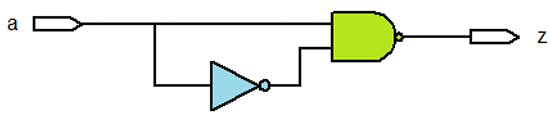
-
形式验证(Formal Verification)
基于数学方法的等价性验证,核心特点:
从数学上证明电路的两种表示(如 RTL 代码与综合后门级网表)功能等价。在形式验证中,组件在行为上被描述为其输入和内部状态的函数。式验证器将派生电路与其初始规格进行比较这两个电路不需要相同但等效,它不依赖仿真激励,可 100% 验证功能等价性,报告所有不一致点。
6 芯片实现方案分类(Implementation Approaches)
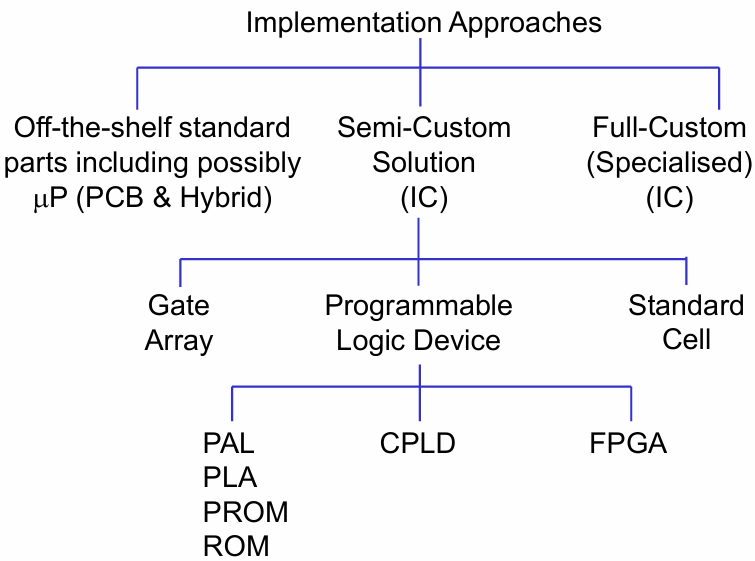
我们主要对半定制 IC 展开解释。
6.1 标准单元(Standard Cell)
| 要点 | 详细说明 |
|---|---|
| 设计基础 | 使用预设计的标准单元库,库中单元包含逻辑门、功能模块(如加法器),且已完成版图设计与特性表征(delay/power)。 |
| 设计要求 | 仅需完成功能与逻辑设计,无需关注晶体管级细节。 |
| 实现方式 | 依赖 EDA 工具进行自动布局布线(Automatic placement & routing)。 |
| 优劣势 | ✅ 设计周期短、成本低;❌ 硅片利用率低(面积效率差),面积开销大。 |
自动版图生成技术(Compiled Cells & Module Generators)
-
单元编译器(Cell Compiler)
- 输入:门级原理图与晶体管尺寸。
- 输出:自动生成版图,将抽象的逻辑结构转换为物理版图。
-
模块生成器(Module Generators)
- 功能:自动创建复杂功能模块(加法器、乘法器、寄存器、存储器)。
- 特性:通常支持参数化(Parameterizable),可生成不同位宽的模块(如 8 位 / 16 位加法器)。
6.2 门阵列(Gate Array)
掩模可编程门阵列 (MPGA) 原始单元或晶体管由供应商制造逻辑门可以通过一层或多层连接层(掩模)从单元或晶体管配置设计时间与标准单元相同,因为使用了 EDA 工具制造时间比标准电池方法更短
6.3 可编程逻辑器件(Programmable Logic Devices)
PLD 是基于**与-或阵列(AND-OR Array)**结构的可编程逻辑器件,分类取决于与阵列/或阵列是否可编程。
PLD主要有如下三种类型
| 器件类型 | 与阵列 (AND Array) | 或阵列 (OR Array) | 核心特点 | 逻辑实现能力 |
|---|---|---|---|---|
| PROM | Fixed (固定) | Programmable (可编程) | 提供所有最小项(minterms),结构最简单。 | 实现任意组合逻辑,但面积开销大。 |
| PAL | Programmable | Fixed | 与阵列可编程,或阵列固定。任意乘积项可生成,但乘积项数量受限于或阵列。 | 灵活性高,是早期主流可编程器件。 |
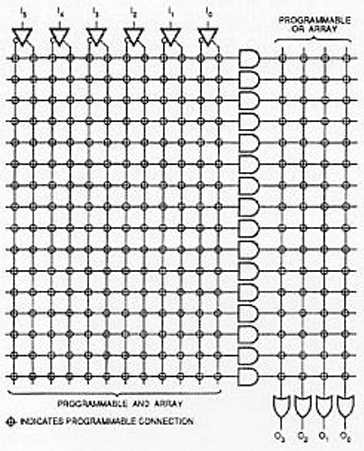
| PLA | Programmable | Programmable | 与、或阵列均可编程。任意乘积项可生成,且乘积项数量不固定。 | 通用性最强,可实现复杂逻辑,面积效率最高。 |
-
PROM:与阵列固定(译码器),产生所有最小项,或阵列可编程(存储数据)。
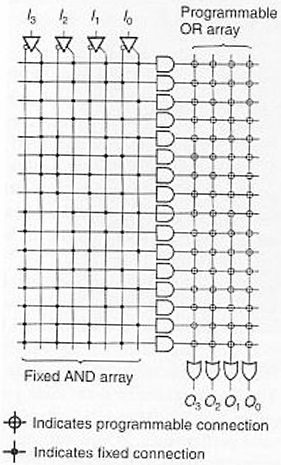
-
PAL:与阵列可编程(产生乘积项),或阵列固定(固定输出宽度)。
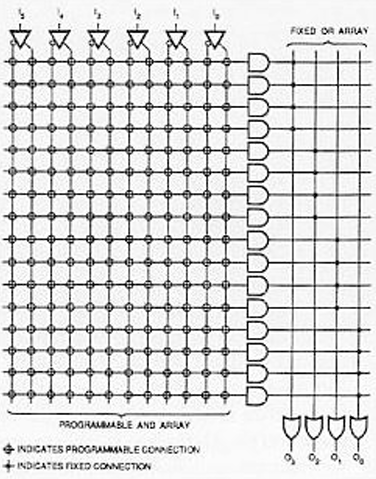
-
PLA:与阵列可编程,或阵列可编程(灵活组合乘积项与输出)。
6.4 现场可编程门阵列(Field Programmable Gate Array, FPGA)
无需定制掩模,混合可编程或基于 RAM 的逻辑单元。
-
核心结构
- 核心(Core):由大量可编程逻辑单元组成,每个单元包含组合逻辑与触发器(sequential logic)。
- 可编程互连(Interconnects):围绕逻辑单元的可编程连线资源。
- 可编程 I/O:芯片周边的 I/O 单元。
6.5 性能指标
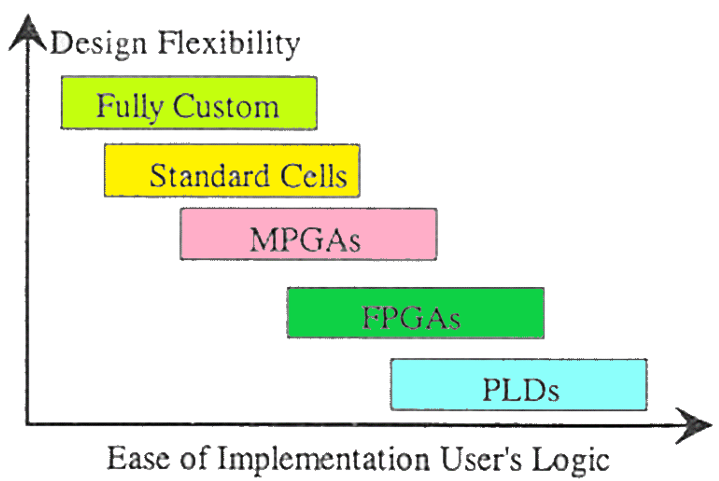
6.5.1 各项维度对比
| 特性 | FPGA / CPLD | Gate Arrays | Standard Cells | Full Custom |
|---|---|---|---|---|
| Design Time | 短 (Short) | 短 (Short) | 短 (Short) | 长 (Long) |
| Fabrication | - (现场编程) | 短 (Short) | 长 (Long) | 长 (Long) |
| Chip Area | 非常大 (Very Large) | 大 (Large) | 中 (Intermediate) | 小 (Small) |
| Cost | 非常低 (Very Low) | 低 (Low) | 中 (Intermediate) | 高 (High) |
| Versatility | 非常低 (Very Low) | 低 (Low) | 中 (Intermediate) | 高 (High) |
| Design Cycle | 极短 (Very Short) | 短 (Short) | 中 (Intermediate) | 长 (Long) |
6.5.2 设计灵活性
7 设计综合(Design Synthesis)
设计综合是将一种抽象层级的设计视图转换为另一种更接近物理实现的设计视图的过程。
典型转换:通常是从行为级描述(Behavioural Specification,如算法 / RTL)转换为结构化描述(Structural Description,如门级网表 / 晶体管网络)。
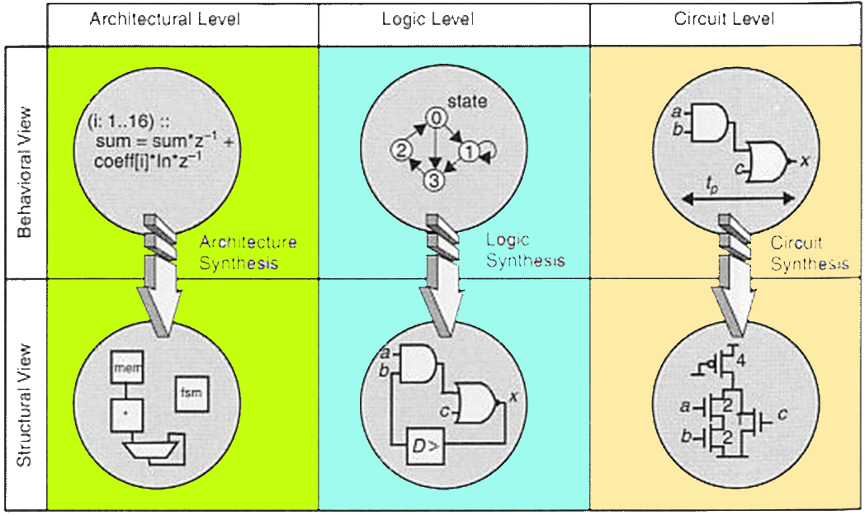
| 综合类型 | 层级 | 输入 | 输出 | 核心目标 |
|---|---|---|---|---|
| Circuit Synthesis | 电路级(Circuit Level) | 逻辑描述 / 逻辑方程 | 晶体管级网表(Transistor Network) | 满足时序约束,优化电气性能 |
| Logic Synthesis | 逻辑级(Logic Level) | 行为级 / 逻辑级规范(布尔方程 / HDL) | 门级网表(Gate-level Netlist) | 优化面积、速度、功耗 |
| Architectural Synthesis | 架构级(Architectural Level) | 系统级算法 / 行为规范 | 系统架构结构(如状态机、数据通路) | 系统架构设计,资源分配与调度 |
7.1 电路综合(Circuit Synthesis)
将逻辑描述转换为晶体管网络,但要满足时序约束(Timing Constraints)。
分为两大阶段:
- 推导晶体管网表(Derivation of Transistor Netlist)
- 选择电路风格:从 CMOS 静态、传输管、动态、DCVSL 等中选择合适的电路结构。
- 构建逻辑网络:根据逻辑方程,利用德摩根定律将反相操作推至输入端,搭建 NMOS/PMOS 网络。
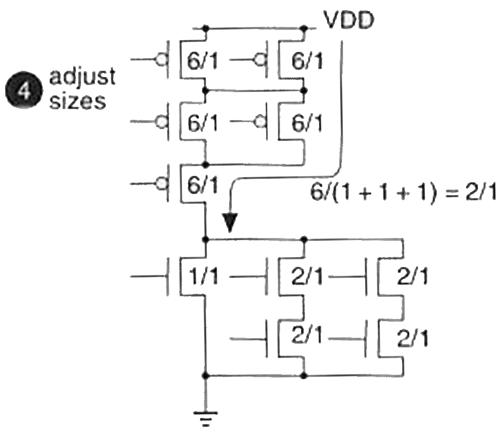
- 晶体管尺寸确定(Transistor Sizing)
- 目标:调整晶体管宽长比(
- 核心规则:使 NMOS 与 PMOS 增益因子相等(
- 晶体管尺寸计算规则:
- 目标:调整晶体管宽长比(
| 连接方式 | 等效电导 / 电阻公式 | 物理意义 |
|---|---|---|
| 并联(Parallel) |
|
导通电阻减小,驱动能力增强 |
| 串联(Series) |
|
导通电阻增大,驱动能力减弱 |
Example:
算出一个比例为 2/1 的逻辑门的晶体管尺寸:
7.2 逻辑综合(Logic Synthesis)
逻辑综合是将逻辑功能转换为门级电路结构的过程。
- 输入规范:状态转移图、原理图、布尔方程、真值表或 HDL 代码。
- 输出结果:门级网表(Multilevel Logic, PLA, FPGA/CPLD 结构)。
优化的核心目标是在面积(Area)、速度(Speed)、功耗(Power)三者之间进行权衡(Trade-off)。
| 阶段 | 名称 | 特点 | 技术手段 |
|---|---|---|---|
| 1 | Logic Minimization (逻辑最小化) | 工艺无关 (Technology-independent) | 利用布尔代数、卡诺图等方法,最小化逻辑门数量,化简逻辑表达式。 |
| 2 | Technology Mapping (工艺映射) | 工艺相关 (Technology-dependent) | 将优化后的逻辑函数,映射到具体的工艺库单元(如标准单元、PLA、FPGA)。 |
7.2.1 组合逻辑综合(Combinational Logic Synthesis)
7.2.2 时序逻辑综合(Sequential Logic Synthesis)
时序逻辑综合不仅处理组合逻辑,还需处理状态(State)与存储元件(触发器)。
| 任务 | 定义 | 作用与考点 |
|---|---|---|
| State Minimization(状态最小化) | 合并功能等价的状态。 | 减少状态数,从而减少触发器数量和逻辑门数量,降低面积。(判据:对于任何输入,输出序列和下一状态都相同) |
| State Encoding(状态编码) | 给状态分配二进制代码。 | 直接影响组合逻辑的复杂度。(例子:格雷码编码可能比二进制编码生成更简单的逻辑) |
| State Decomposition(状态分解) | 将大状态机拆分为多个小状态机。 | 简化逻辑设计,降低单级逻辑的深度,提高系统速度。 |
| Retiming(寄存器重定时) | 移动寄存器(触发器)的位置,不改变输入输出功能。 | 调整流水线深度,优化 关键路径(Critical Path) 延迟,平衡系统吞吐率。 |
7.2.2.1 寄存器重定时(Retiming)
重定时就是在不改变电路输入输出行为的前提下,将寄存器从一个位置移动到另一个位置,其利用组合逻辑的延迟信息,通过移动寄存器来均衡各路径延迟。
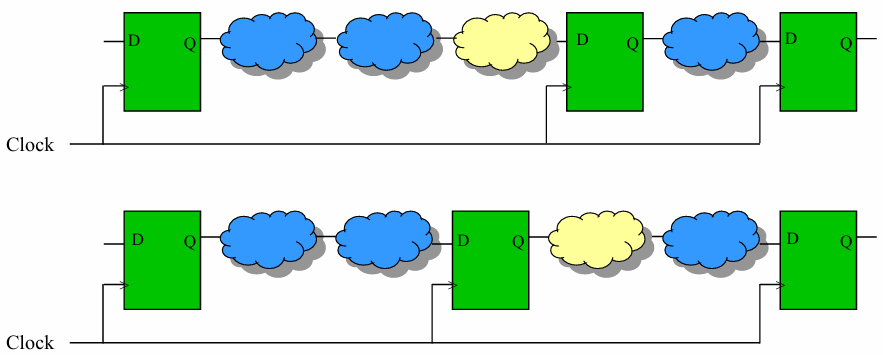
接下来看一个例子:
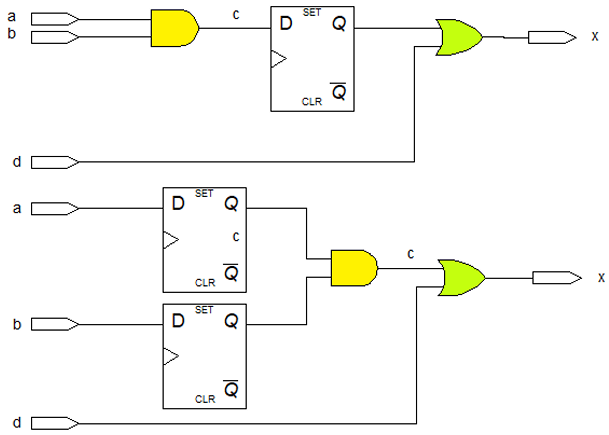
就是把 AND 门从 FF 前面移到 FF 后面,给
最终得到路径:
核心变化:
- 一条路径延迟降低:
- 另一条路径延迟增加:
- 核心权衡:重定时是全局时序平衡,不是 “所有路径都变快”,而是把长路径的延迟分摊到短路径上,让所有路径的最大延迟最小化,从而提升整体时钟频率。
7.3 架构综合(Architecture Synthesis / High-Level Synthesis)
架构综合(HLS)是设计流程的最早期阶段,从算法行为级直接生成硬件结构。将行为级描述(算法、C 代码、DFG)转换为结构化视图(RTL 级代码、硬件架构)。
| 任务 | 解释 | 通俗比喻 |
|---|---|---|
| Operation Scheduling(操作调度) | 将数据流图(DFG)中的操作分配到特定的时钟周期(Control Steps)。 | 决定 “什么时候做”。(在满足时钟周期约束下,合理安排运算顺序) |
| Data Path Allocation(数据通路分配) | 根据调度结果,分配硬件资源(加法器、乘法器、寄存器)。 | 决定 “用什么做”。(是用 1 个加法器串行算,还是用 4 个加法器并行算?) |
7.3.1 行为级表示(Behavioural Representation)
-
数据流程图(DFG, Data Flow Graph):
-
是架构综合的输入。
-
由操作节点(如
-
例子:
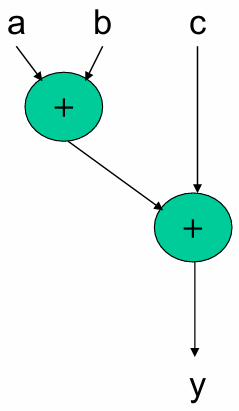
-
7.3.2 操作规划(Operation Scheduling)
任务是在一定的约束条件下将数据流图的操作节点分配给控制步骤(或时钟周期),并遵守优先级约束。约束可以是:
- 硬件资源
- 操作速度(时钟周期数) 高层次综合可以:
- 在速度限制下优化硬件资源
- 在硬件限制下优化速度
7.3.2.1 操作调度算法(Scheduling Algorithms)
调度是 HLS 的核心,算法决定了资源与速度的平衡。
| 算法 | 全称 | 核心思想 | 特点 |
|---|---|---|---|
| ASAP | As Soon As Possible | 尽可能早执行。 | 基于前驱约束,最早分配,倾向于并行,面积开销大。 |
| ALAP | As Late As Possible | 尽可能晚执行。 | 基于后继约束,最晚分配,倾向于串行,资源占用小。 |
| List Scheduling | 列表调度 | 按优先级列表依次分配。 | 实用、高效,是工业界常用的启发式算法。 |
| Force Directed | 力导向调度 | 考虑资源冲突与延迟的综合权衡。 | 平衡资源利用率与延迟,优化效果优于 ASAP/ALAP。 |
| ILP Scheduling | Integer Linear Programming | 数学建模求最优解。 | 全局最优,但计算复杂度极高,不适用于大设计。 |
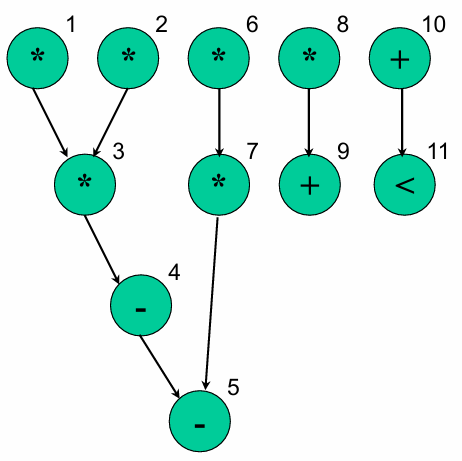
给出一个数据流图的例子:
-
ASAP(As Soon As Possible,尽可能快调度)
在满足数据依赖的前提下,每个操作尽量安排在最早的时钟周期执行。
结果特征:
- 总执行时间最短(仅需 4 个时钟周期)。
- 资源占用:4 个乘法器、1 个加法器、1 个减法器、1 个比较器(资源需求高)。
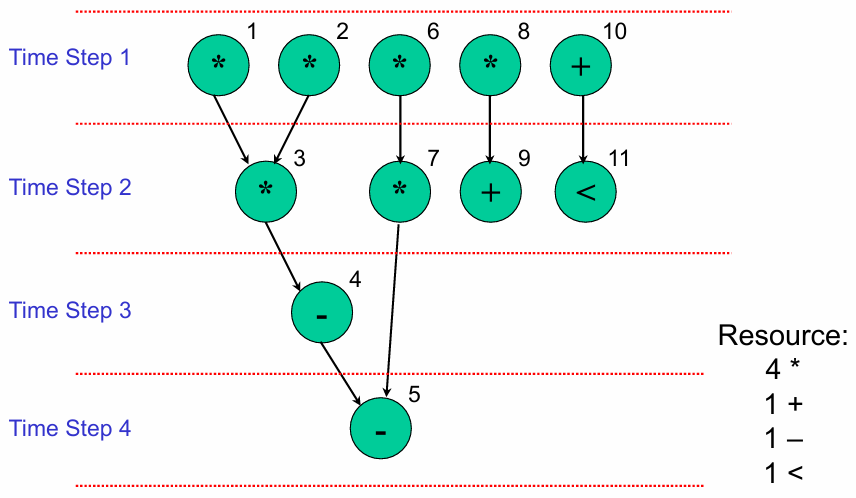
-
ALAP(As Late As Possible,尽可能慢调度)
从最终输出时刻倒推,在满足时序约束和数据依赖的前提下,每个操作尽量推到最晚的时钟周期执行。
结果特征:
- 总执行时间与 ASAP 一致(4 个时钟周期),但操作的时间分布更 “靠后”。
- 资源占用:2 个乘法器、1 个加法器、1 个减法器、1 个比较器(资源需求显著降低,实现了资源共享)。
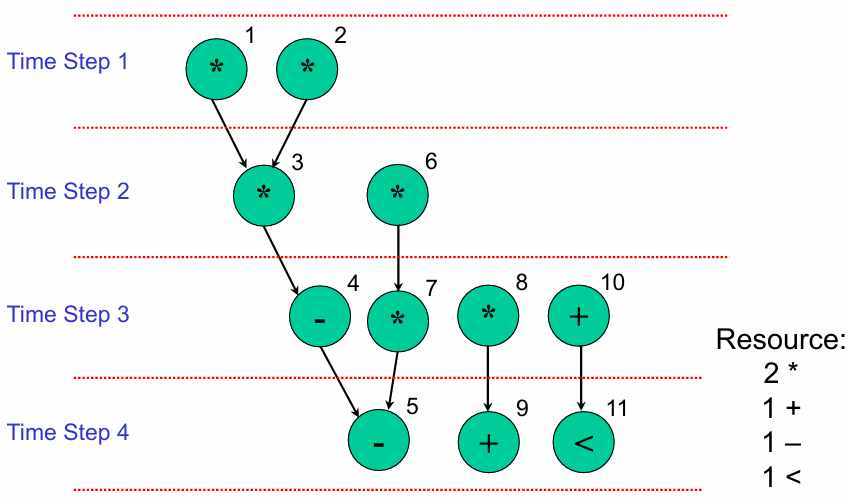
-
List Scheduling(列表调度)
给每个操作设定优先级(如关键度、操作数就绪时间),按优先级从高到低,依次将操作放入空闲的时钟周期,同时受资源约束。
结果特征:
-
总执行时间最长(需 5 个时钟周期)。
-
资源占用:2 个乘法器、1 个通用 ALU(复用
+/-/<运算),资源利用最均衡。
-
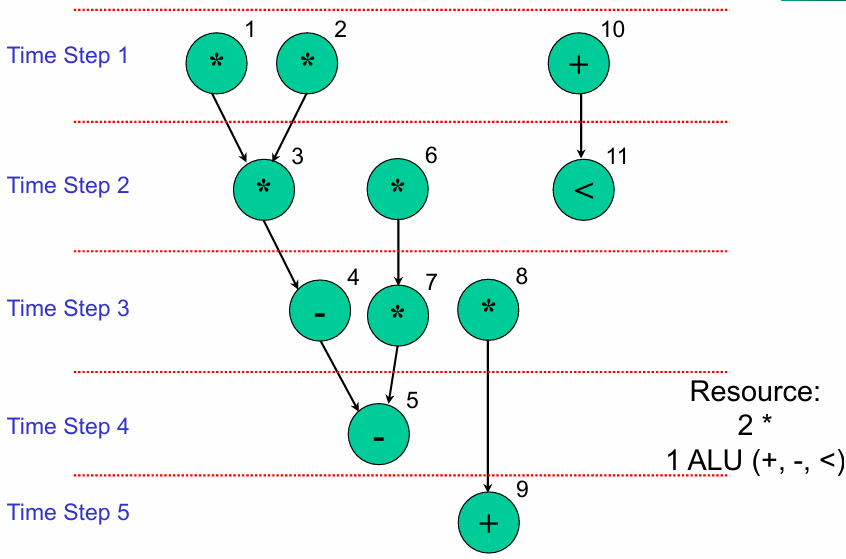
7.3.3 数据路径分配
这是 HLS 中调度之后的关键步骤,任务是将 “虚” 的数据流映射为 “实” 的硬件电路。
-
核心任务:
-
寄存器分配(Register Allocation):将数据流边(中间值)分配给具体的存储单元(寄存器)。
-
模块分配(Module Allocation):将调度好的操作(加、减、乘等)分配给具体的功能单元(ALU、乘法器)。
-
互连分配(Interconnect Allocation):设计寄存器 / 功能单元之间的连接线路(多路选择器 Mux、连线)。
-
7.3.3.1 寄存器分配算法
必须存储中间值以供下一步操作。寄存器分配的任务是将值分配给寄存器,旨在最大限度地减少寄存器和互连的数量。不同时期存在的值可以共享单个寄存器。众所周知寄存器分配算法包括左边缘算法和派分区技术。
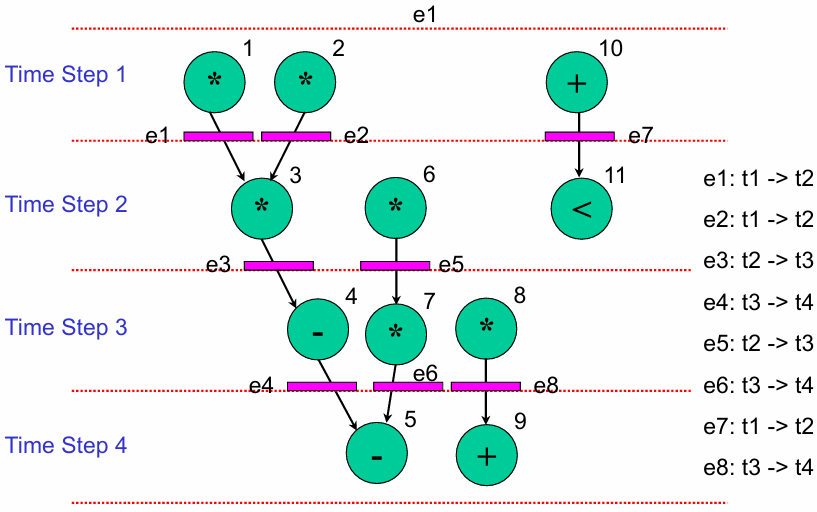
接下来重点讲解一下左边缘算法:
左边缘算法(Left-Edge Algorithm)是按数据生命周期的"左边缘"(起始时刻)排序,依次分配寄存器,优先给新起始的生命周期找已有的空闲寄存器,找不到则新建寄存器。
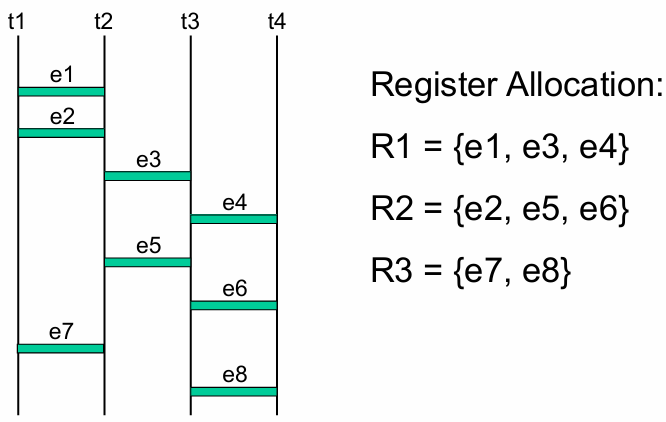
分配过程(按左边缘从早到晚排序:
- 分配
- 分配
- 分配
- 分配
- 分配
- 分配
- 分配
- 分配
最终分配结果:
-
-
-
Register Allocation Comparison
| 寄存器 | 绑定的数据流边(Data Path 1) | 绑定的数据流边(Data Path 2) |
|---|---|---|
|
|
{e0, e1, e2} | {e0, e2, e5} |
| r1 | {e3, e5, e6} | {e3} |
| r2 | {e4} | {e1, e4, e6} |
| r3 | {e7} | {e7} |
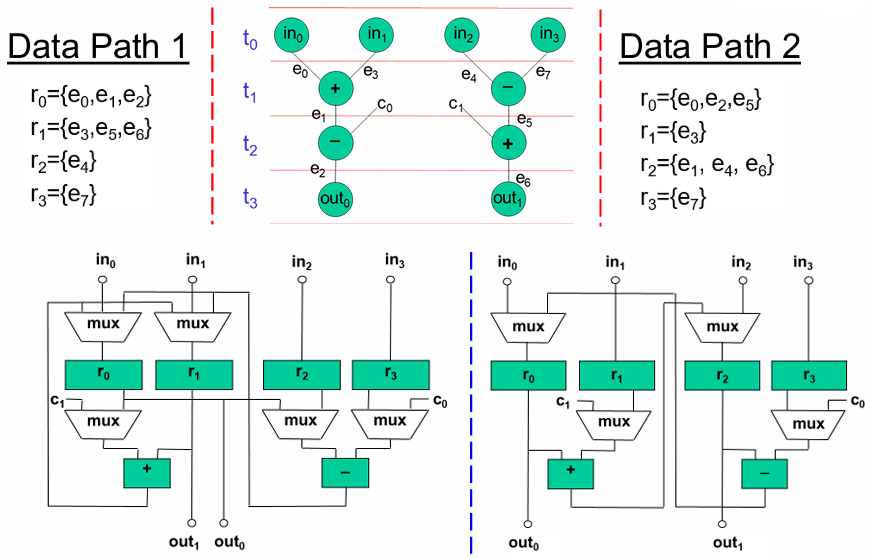
7.3.4 模块分配(Module Allocation)
Module Allocation(模块分配) 是将数据流图(DFG)中的抽象操作(如
模块的数量在调度(Scheduling)阶段就已经确定(受限于资源约束和时序目标)。
- 寄存器决定了数据什么时候送到哪里。
- 模块决定了数据在什么时候进行什么运算。
不同的绑定策略会导致不同的互连结构(多路选择器 Mux、总线、连线数量),这直接决定了芯片面积和布线复杂度。
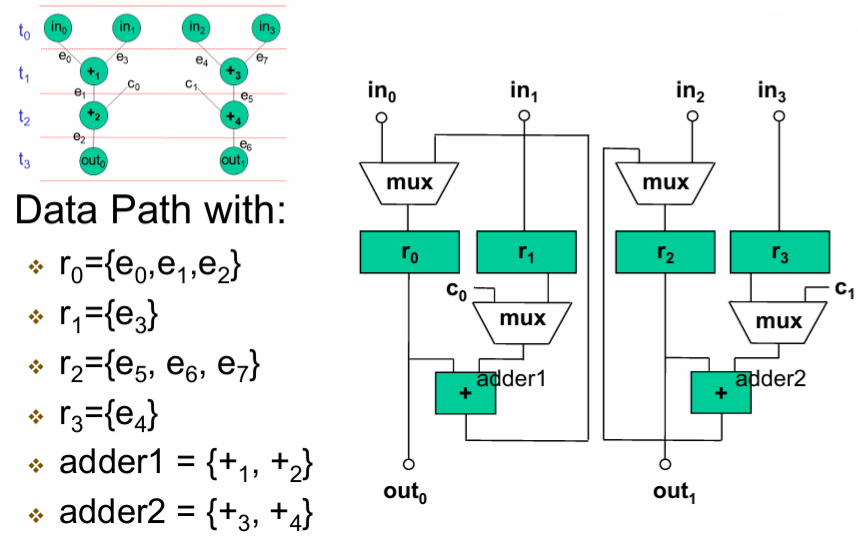
7.3.5 互连分配(Interconnect Allocation)
互连分配是 HLS 的最后一步硬件映射,负责设计寄存器、功能模块、I/O 端口之间的连接网络,直接决定芯片的布线复杂度、时序收敛难度和最终面积。
- 影响因素:
- 寄存器分配:决定了中间数据的存储位置,是互连的起点
- 模块分配:决定了运算单元的位置,是互连的终点
- 架构连接风格:决定了互连的拓扑结构
| 连接风格 | 实现方式 | 优点 | 缺点 |
|---|---|---|---|
| 点对点(Point-to-Point) | 寄存器与功能单元直接用连线和多路选择器(Mux)连接 | 延迟低、控制简单、时序收敛容易 | 连线数量多、布线拥塞、面积大 |
| 总线(Bus) | 所有连接汇总到共享总线,分时复用 | 连线数量少、布线简单、面积小 | 延迟高、存在总线冲突风险、控制复杂 |
| 混合风格(Mixture of the above two styles) | 关键路径用点对点,非关键路径用总线 | 平衡延迟与面积,兼顾性能与成本 | 控制逻辑复杂,设计难度高 |
8 测试(Testing)
芯片设计正确,不代表流片制造出的电路能正常工作,测试的核心目标是筛选制造缺陷件,从源头降低全流程成本。
关键要点:
- 制造缺陷来源:硅晶体杂质、光刻对准偏差、刻蚀精度不足等工艺问题,会导致电路开路、短路、性能退化等故障。
- 额外风险:可靠性应力测试(高低温、高压测试)可能引入新的故障。
- 成本铁则:故障发现越晚,修复成本呈指数级上升(行业经典1:10:100 法则:组件级发现故障成本为 1,板级为 10,系统级为 100),因此必须在制造后尽早测试。
8.1缺陷水平(Defect Level)
产品质量的核心量化指标,指每百万件产品中的缺陷件数(parts per million, ppm),用于衡量制造良率。
例如生产 100,000 个元件时有 10 个有缺陷的元件,则缺陷水平为 0.01% 或 100ppm。
8.2 可测试性设计(Design For Testability, DFT)
- 设计阶段:可无限制访问电路所有节点,随意观测内部状态。
- 流片后:复杂电路(如 CPU,含数百万晶体管、海量状态)无法直接访问内部节点,无法完成测试。
DFT 是芯片设计的必备环节:在 RTL 设计阶段,就加入扫描链、边界扫描、内建自测试(BIST)等测试结构,让制造后的电路具备可测试性,直接影响芯片的可制造性和良率。
8.3 测试分类(Test Categories)
量产测试按目标分为三类,各有明确分工:
| 测试类型 | 核心目标 | 复杂度 | 应用场景 |
|---|---|---|---|
| 诊断测试 | 识别并定位故障的具体位置 | 高 | 失效分析、良率提升、工艺优化 |
| 功能测试(go/no-go) | 仅判断芯片是否正常工作(合格 / 不合格) | 低 | 量产筛选,是量产测试的核心环节 |
| 参数测试 | 验证非离散性能参数(延迟、频率、噪声裕量等) | 中 | 性能验证、可靠性测试(高低温 / 电压环境下) |
量产测试通常按"参数测试→功能测试→诊断测试(仅失效件)"的顺序执行。
8.4 测试核心挑战(Testing Issues)
核心目标是减少测试时间
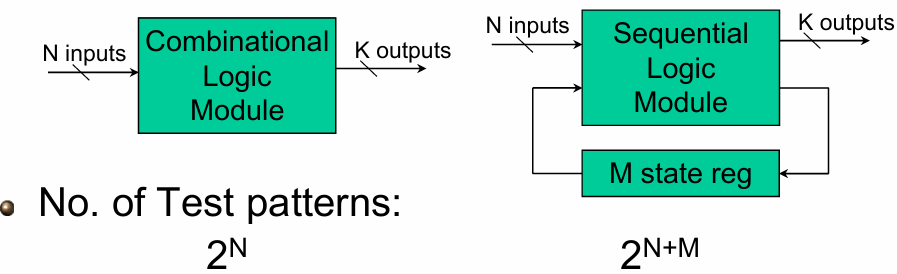
穷举测试完全不可行:
- 组合逻辑:N 个输入需要
- 时序逻辑:N 个输入 + M 个状态寄存器,需要
解决方案就是在设计阶段提前考虑测试(DFT),通过自动测试向量生成(ATPG)等技术,用最少的测试向量覆盖最多的故障。
8.5 测试方法的优化原则(Testing Approach Premises)
穷举测试存在大量冗余:单个故障会被多个测试向量覆盖,因此可以通过故障覆盖率权衡降低测试成本。
检测最后 1% 的故障,需要的测试向量数量远高于前 99%,测试成本呈指数级上升。
量产测试通常仅追求95-99% 的故障覆盖率,平衡测试成本与良率损失(替换坏件的成本远低于额外测试的成本)。
优化指标主要有下面两个:
-
可控制性(Controllability)
可控制性衡量仅通过电路的输入引脚,将内部某一节点设置为指定逻辑状态(0/1)的难易程度。
- 高可控制性(理想状态):仅需单个输入向量,就能将节点设置为任意目标状态(0 或 1),测试难度极低。
- 低可控制性(差状态):需要长序列的输入向量,才能将节点设置为目标状态,测试时间长、难度高。
高可控制性是可测试电路的必备要求,直接决定测试向量生成的复杂度和测试时间。
-
可观测性(Observability)
可观测性衡量仅通过电路的输出引脚,观测内部某一节点当前逻辑状态的难易程度。
- 高可观测性(理想状态):节点状态可直接在输出引脚观测到,无需额外运算或等待,测试难度极低。
- 低可观测性(差状态):节点状态需要经过多个时钟周期的运算 / 传递,才能出现在输出端,观测难度高、测试时间长。
高可观测性是可测试电路的另一核心要求,与可控制性共同决定电路的可测试性。
8.5.1 扫描链测试(Scan-Based Test)
为解决时序电路测试难度爆炸的问题,将所有寄存器改造为可外部加载 / 读取的扫描寄存器,串联成一条移位寄存器链(扫描链),把时序电路的测试转化为组合逻辑测试。
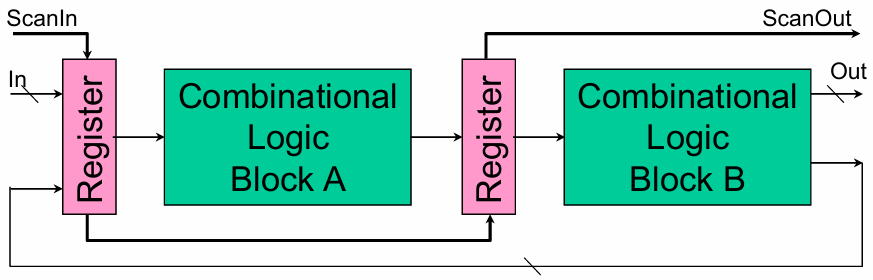
- 可控制性:通过
ScanIn将测试向量移位写入寄存器,直接控制内部节点状态。 - 可观测性:通过
ScanOut将运算结果从寄存器移位读出,直接观测内部节点状态。
测试流程(Scan-based Test Procedure)如下:
- 移位输入(Shift-in):通过
ScanIn引脚,在测试时钟控制下,将测试向量串行移位写入所有扫描寄存器。 - 系统时钟捕获(Capture):发出 1 个系统时钟,让寄存器中的测试向量驱动组合逻辑运算,结果锁存回寄存器。
- 移位输出(Shift-out):通过
ScanOut引脚,将寄存器中的结果串行移位读出,与预期值对比,判断电路是否存在故障。
以 4 位串行扫描链寄存器为例:
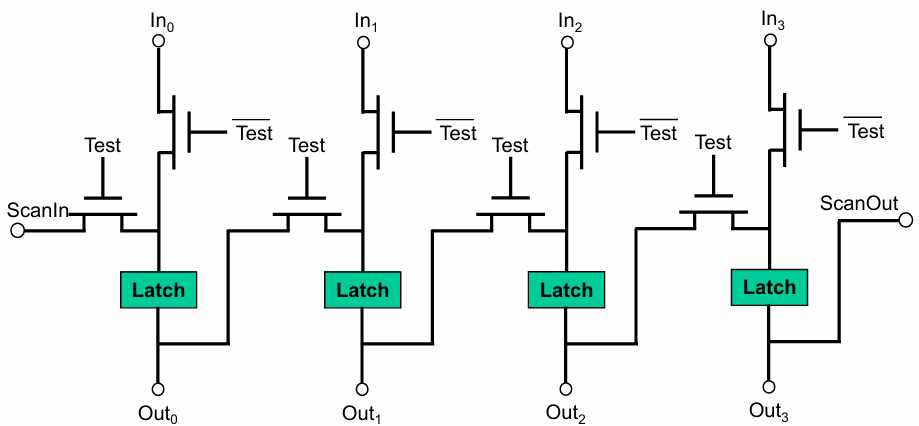
在普通寄存器前加入二选一多路选择器(MUX),由Test信号控制工作模式:
- 正常模式(Test=0):选择
In输入,寄存器正常工作,不影响电路功能。 - 扫描模式(Test=1):选择
ScanIn输入,寄存器串联成移位链,实现测试向量的移位读写。
8.5.2 边界扫描测试(Boundary-Scan Test)
在芯片的所有 I/O 引脚处添加边界扫描单元(BST Cell),将所有单元串联成一条边界扫描链,实现芯片引脚级的可控制性和可观测性。
- 解决 PCB 板级芯片间互连开路 / 短路测试难题,同时支持芯片内部功能测试。
标准 BST 接口使用 4 根线,大幅降低测试成本:
| 信号 | 全称 | 功能 |
|---|---|---|
| TDI | Test Data Input | 测试数据串行输入到扫描链 |
| TDO | Test Data Output | 测试数据从扫描链串行输出 |
| TCK | Test Clock | 测试时钟,同步所有扫描操作 |
| TMS | Test Mode Select | 测试模式选择,控制 TAP 状态机,切换工作模式 |
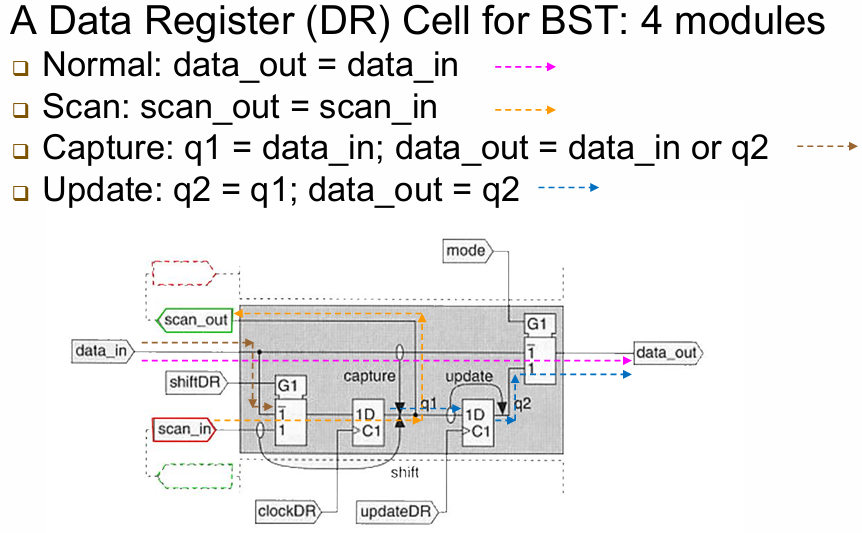
8.5.2.1 BST 单元(BST Cell)与核心功能
每个 I/O 引脚对应一个 BST 单元,包含 4 个工作模式:
- Normal(正常模式):
data_out = data_in,完全透明,不影响电路正常工作。 - Scan(扫描模式):
scan_out = scan_in,单元串联成移位链,实现测试向量的移位读写。 - Capture(捕获模式):锁存引脚当前状态,用于观测引脚互连状态。
- Update(更新模式):将扫描链中的测试向量加载到引脚,用于控制引脚状态。
核心功能:
- Capture(并行捕获):并行捕获所有引脚状态到 BST 单元。
- Shift(串行移位):串行移入测试向量,同时串行移出捕获的结果。
- Update(并行更新):将测试向量并行加载到引脚,驱动电路测试。
- Internal Test(内部测试):测试芯片内部逻辑功能。
- External Test(外部测试):测试 PCB 板级芯片间的互连(开路 / 短路)。
8.5.3 内建自测试(Built-In Self-Test, BIST)
在芯片内部集成完整的测试电路,让芯片无需外部测试机,即可自主完成自我测试,大幅降低量产测试成本,提升测试效率。
BIST核心模块如下图所示:
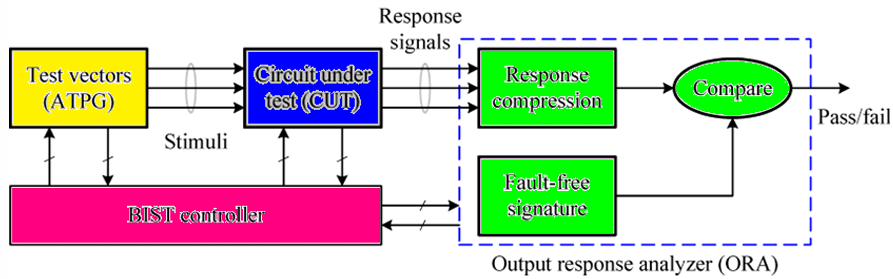
| 模块 | 功能 |
|---|---|
| Test Vectors Generator (TPG/ATPG) | 自动生成测试向量(通常用线性反馈移位寄存器 LFSR 生成伪随机向量),替代外部测试机的向量输入。 |
| Circuit Under Test (CUT) | 被测电路,即芯片的核心功能逻辑。 |
| Output Response Analyzer (ORA) | 对 CUT 的输出响应进行压缩(如多输入特征寄存器 MISR),生成特征签名(Signature),与无故障电路的预期签名对比。 |
| BIST Controller | 控制整个 BIST 流程,协调 TPG、CUT、ORA 的工作,输出最终的Pass/Fail结果。 |
优点:
- 无需外部测试机:芯片上电后可自主完成测试,适合量产、板级测试、系统级测试。
- 测试速度快:内部测试时钟远高于外部测试机,大幅缩短测试时间。
- 可在线测试:支持芯片工作过程中的在线自检,提升系统可靠性。
8.6 故障模型(Fault Models)
芯片制造会产生各类物理缺陷,但直接用物理缺陷做测试不现实,因此需要故障模型:将实际物理缺陷抽象为电路逻辑层面的故障,让测试生成、仿真、验证可落地。
- 信号间短路(signal short-circuits)
- 信号与电源 / 地轨短路(short to supply rails)
- 浮空节点(floating nodes,节点无驱动,电平不确定)
我们一般使用固定型故障模型(Stuck-At Model),这是最主流、最通用的故障模型,仅聚焦节点与电源 / 地短路的场景:
- SA0(Stuck-At-Zero,固定 0 故障):节点永远被钳位在逻辑 0,无法输出 1
- SA1(Stuck-At-One,固定 1 故障):节点永远被钳位在逻辑 1,无法输出 0
8.7 IDDQ 测试(IDDQ Test)
基于 CMOS 电路的静态特性:正常 CMOS 电路在静态(无开关动作)时,
测试逻辑:
- ✅ 好芯片:IDDQ 远低于阈值(通常 μA~nA 级)
- ❌ 坏芯片:IDDQ 超过阈值( >几 mA),直接判定失效
- 工程价值:无需复杂测试向量,仅测电源电流即可快速筛除坏片,是量产测试的快速预筛手段,和功能测试形成互补。
8.8 故障仿真(Fault Simulation)
评估测试程序的质量,计算故障覆盖率(Fault Coverage):
故障覆盖率 =
这是衡量测试有效性的核心指标,量产芯片的行业要求通常
。
仿真流程:
- 在电路中插入一个目标故障(如某节点 SA0)
- 用现有测试向量对「故障电路」和「无故障电路」分别仿真
- 对比输出结果:
- ✅ 输出不同 → 故障被该测试向量检测到
- ❌ 输出相同 → 故障未被检测到
- 遍历所有故障,统计故障覆盖率,迭代优化测试向量。
8.8.1 测试向量(Test Pattern/Test Vector)
输入到电路的一组逻辑值,用于激活并检测电路中的一个或多个故障。
核心逻辑:
- 故障覆盖率越高,需要的测试向量越多;
- 穷举测试(遍历所有输入组合)完全不可行:N 输入的组合逻辑需要
- 工程原则:通过 ATPG 生成最优测试向量集,用最少的向量达到 95-99% 的故障覆盖率,平衡测试成本和产品质量。
测试概念实例:与门(AND Gate)测试
用 2 输入与门直观解释固定型故障的测试逻辑,核心思想是:激活故障,让故障在输出端产生可观测的差异。
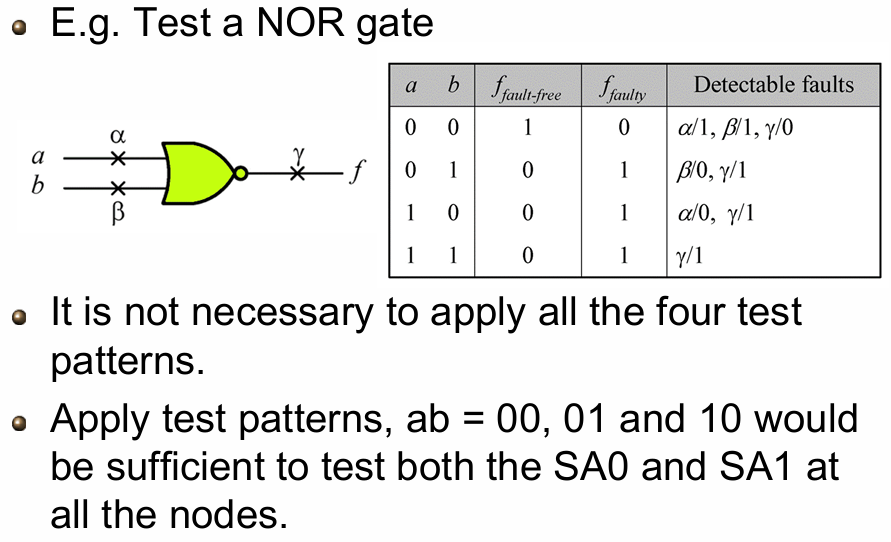
自动测试向量生成
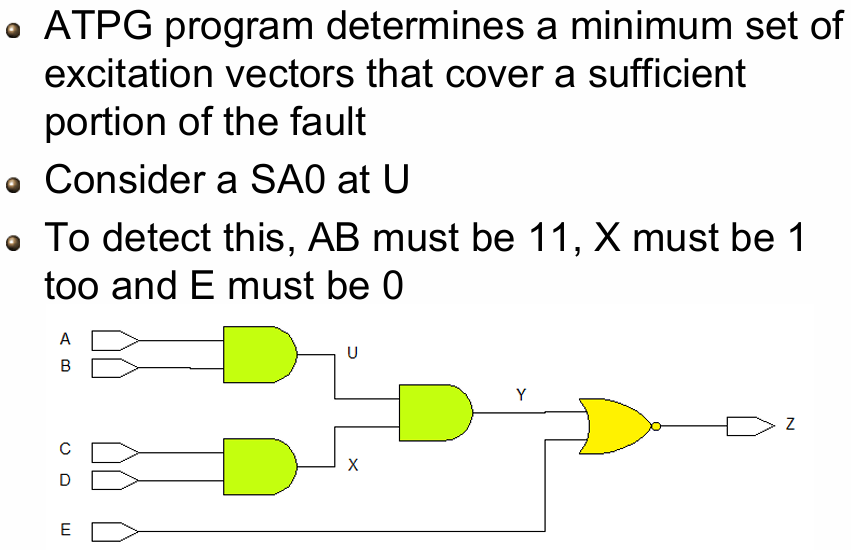
8.8.2 D Algorithm For ATPG
D 算法引入了复合逻辑值 D(g/b,good/bad),同时表示无故障电路(good)和故障电路(bad)的节点状态,用于直观体现故障的差异:
-
-
- 普通逻辑值:0=0/0,1=1/1(无故障 / 故障状态一致,无差异)
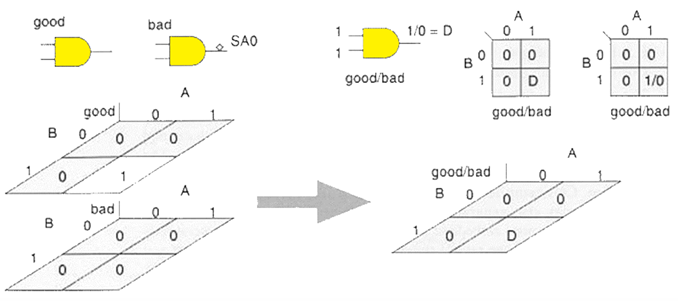
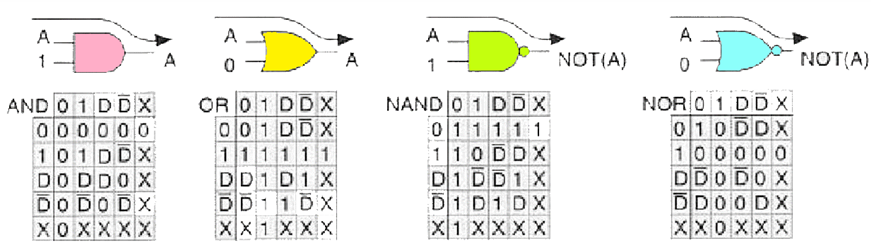
完整 D 值真值表如下:
D 算法完整流程
以 NAND 门电路中某节点 SA1(固定 1 故障) 为例,完整演示 D 算法的 4 个核心步骤:
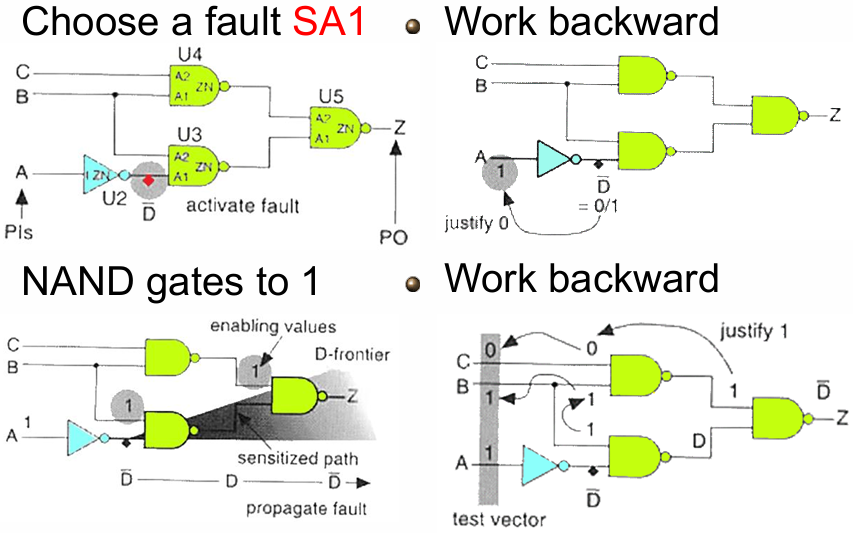
step 1: 激活故障(Fault Activation)
- 目标:让故障节点在无故障电路中为 0,故障电路中为 1,产生
- 操作:给故障节点施加输入,使无故障状态为 0(SA1 故障会强制节点为 1,形成 0/1 的
- 实例:图中 U3 的输入节点,无故障时为 0,SA1 故障强制为 1,产生
step 2: 敏化路径(Path Sensitization)
- 目标:从故障节点到原始输出(PO)建立一条敏化路径,让
- 操作:为路径上的所有门电路设置使能值,保证
- 实例:
- 路径:故障节点
- 使能值设置:将 U4、U3 的其他输入设为 1(NAND 门的使能值为 1),让
- 路径:故障节点
step 3: 反向证明(Justification/Backward Working)
- 目标:从敏化路径的使能值出发,反向推导电路的原始输入(PI),验证这些使能值可以通过输入实现,无冲突
- 操作:从输出端反向推导,为每个门的输入赋值,最终得到原始输入 A/B/C 的取值
- 实例:
- 反向推导 U5、U4、U3、U2 的输入要求,最终得到原始输入:
A=1, B=1, C=0 - 验证:该输入可以满足所有使能值要求,无逻辑冲突。
- 反向推导 U5、U4、U3、U2 的输入要求,最终得到原始输入:
step 4:生成测试向量
- 最终得到的原始输入
A=1, B=1, C=0,就是可检测该 SA1 故障的测试向量。 - 验证:用该向量分别仿真无故障电路和故障电路,输出 Z 的差异可观测,证明向量有效。




